Attention Without End
This week: Ultra-long context, hive minds, GEPA, HEDGE, research agenda, seeing like a software company
Every Token Counts: Generalizing 16M Ultra-Long Context in Large Language Models
Attention Without End
“This work explores the challenge of building “Machines that Can Remember”, framing long-term memory as the problem of efficient ultra-long context modeling. We argue that this requires three key properties: sparsity, random-access flexibility, and length generalization. To address ultra-long-context modeling, we leverage Hierarchical Sparse Attention (HSA), a novel attention mechanism that satisfies all three properties.”
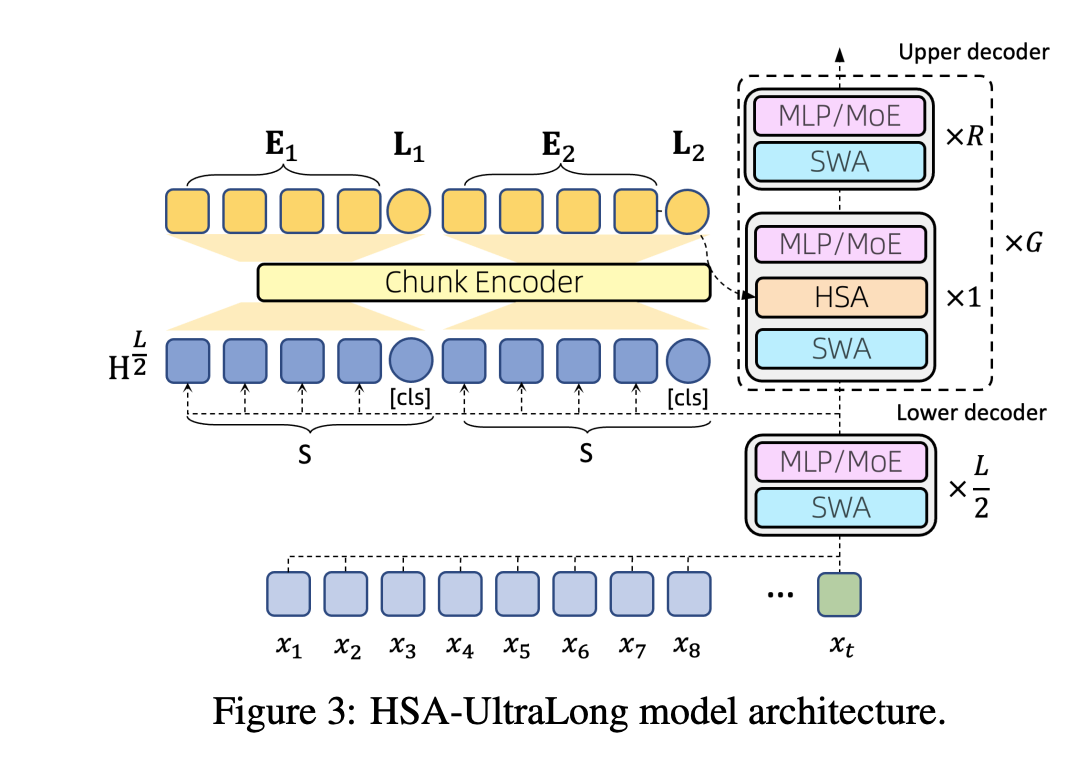
“The core insight of HSA is to perform attention chunk by chunk and fuse the results via retrieval scores, rather than selecting chunks and then concatenating them for attention. The experimental results provide a meaningful step toward effectively handling infinite-long context, advancing progress on long-term memory in machines.”
