Alignment with human preferences
This week: Evaluation, measurement, span annotation, openai evolves, hegemons
Rankers, Judges, and Assistants: Towards Understanding the Interplay of LLMs in Information Retrieval Evaluation
Aren’t human preferences central to the process?
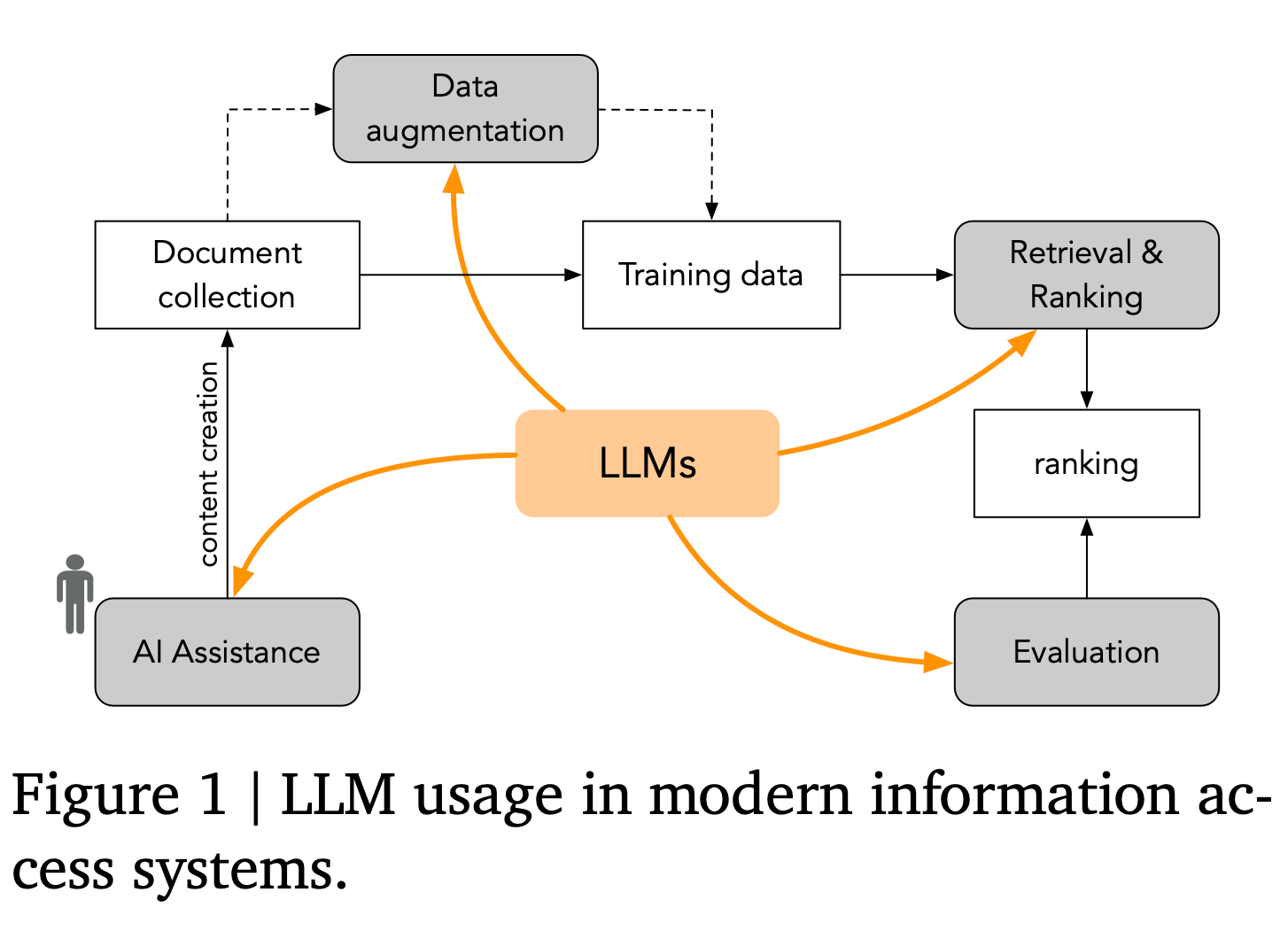
“We outline several key considerations for em- ploying LLMs in evaluation, aiming to foster a community-wide set of best practices and ensure methodological soundness. These are not exhaustive, but represent an important starting point.”
