Angels and Algorithms
This week: The emerging market for intelligence, unmasking policies, reasoning, business angel groups
The Emerging Market for Intelligence: Pricing, Supply, and Demand for LLMs
Competitive!
“The supply side is characterized by rapid entry, particularly from open-source models and inference providers, and by sharp declines in intelligence-adjusted token prices. We find that large price dispersion persists even among models with similar benchmark performance; open-source models are 90% cheaper than comparable closed-source models, yet account for less than 30% of the market on average, indicating meaningful non-price differentiation.”
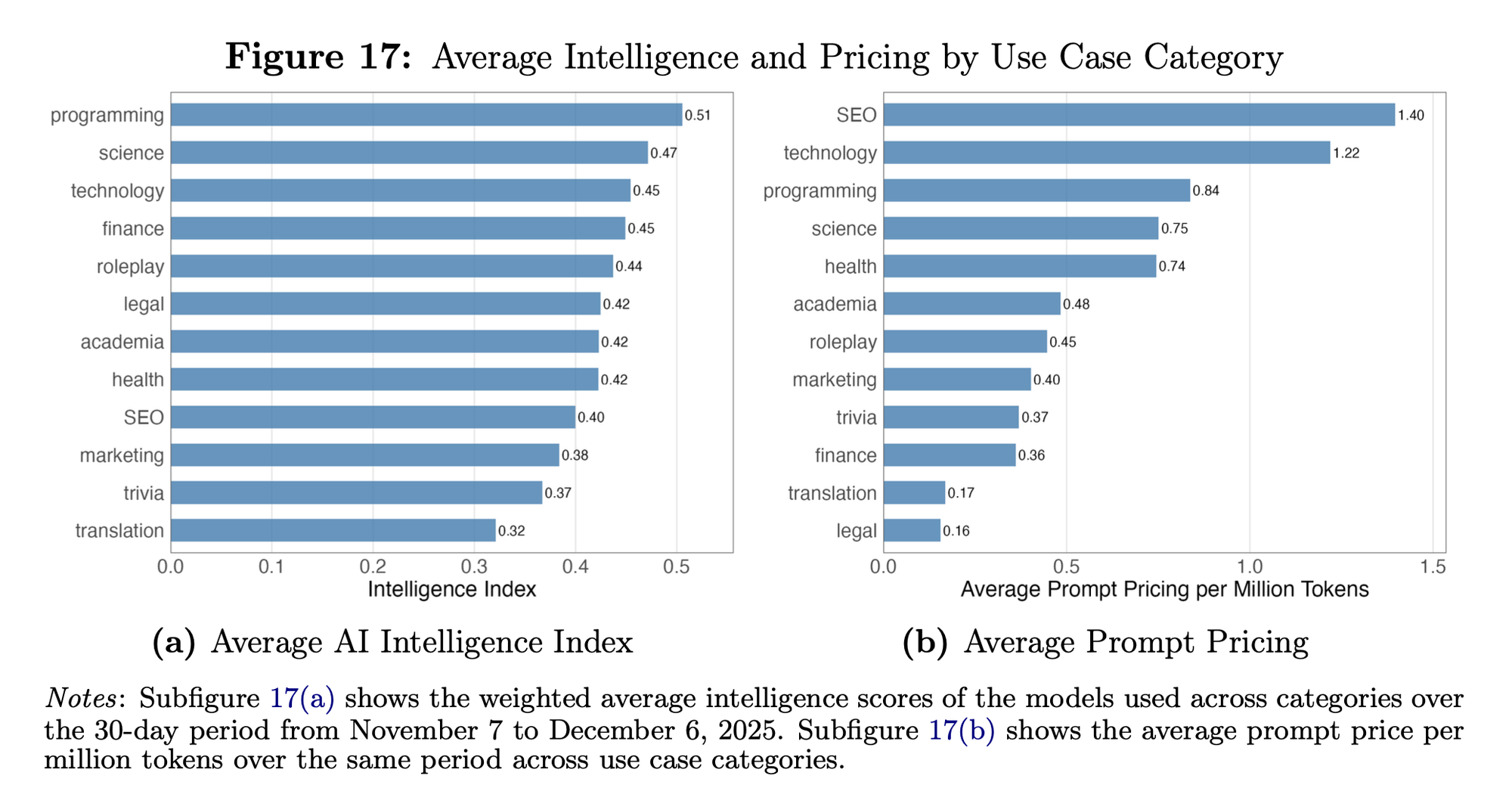
“Market-share leadership shifts frequently across both models and creators, and no single model dominates across use cases. The willingness to pay for incremental intelligence varies widely across applications, and most API usage remains below the frontier. We find evidence of heterogeneity in substitution patterns following new model entries, with some entrants cannibalizing predecessors within a model family, while others gain share with little displacement of contemporaneous competitors - patterns consistent with meaningful horizontal differentiation. Finally, using within-model provider price variation, we estimate price elasticities that are inconsistent with model- or market-level Jevons paradox effects in the short run.”