Hu, X., Zhou, Z., Liang, R., Li, Z., Wu, W., & Li, J. (2025). Every Token Counts: Generalizing 16M Ultra-Long Context in Large Language Models. arXiv preprint arXiv:2511.23319.
https://arxiv.org/abs/2511.23319
The Hive Mind is a Single Reinforcement Learning Agent
If only orgs were that rational
“Natural systems are known to converge to optimal strategies through at least two distinct mechanisms: collective decision-making via imitation of others, and individual trial-and-error. This paper establishes an equivalence between these two paradigms by drawing from the well-established collective decision-making model of nest-hunting in swarms of honey bees. We show that the emergent distributed cognition (sometimes referred to as the hive mind) arising from individual bees following simple, local imitation-based rules is that of a single online reinforcement learning (RL) agent interacting with many parallel environments. The update rule through which this macro-agent learns is a bandit algorithm that we coin Maynard-Cross Learning.”
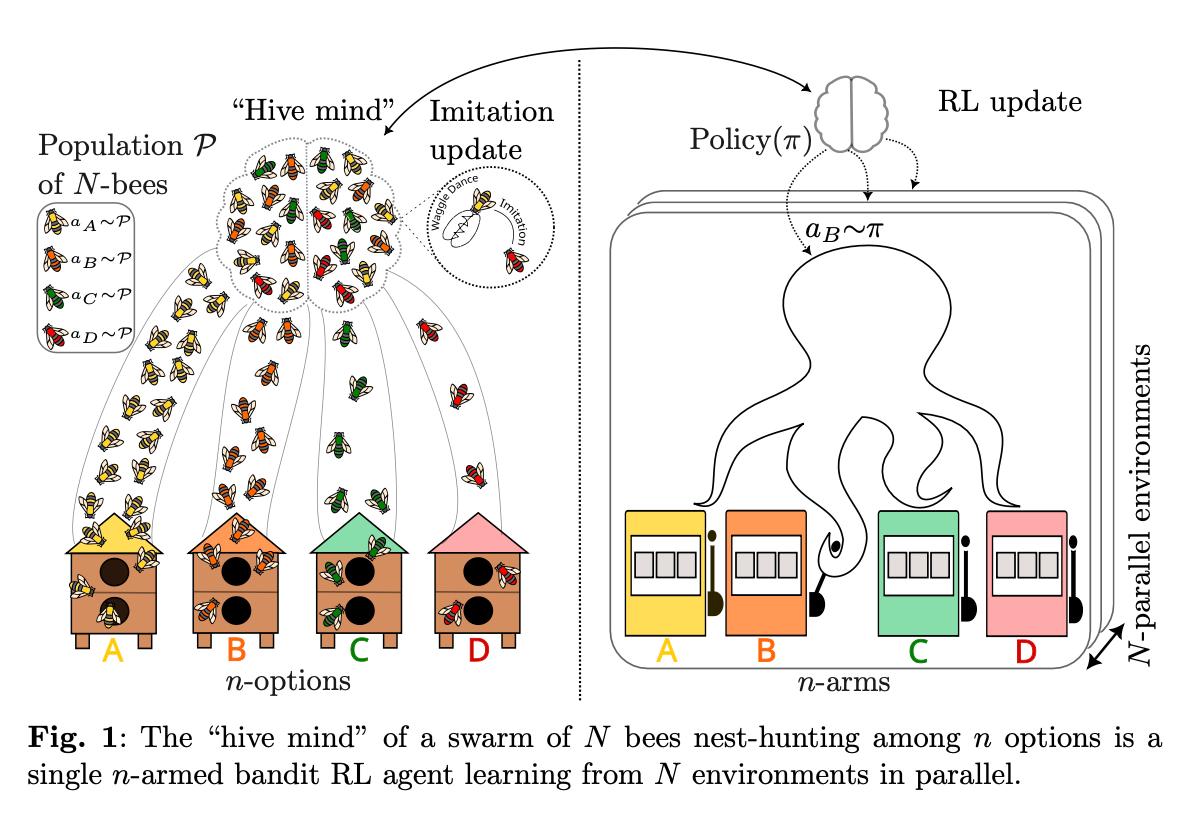
”We have demonstrated that imitation-based collective behavior in large populations can be mathematically equivalent to reinforcement learning, providing a unifying framework that reinterprets swarm intelligence, social dynamics, and evolutionary pro- cesses as emergent forms of collective learning.”