“Consistent Evaluation Across Systems. All systems being compared within a single evaluation should be assessed using the same LLM judge configuration (model, prompt, settings). This ensures a fair and unbiased comparison, avoiding situations where some systems are evaluated with a more lenient or biased judge than others. Specifically, LLM judges should not be used selectively to fill “relevance holes” in existing human judgments [1].”
“Transparency and Reproducibility. To enable reproducibility and facilitate comparisons across studies, researchers should clearly report the specific LLM used (model version), the exact prompt(s) employed, and any relevant settings or parameters.”
”Employing Multiple LLMs as Judges. Using a combination of different LLM judges can help mitigate biases stemming from LLMs favoring responses from their own model family and improve robustness (see, e.g., [18]). Reporting the distribution of scores across different judges, as suggested by Rahmani et al. [43], can further enhance robustness.
“Alignment with Human Preferences. Ensuring alignment between human and LLM raters is a substantial effort that needs to be continuously monitored and refined [54]. Ideally, results reported on LLM judges should also include human validation of the results on a representative sample. Researchers should also exercise care when making research claims based on results from LLM judges.”
Balog, K., Metzler, D., & Qin, Z. (2025). Rankers, Judges, and Assistants: Towards Understanding the Interplay of LLMs in Information Retrieval Evaluation. arXiv preprint arXiv:2503.19092.
https://arxiv.org/abs/2503.19092v1
Evaluating Generative AI Systems is a Social Science Measurement Challenge