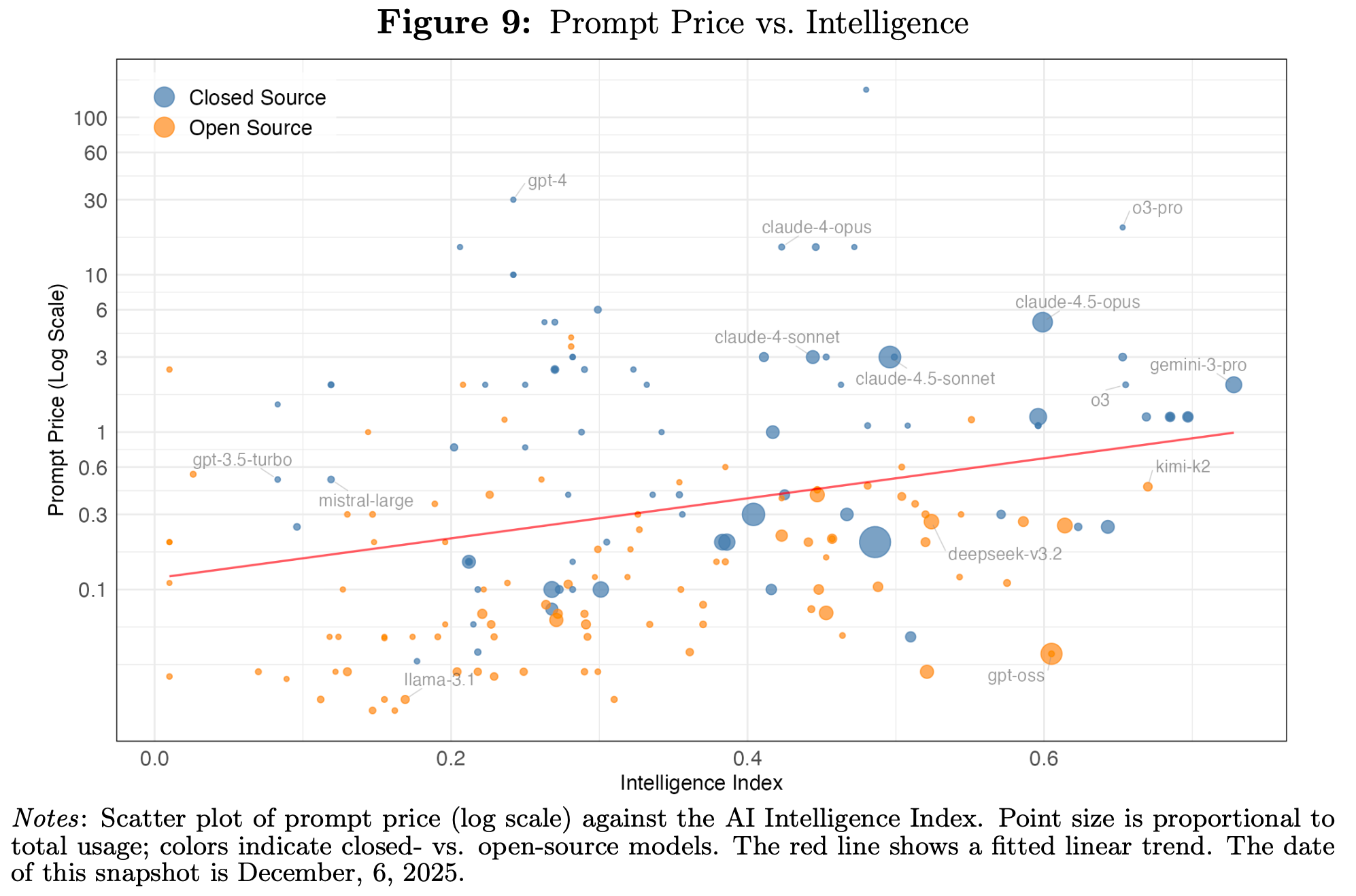
“The proliferation of inference providers—particularly for open-source models—has created competitive pressures that benefit users by lowering prices and increasing choice.”