Soma, K., Bouteiller, Y., Hamann, H., & Beltrame, G. (2024). Bridging swarm intelligence and reinforcement learning. arXiv preprint arXiv:2410.17517.
GEPA: Reflective Prompt Evolution Can Outperform Reinforcement Learning
Finops is going to absolutely love this concept!
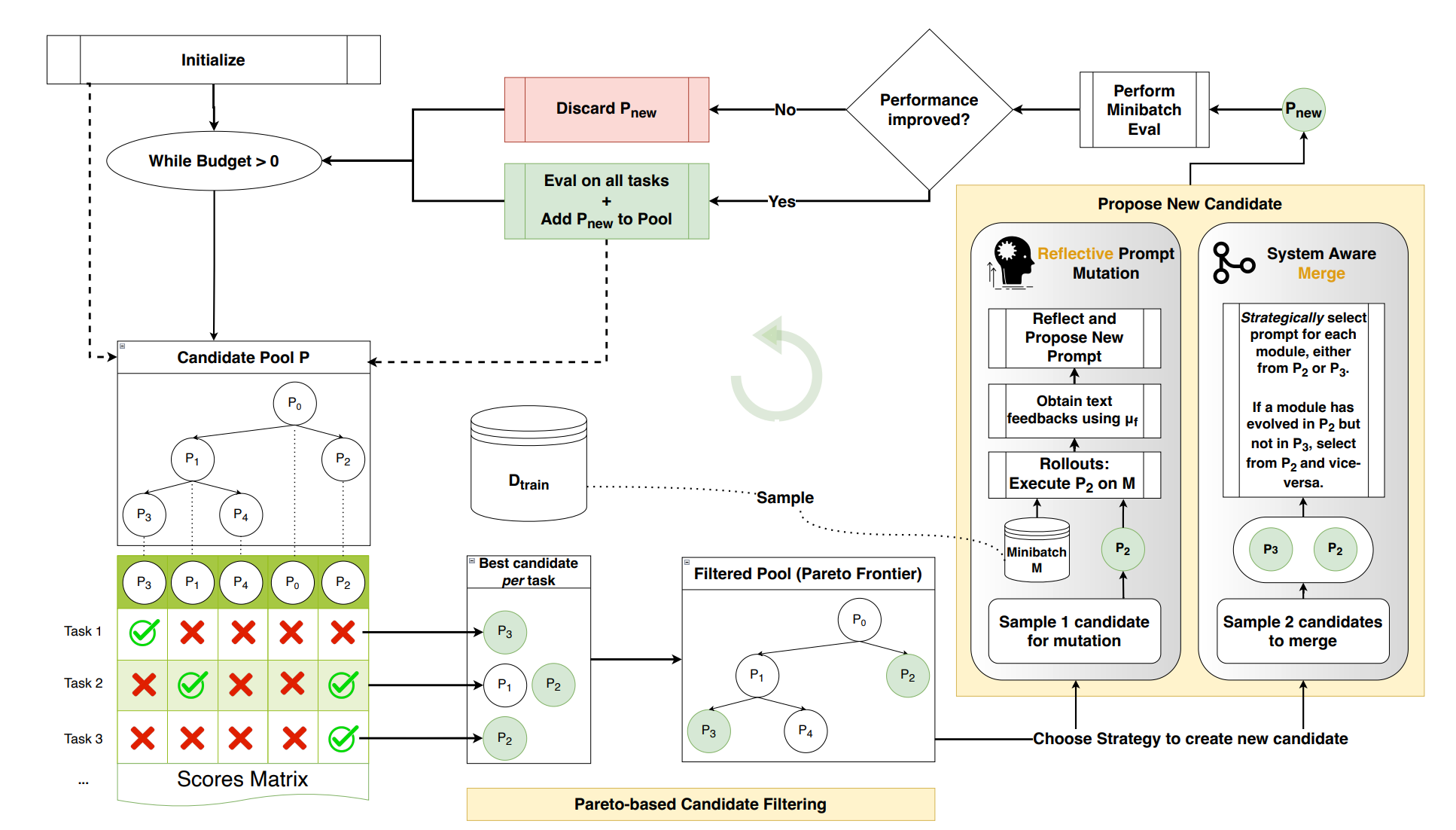
“We argue that the interpretable nature of language can often provide a much richer learning medium for LLMs, compared with policy gradients derived from sparse, scalar rewards. To test this, we introduce GEPA (Genetic-Pareto), a prompt optimizer that thoroughly incorporates natural language reflection to learn high-level rules from trial and error. Given any AI system containing one or more LLM prompts, GEPA samples system-level trajectories (e.g., reasoning, tool calls, and tool outputs) and reflects on them in natural language to diagnose problems, propose and test prompt updates, and combine complementary lessons from the Pareto frontier of its own attempts.”