Aren’t social preferences central to the process?
“The framework distinguishes between four levels: the background concept, the systematized concept, the measurement instrument(s), and the instance-level measurements themselves. This four-level approach differs from the way measurement is typically done in ML, where researchers and practitioners appear to jump straight from background concepts to measurement instruments, with little to no explicit systematization in between.”
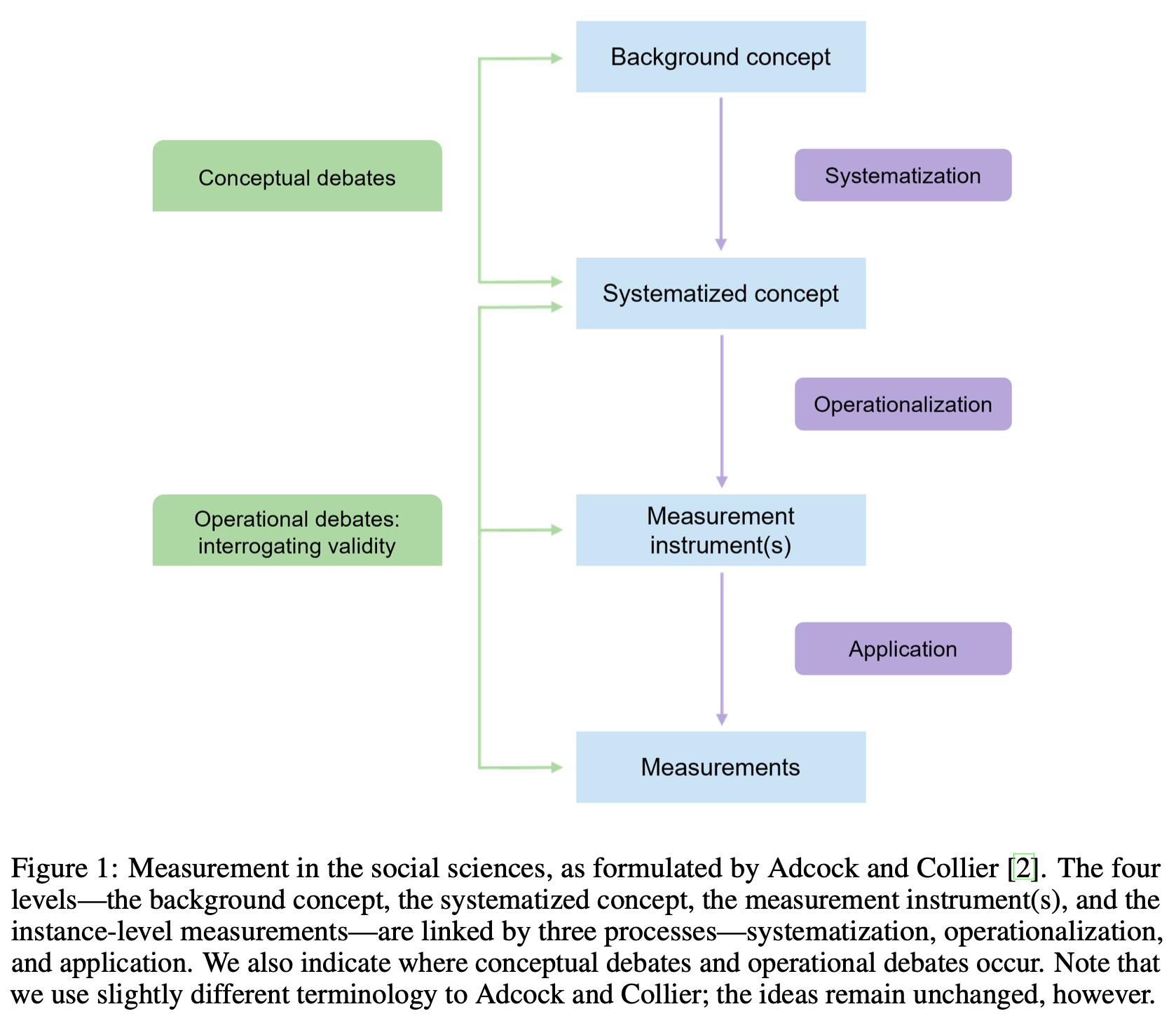
“When measuring complex and contested concepts, social scientists often turn to measurement theory, which offers a framework for articulating distinctions between concepts and their operationalizations via measurement instruments—i.e., the procedures and artifacts used to obtain measurements of those concepts, such as classifiers, annotation guidelines, scoring rules—and a set of lenses for interrogating the validity of measurement instruments and their resulting measurements [e.g., 2, 12, 17].”
”Without an explicitly systematized concept, it is hard to know exactly what is being operationalized, and thus measured.”
“Rather, we advocate for adopting the framework that social scientists often turn to for measurement; we do not advocate for naïvely transferring measurement instruments designed for humans (e.g., competency tests) to the context of GenAI systems.”
Wallach, H., Desai, M., Pangakis, N., Cooper, A. F., Wang, A., Barocas, S., ... & Jacobs, A. Z. (2024). Evaluating Generative AI Systems is a Social Science Measurement Challenge. arXiv preprint arXiv:2411.10939.
https://arxiv.org/abs/2411.10939
Large Language Models as Span Annotators
Aren’t a group’s categorical preferences central to the process?