Demirer, M., Fradkin, A., Tadelis, N., & Peng, S. (2025). The Emerging Market for Intelligence: Pricing, Supply, and Demand for LLMs. Supply, and Demand for LLMs (December 15, 2025).
https://andreyfradkin.com/assets/LLM_Demand_12_12_2025.pdf
Learning Unmasking Policies for Diffusion Language Models
Clues
“Thus, one critical design aspect of dLLMs is the sampling procedure that selects, at each step of the diffusion process, which tokens to replace. Indeed, recent work has found that heuristic strategies such as confidence thresholding lead to both higher quality and token throughput compared to random un-masking. However, such heuristics have downsides: they require manual tuning, and we observe that their performance degrades with larger buffer sizes. In this work, we instead propose to train sampling procedures using reinforcement learning.”
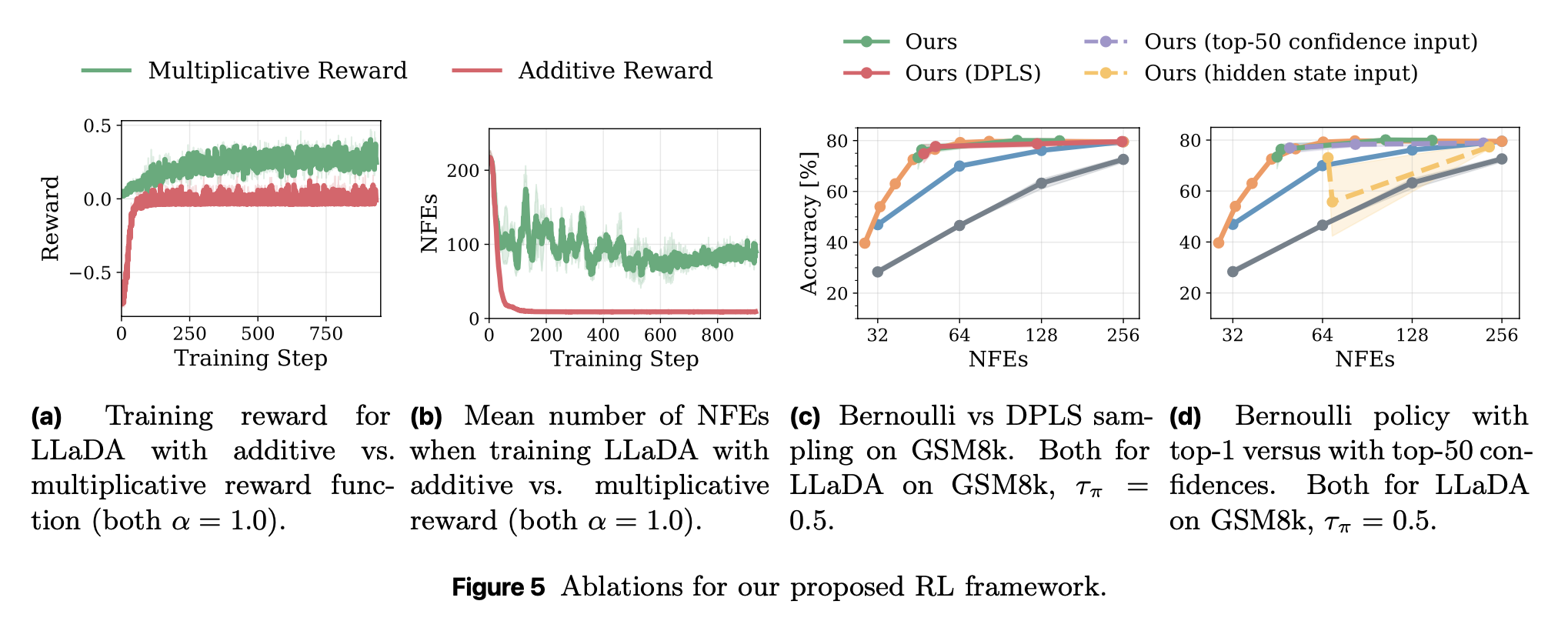
“One possible direction for future work is thus to train policies on a mixture of models, which might help bridge this gap, or to explore other lightweight ways of incorporating semantic information (e.g., by pairing confidences with the (un)embedding vectors of the corresponding tokens).” ”However, we also observe that their performance degrades when applied to out-of-domain data, and that fine-grained tuning of the accuracy-efficiency trade-off can be challenging with our approach.”