“GEPA leverages global rewards as signals while incorporating additional textual feedback for each module from the environment. Unlike previous optimizers that treat the training set as a monolithic entity and optimize for overall performance, GEPA takes a fundamentally different approach. At each step, GEPA maintains and updates a Pareto front across all data instances, enabling it to match prompts to specific data points within the training set. This more fine-grained approach set the basis for GEPA’s effective prompt evolution, enabling it to explore many different prompt strategies before converging to a generalizable prompt.”
Agrawal, L. A., Tan, S., Soylu, D., Ziems, N., Khare, R., Opsahl-Ong, K., ... & Khattab, O. (2025). Gepa: Reflective prompt evolution can outperform reinforcement learning. arXiv preprint arXiv:2507.19457.
https://arxiv.org/abs/2507.19457
On the Universal Near Optimality of Hedge in Combinatorial Settings
Promising
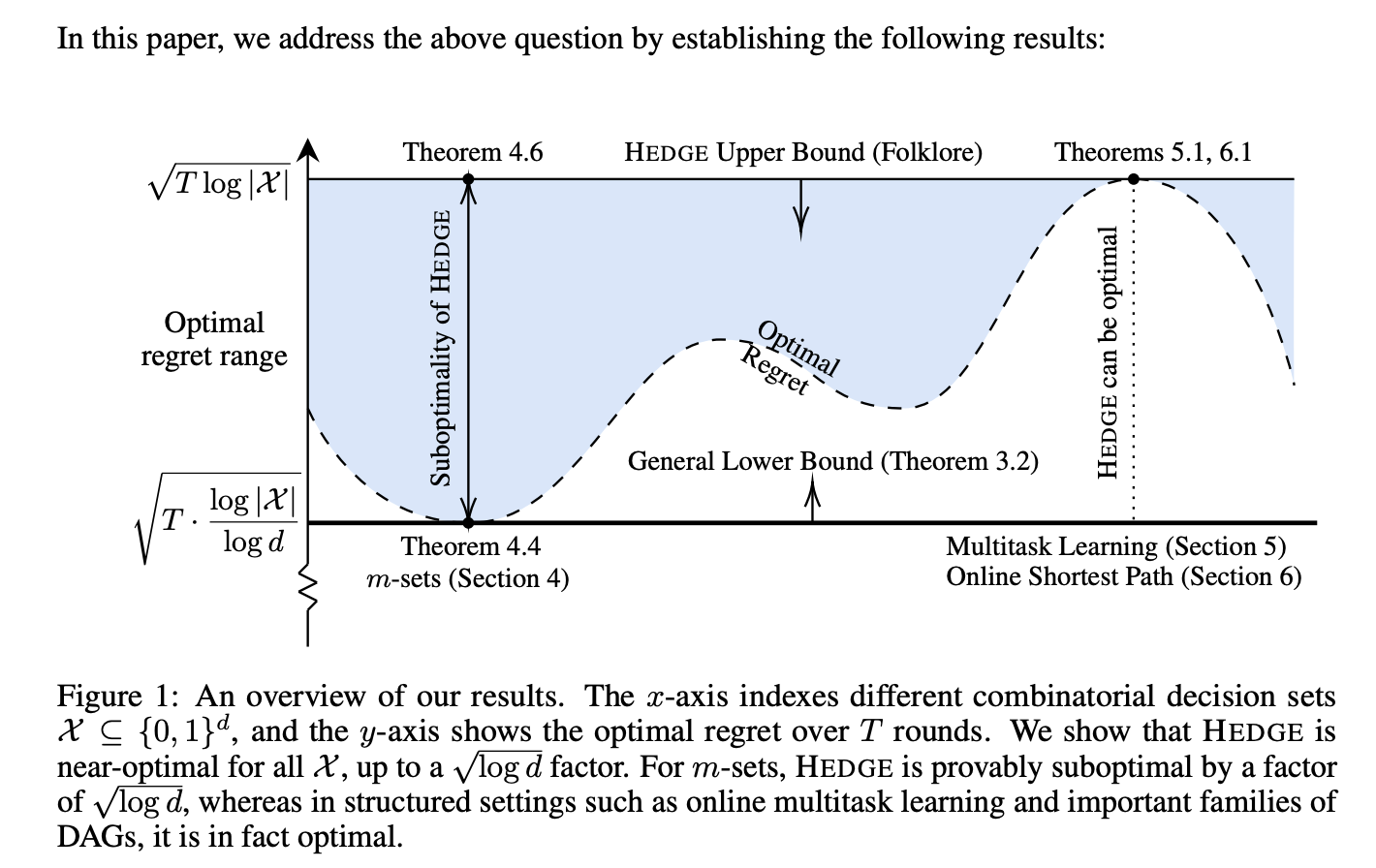
“Prediction with expert advice is a central problem in online learning [31, 13, 11, 14, 2]. In this problem, a learner selects a probability distribution over a set of experts {1, 2, . . . , K} in each round. After making the choice, the learner observes the losses of all experts, which may be assigned adversarially within [−1, 1]. The goal is to minimize the cumulative regret, defined as the difference between the learner’s expected total loss and the loss of the best expert in hindsight after T rounds. A simple and widely used algorithm for this setting is HEDGE, introduced by Freund and Schapire [24], which guarantees a regret bound of O(√T log K).”