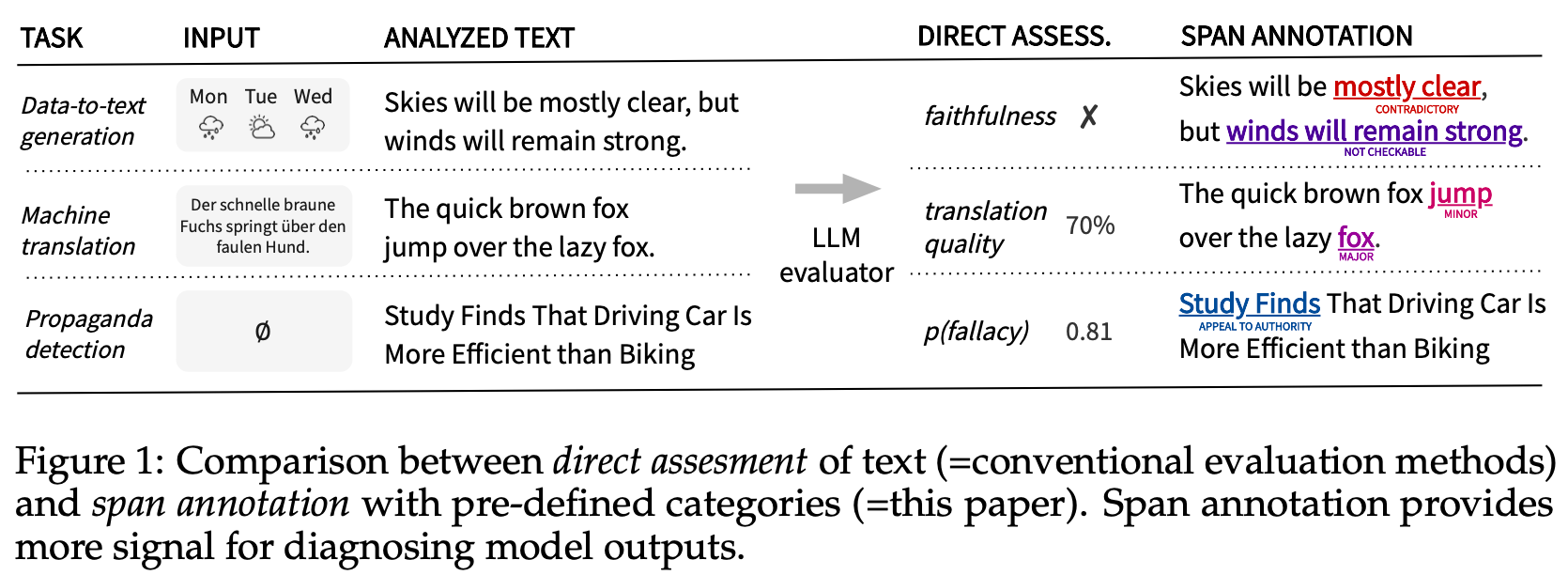
“The subject of our study, span annotation, offers an alternative approach. Figure 1 shows the difference between direct assessment and span annotation. Instead of assigning a single score for each evaluated aspect, the goal of span annotation is to localize text spans and classify them into predefined categories. In contrast to numerical rating, annotations are aligned to the evaluated text, which makes them more explainable and actionable. The annotations can also be examined post hoc, enabling a more modular evaluation process.”
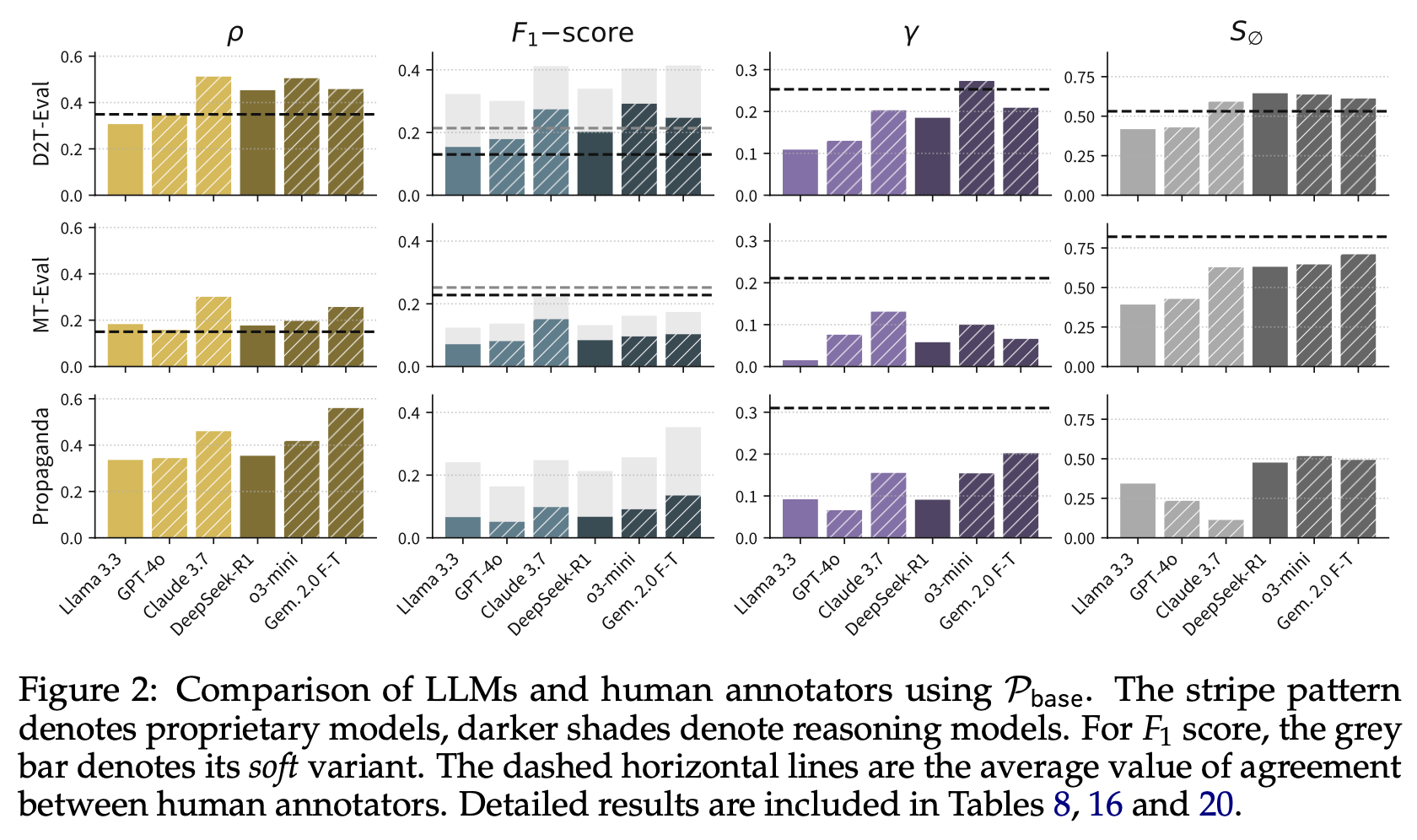
“Performance is task-dependent. LLMs provide annotations that are aligned with human annotations to a degree, with exact agreement depending on the task. For D2T-EVAL, all models surpass the average F1-scores (both soft and hard) between human annotators (0.13 and 0.21, respectively), although only o3-mini surpasses the γ score (0.25). Performance is notably lower for PROPAGANDA, where all models remain below the γ agreement of human annotators. It should be noted that expert annotators were used in this task, which can make it more difficult for the models to reach their agreement level. This task also has the largest number of categories, manifested by a large increase in the soft F1-score as opposed to its hard variant. On average, the models are also below human performance for MT-EVAL, with Claude 3.7 showing the best results (0.22 F1-score vs. 0.25 of human annotators).”
“Reasoning models outperform instruction-tuned models. DeepSeek-R1, which is a reasoning model, outperforms the same-sized instruction-tuned Llama 3.3. The superiority of DeepSeek-R1 is most pronounced on D2T-EVAL (F1-score of 0.19 vs. 0.15, γ score of 0.19 vs. 0.11). We hypothesize that this is because statements in texts generated from structured data often involve numerical reasoning. The same observation applies to OpenAI models, where o3-mini outperforms GPT-4o despite o3-mini’s price per token being approximately 2x lower. Both findings demonstrate the potential of test-time scaling (Snell et al., 2024; Welleck et al., 2024). A notable exception from this trend is Claude 3.7 Sonnet, which is mostly on par with o3-mini (although its price per token is approximately 3x higher).”