Jazbec, M., Olausson, T. X., Béthune, L., Ablin, P., Kirchhof, M., Monterio, J., ... & Cuturi, M. (2025). Learning Unmasking Policies for Diffusion Language Models. arXiv preprint arXiv:2512.09106.
https://arxiv.org/abs/2512.09106
On the Interplay of Pre-Training, Mid-Training, and RL on Reasoning Language Models
Wow!
“Recent reinforcement learning (RL) techniques have yielded impressive reasoning improvements in language models, yet it remains unclear whether post-training truly extends a model’s reasoning ability beyond what it acquires during pre-training. A central challenge is the lack of control in modern training pipelines: large-scale pre-training corpora are opaque, mid-training is often underexamined, and RL objectives interact with unknown prior knowledge in complex ways. To resolve this ambiguity, we develop a fully controlled experimental framework that isolates the causal contributions of pre-training, mid-training, and RL-based post-training. Our approach employs synthetic reasoning tasks with explicit atomic operations, parseable step-by-step reasoning traces, and systematic manipulation of training distributions. We evaluate models along two axes: extrapolative generalization to more complex compositions and contextual generalization across surface contexts.”
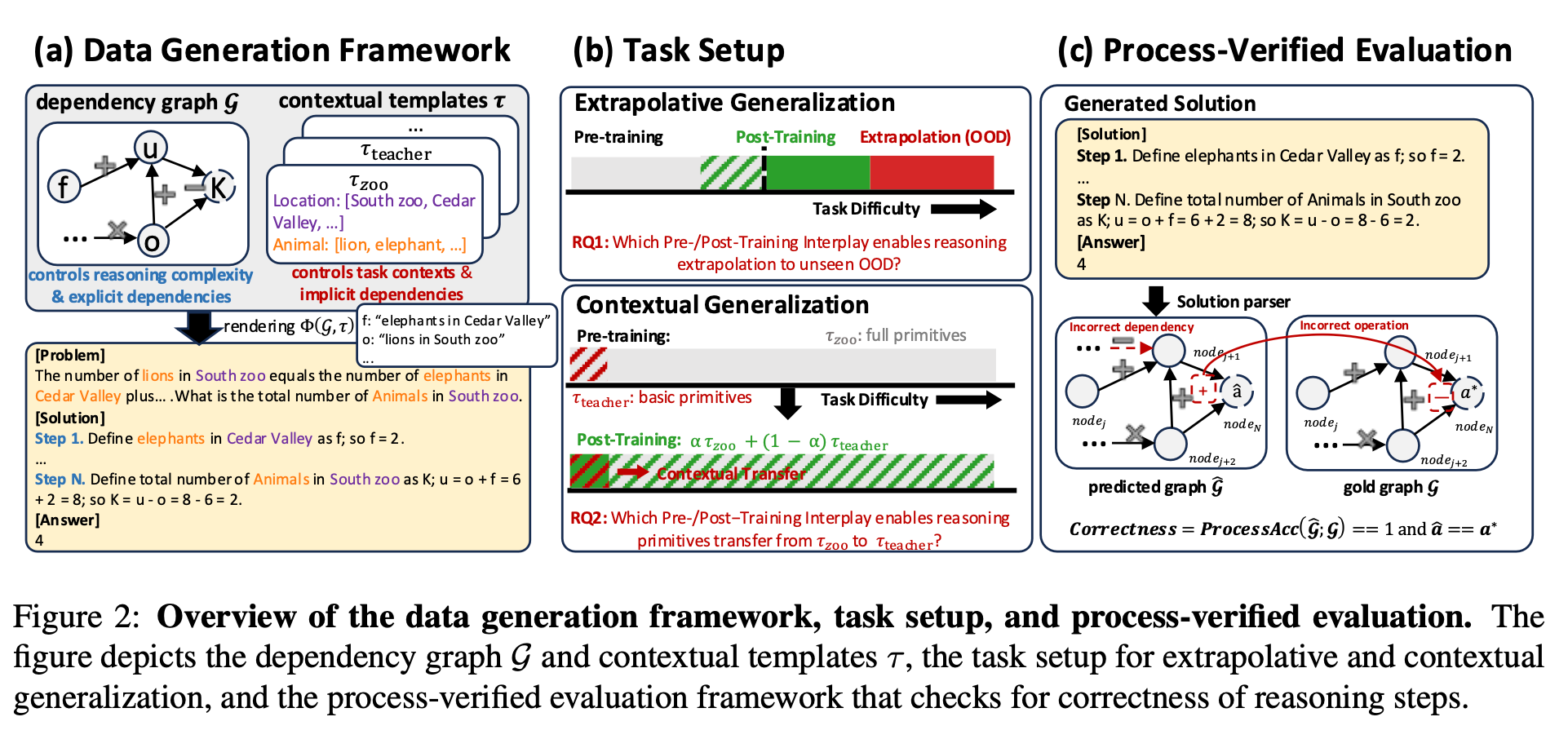
“1) RL produces true capability gains (pass@128) only when pre-training leaves sufficient headroom and when RL data target the model’s edge of competence, tasks at the boundary that are difficult but not yet out of reach. 2) Contextual generalization requires minimal yet sufficient pre-training exposure, after which RL can reliably transfer. 3) Mid-training significantly enhances performance under fixed compute compared with RL only, demonstrating its central but underexplored role in training pipelines. 4) Process-level rewards reduce reward hacking and improve reasoning fidelity. Together, these results clarify the interplay between pre-training, mid training, and RL, offering a foundation for understanding and improving reasoning LM training strategies.”