“At the same time, we show that HEDGE is optimal for online multitask learning, a generalization of the classical K-experts problem. Finally, we leverage the near-optimality of HEDGE to establish the existence of a near-optimal regularizer for online shortest-path problems in DAGs—a setting that subsumes a broad range of combinatorial domains. Specifically, we show that the classical Online Mirror Descent (OMD) algorithm, when instantiated with the dilated entropy regularizer, is iterate-equivalent to HEDGE, and therefore inherits its near-optimal regret guarantees for DAGs.”
“Our work opens up several interesting directions for future research. One natural question is whether there exists a family of efficiently constructible regularizers that are near-optimal for the combinatorial sets. We conjecture that negative entropy in a suitably lifted space may serve as such a regularizer. In support of this, we refer the reader to Appendix E, where we show that the conjecture holds for DAGs. Another compelling direction is to explore whether there exist near-optimal variants of the Follow the-Perturbed-Leader algorithm for the combinatorial sets. Since perturbations are often considered more implementation-friendly, exploring near-optimal variants of the Follow-the-Perturbed-Leader algorithm could yield both theoretical and practical advances. Finally, we ask whether there are variants of HEDGE that achieve near-optimal regret for arbitrary finite subsets of R.”
Fan, Z., Maiti, A., Jamieson, K., Ratliff, L. J., & Farina, G. (2025). On the Universal Near Optimality of Hedge in Combinatorial Settings. arXiv preprint arXiv:2510.17099.
https://arxiv.org/abs/2510.17099
A Research Agenda for the Economics of Transformative AI
3x to 5x….

“From an economic perspective, we define Transformative AI as artificial intelligence that enables a sustained increase in total factor productivity growth of at least 3 - 5x historical averages.”