“Models mostly confuse related categories. The results of category classification on D2T- EVAL suggest that the models mostly tend to confuse annotation categories such as Contra- dictory, Not checkable and Misleading that are all related to semantic accuracy (cf. Figure 3 and Appendix G.8). This suggests that categorization errors may be less serious and may be related to category ambiguity or subjective understanding of category definitions. The results also show that the models use a less diverse distribution of categories, resorting to the Contradictory category more often than human annotators.”
“LLMs are more cost-efficient than human annotators. Using LLMs, as opposed to human annotators, is notably different once the financial aspect is taken into account: For D2T- EVAL, crowdsourced annotation for 1k outputs costs approximately $500, while annotating the same amount of outputs with the high-performance model o3-mini LLM costs $3.60. We provide a more detailed cost- and time-wise analysis in Appendix A.1.”
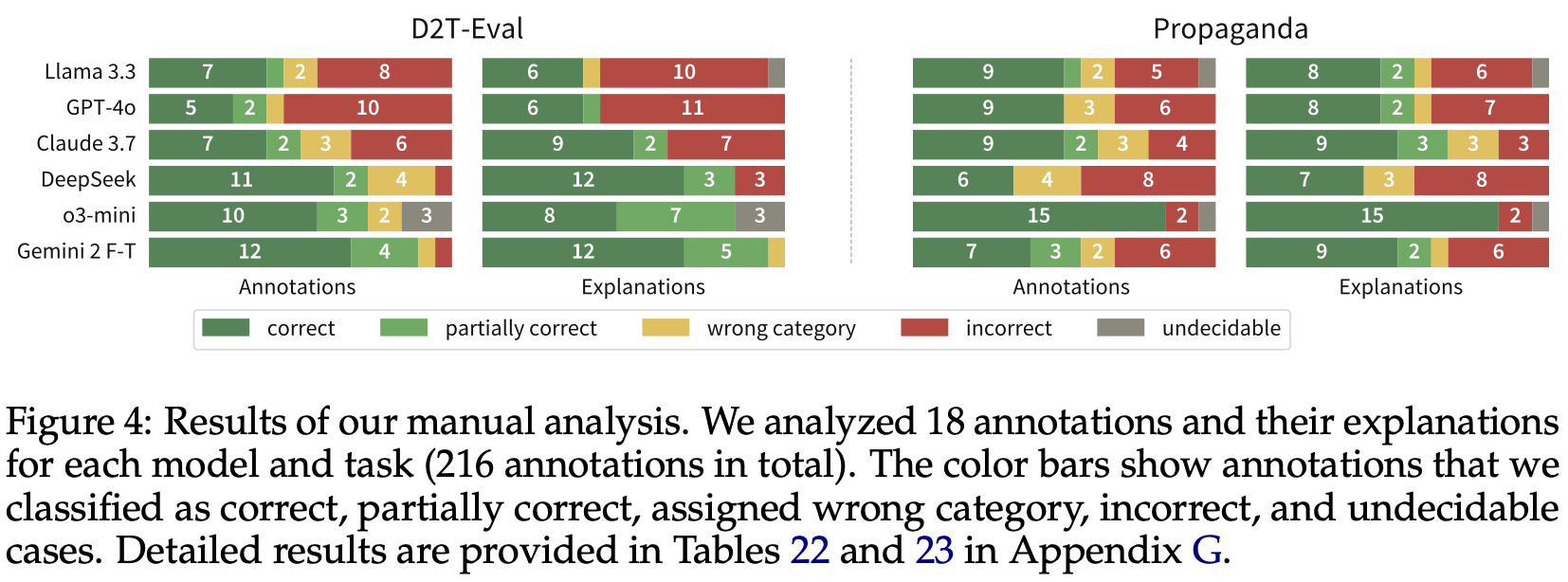
Kasner, Z., Zouhar, V., Schmidtová, P., Kartáč, I., Onderková, K., Plátek, O., ... & Balloccu, S. (2025). Large Language Models as Span Annotators. arXiv preprint arXiv:2504.08697.
https://arxiv.org/abs/2504.08697
Evolving OpenAI’s structure
Aren’t shareholders’ preferences central to the process?