“Using fully controllable synthetic reasoning tasks and process-level evaluations, we demonstrated that genuine reasoning improvements through post-training arise only when key reasoning primitives are established during pre-training. Together, these results refine our understanding of reasoning development in language models and provide actionable guidance for constructing data curricula, designing reward functions, and allocating compute across training stages.”
Zhang, C., Neubig, G., & Yue, X. (2025). On the Interplay of Pre-Training, Mid-Training, and RL on Reasoning Language Models. arXiv preprint arXiv:2512.07783.
https://www.arxiv.org/abs/2512.07783
Business Angel Groups and Exit Strategies: A Mixed Methods Approach
It generalizes beyond Switzerland
“This thesis challenges the prevailing view of exits as incidental outcomes for business angels, presenting the deliberate and strategic approach taken by angel groups in planning and executing exit strategies.”
“(1) How do financial capital, locus of decision-making, and formalization influence exit strategies within angel groups? and (2) How do angel groups leverage their collective resources to implement exit strategies? In addition, the emergence of ‘hybrid angel groups’ that combine elements of both informal angel investing and formal venture capital funds is explored and conceptualized. To address these questions, a mixed-method approach is employed. At the macro level, a survey of 160 angel groups in Sweden is analyzed, presenting four distinct clusters of angel groups, each characterized by different combinations of formalization and locus of decision-making, and associated with varying exit strategies.”
““Although I can’t get into too many details about this, there is a clause mentioned in the memorandum of understanding, that if an exit opportunity arises, we must take also. Also, we have a time horizon in mind, and a rough exit route in mind. However, in reality when we work, or when we have board meetings and other meetings, we aren’t really focused on the exit.” – (Entrepreneur)”
Pasumarthy, K. (2024). Business Angel Groups and Exit Strategies: A Mixed Methods Approach.
https://lucris.lub.lu.se/ws/portalfiles/portal/196520559/Defense-_Kalyan_Pasumarthy.pdf
Reader Feedback
“Power-seeking is a root cause.”
Footnotes
The earliest of the earliest feedback: positive.
The choice to mark a clear delineation between a qualitative method and a quantitative method succeeded.
Nearly all of us experience the world qualitatively most of the time. It’s an extremely deliberate act to experience the world quantitatively. This seems like it’s ground truth.
So, when you’re inviting feedback from a single person, and you’re watching and actively listening, you’re experiencing high bandwidth about a singular instance. And, you, as the principle investigator, are having a direct impact on the feedback from the person you’re engaging with. It is circular and reinforcing. So, to do excellent qualitative research, in part, you have to be curious enough to step through yourself to de-risk the likelihood of premature convergence or inaccurate information. The risk never falls to zero because there’s an intense ambiguity of experience involved. Applying these kinds of treatment effects to a prosumer manager isn’t something I’ve ever heard anybody express a need for, and so, it doesn’t strike me as an interesting problem.
You do have to be rather deliberate to have a quantitative experience, and it’s one that seems to cause intense pain.
Most of the people I’ve worked with experience quantitative through the excel sheet, which they typically access through a dashboard interface, or a file that is emailed to them on a regular cadence. Fewer experience it through the R or Python-based IDE.
That choice of tool for quantitative experiences matters a lot because it has a lot to do with pain mitigation and anxiety reduction.
There’s a clue there.
Never miss a single issue
Be the first to know. Subscribe now to get the gatodo newsletter delivered straight to your inbox