“There is a critical need for interdisciplinary research that integrates economics, computer science, public policy, and other social sciences. While significant resources are being allocated to the technical development of TAI, there has been comparatively little investment in understanding its economic implications and in research to inform policy on how to steer TAI in desired directions and prepare for the impacts.”
Brynjolfsson, E., Korinek, A., & Agrawal, A. K. (2025). A Research Agenda for the Economics of Transformative AI.
Seeing like a software company
I’ve always felt that strategic ambiguity was overrated
“By “legible”, I mean work that is predictable, well-estimated, has a paper trail, and doesn’t depend on any contingent factors (like the availability of specific people). Quarterly planning, OKRs, and Jira all exist to make work legible. Illegible work is everything else: asking for and giving favors, using tacit knowledge that isn’t or can’t be written down, fitting in unscheduled changes, and drawing on interpersonal relationships. As I’ll argue, tech companies need to support both of these kinds of work.
Thinking in terms of legibility and illegibility explains so many of the things that are confusing about large software companies. It explains why companies do many things that seem obviously counter-productive, why the rules in practice are so often out of sync with the rules as written, and why companies are surprisingly willing to tolerate rule-breaking in some contexts.”
https://www.seangoedecke.com/seeing-like-a-software-company/
Reader Feedback
“Watch me jailbreak this llm with a haiku!”
Footnotes
If you’ve been reading Footnotes, you know I’ve been exploring problems related to demand estimation, entrepreneurial behaviour, and this list of terms describing a cluster of technologies: [Digital Twins of Consumers (DTOC), Virtual Twins of Consumers (VTOC), Synthetic Customers, Synthetic Ideal Customer Profiles (SICP), Synthetic Personae, Synthetic Audiences.]
I practice the Nintendo method of product development. Or at least the myth of how Nintendo practiced it in the 1990’s.
I budget time to achieve an outcome. Then I cut it in half.
I listen to a paradox of problems and write spaghetti of code, experience mistakes, listen to feedback, watch people struggle to use the absolute time vampire I conjured, and experience intense regret with the choices I made. If only I knew then what I know now!
There truly is no time like the present. And I know things now. And I know what a sunk cost is!
So I walk away from the solution set and code base and apply the lessons to minimize that regret with the rest of the time in the budget.
The anchor insight?
The vast majority of inventors and entrepreneurs don’t metabolize their experience as minimizing regret with the demand curve.
I’ll unpack through analogy.
A new owner is building a menu for their new restaurant. The menu is a strategic document. It’s what they offer the world. It is destiny.
For every combination of ingredients, preparations, words, and physical availability, there exists a demand curve. The restaurant is dependent on inventing offers at price points that generates sufficient margin for the business to survive, thrive, and ideally, flourish.
Those that succeed tend to reduce all of the words I used above a heuristic along the lines of: “You got to give people what they want at a price that keeps them coming back and you in the black!”
And they learn to do this either through imitation (what are my prospective customers buying when they visit other restaurants in the area?) and trial and error (we’re featuring only for tonight a free range organic chicken that was sung lullabies and encouraged to do Pilates, her name was Helen, and it comes with a frites and asparagus for $46.99).
There’s something about the invention of irresistible value propositions that’s just so much damn fun.
And those that learn to learn before time runs out end up winning, and those who don’t…don’t.
So it’s obvious that one has to think in those terms, right?
Yeah, no, most people don’t think in terms of that heuristic.
And as a result, the demand curve for a product that serves those who do think that way has a peculiar shape.
And that shape explains my own regret function.
It’s recursively meta all the way down.
My current stance, heading into this development sprint, is that I’m writing a love letter to a niche of a niche. I’m ripping out a metric ton of complexity, refining the feedback cycle, and inverting the value proposition.
If this heresy is valid, it means trillions in savings.
And if the heresy is invalid, then I’ll have experienced a regret function viscerally.
And that, I suppose, is justice.
Check back next week for another footnote.
Never miss a single issue
Be the first to know. Subscribe now to get the gatodo newsletter delivered straight to your inbox