“The OpenAI Board has an updated plan for evolving OpenAI’s structure.
- OpenAI was founded as a nonprofit, and is today overseen and controlled by that nonprofit. Going forward, it will continue to be overseen and controlled by that nonprofit.
- Our for-profit LLC, which has been under the nonprofit since 2019, will transition to a Public Benefit Corporation (PBC)–a purpose-driven company structure that has to consider the interests of both shareholders and the mission.
- The nonprofit will control and also be a large shareholder of the PBC, giving the nonprofit better resources to support many benefits.
- Our mission remains the same, and the PBC will have the same mission.
We made the decision for the nonprofit to retain control of OpenAI after hearing from civic leaders and engaging in constructive dialogue with the offices of the Attorney General of Delaware and the Attorney General of California. We thank both offices and we look forward to continuing these important conversations to make sure OpenAI can continue to effectively pursue its mission of ensuring AGI benefits all of humanity. Sam wrote the letter below to our employees and stakeholders about why we are so excited for this new direction.—Bret Taylor”

https://openai.com/index/evolving-our-structure/
A theory of economic coercion and fragmentation
Is AI more akin to finance or to manufacturing?

“We estimate that U.S. geoeconomic power relies on financial services, while Chinese power relies on manufacturing. Since power is nonlinear and increases disproportionally as the hegemon approaches controlling the entire supply of a sectoral input, we estimate that much economic security could be achieved with little overall fragmentation by diversifying the input sources of key sectors currently controlled by the hegemons.”
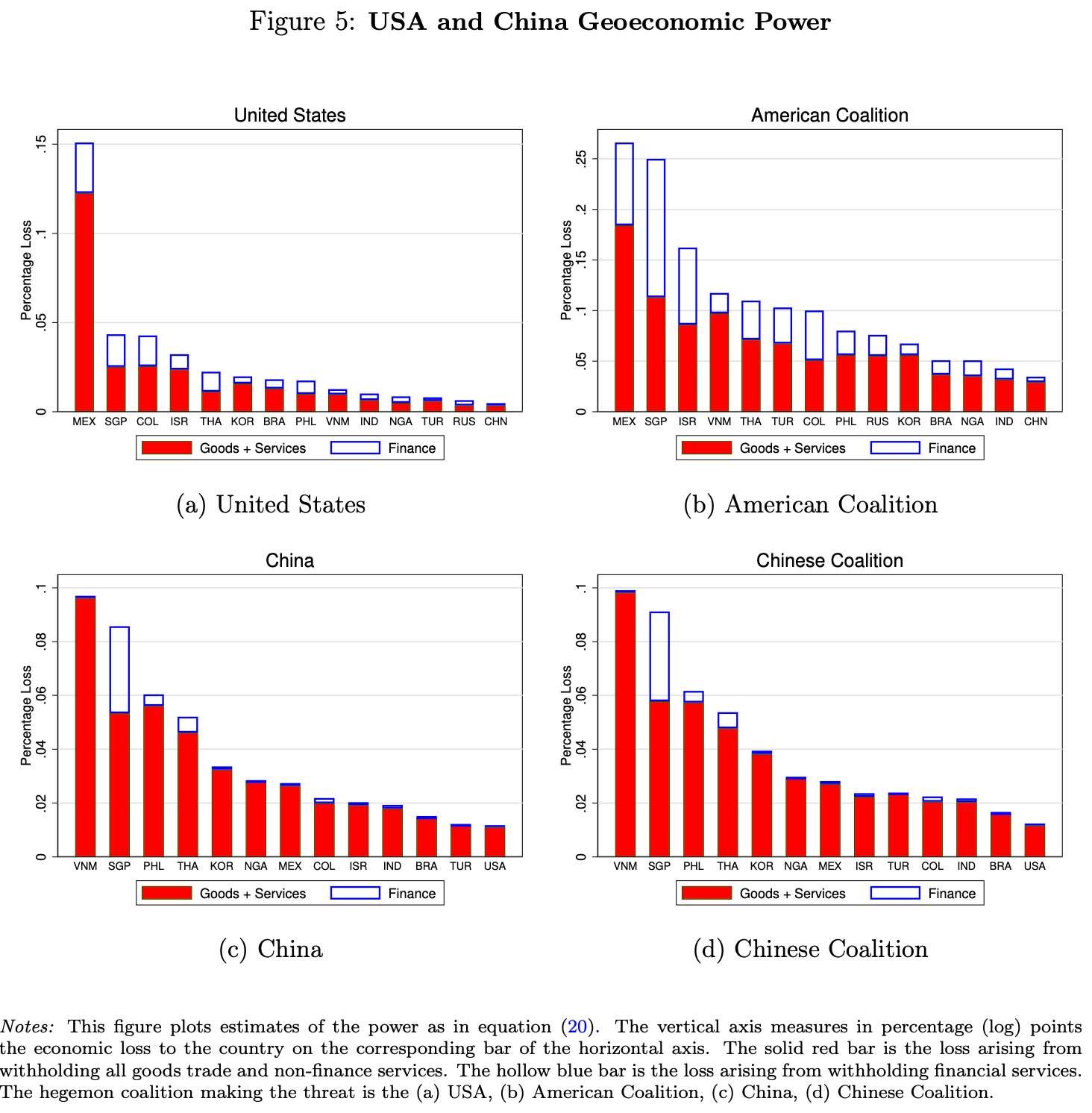
“Geoeconomic tensions have the potential to fragment the world trade and financial system, unwinding gains from international integration. Governments around the world are introducing mixes of industrial, trade, and financial policies to protect their economies from unwanted foreign influence. Collectively, these policies fall under the umbrella of Economic Security policy. We provide a model for jointly analyzing economic coercion by a hegemon and economic security policies by the rest of the world. We show that precisely those forces, like economies of scale, that are classic rationales for global integration and specialization can be used by a hegemon to increase its coercive power. Countries around the world react by implementing economic security policies that shift their domestic firms away from the hegemon’s global inputs into an inefficient home alternative. We show these uncoordinated policies results in inefficient global fragmentation as each country over-insulates its economy. We focus on financial services as an industry with strong strategic complementarities at the global level. We derive simple statistics to measure geoeconomic power and estimate that the United States and its allies derive an outsized share of their power from their dominance of global finance. We show that power is nonlinear in the share of inputs controlled by the hegemon and demonstrate how only small reductions in American control of the international financial system come with significant reductions in American power.”
Clayton, C., Maggiori, M., & Schreger, J. (2024). A theory of economic coercion and fragmentation. Bank for International Settlements, Monetary and Economic Department.
Reader Feedback
“Love the rank - now make it more concrete.”
Footnotes
Thank you for the notes.
Two fantastic people cited which LLM they fed the white paper into and one even included their prompt. One stressed why they did so (Christopher: because it’s super abstract!) And other left it unsaid. And that’s great. I’m thankful for the feedback and the meta-feedback and the meta-meta-feedback.
How do you serve people struggling to frame the problem of problems?
We tend to make agreements to not upset each other. Some of us can be … selective, choiceful, about those agreements. My opening perception was that the problem of value propositions shouldn’t cause upset. But some folk do exhibit behaviour that could be classified as indicative of upset. That’s a signal of real pain there. There’s acuity. That’s the signal.
There be dragons.
And thank you — I’m incorporating the feedback and listening to the problems. Try the current version at https://rank.gatodo.com/ and shoot me a note.
Never miss a single issue
Be the first to know. Subscribe now to get the gatodo newsletter delivered straight to your inbox