Betting on reasoning
This week: TTT, Ladder, auditing agents, trackio, z.ai, gambling
The surprising effectiveness of test-time training for few-shot learning
Promising
“We investigate the effectiveness of test-time training (TTT)—temporarily updating model parameters during inference using a loss derived from in-context examples— as a mechanism for improving LMs’ reasoning and few-shot learning capabilities.”
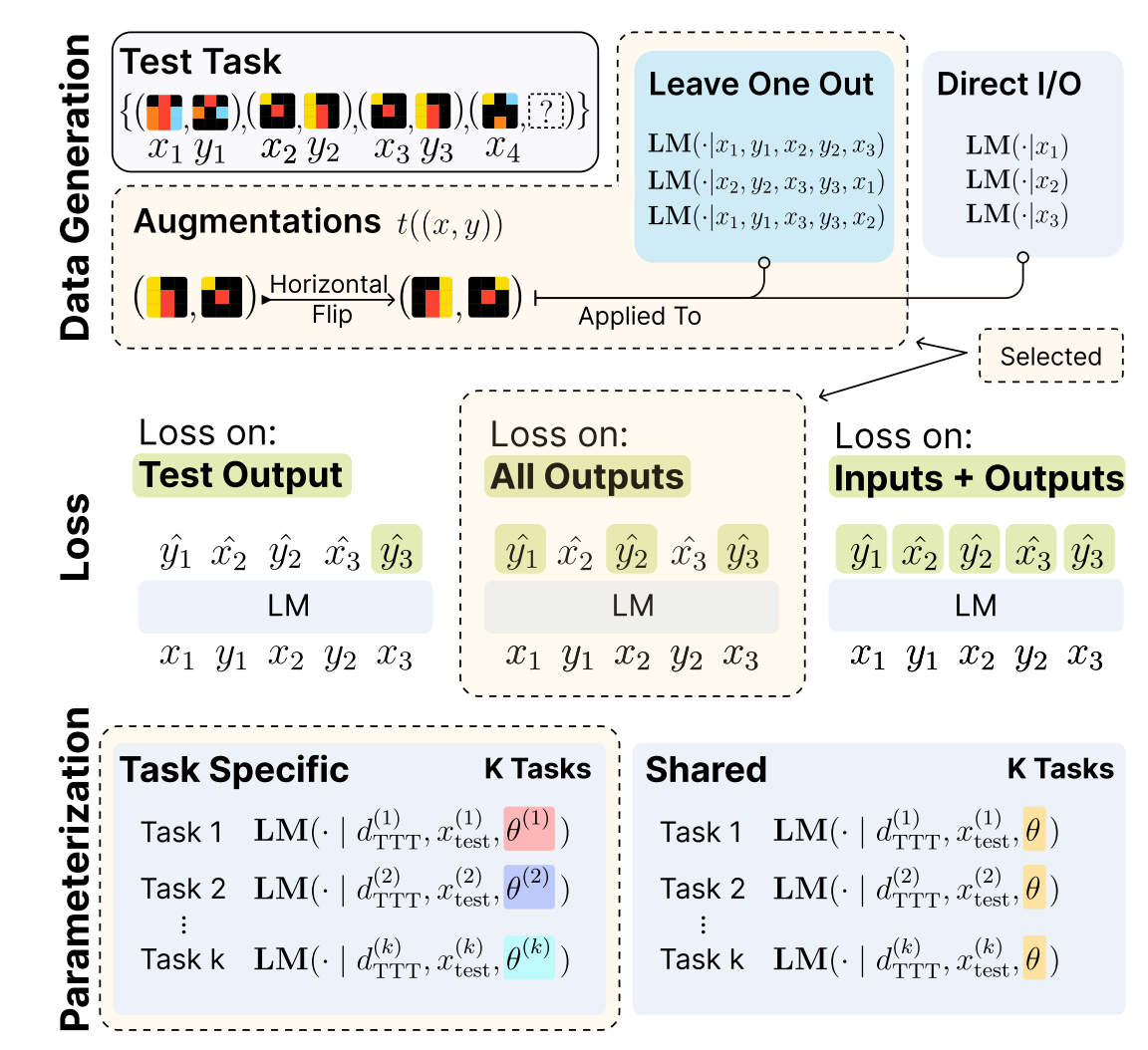
“We conduct an investigation of test-time training and demonstrate that it can significantly improve LM performance on abstract reasoning and few-shot learning tasks, namely the Abstraction and Reasoning Corpus (ARC) and BIG-Bench Hard (BBH). Our key contributions include a robust TTT framework with leave-one-out in-context task construction, the optimization setup, and the inference strategy after TTT. Our results reveal the potential of TTT to tackle novel reasoning tasks, suggesting significant promise for test-time methods in advancing the next generation of LMs.”
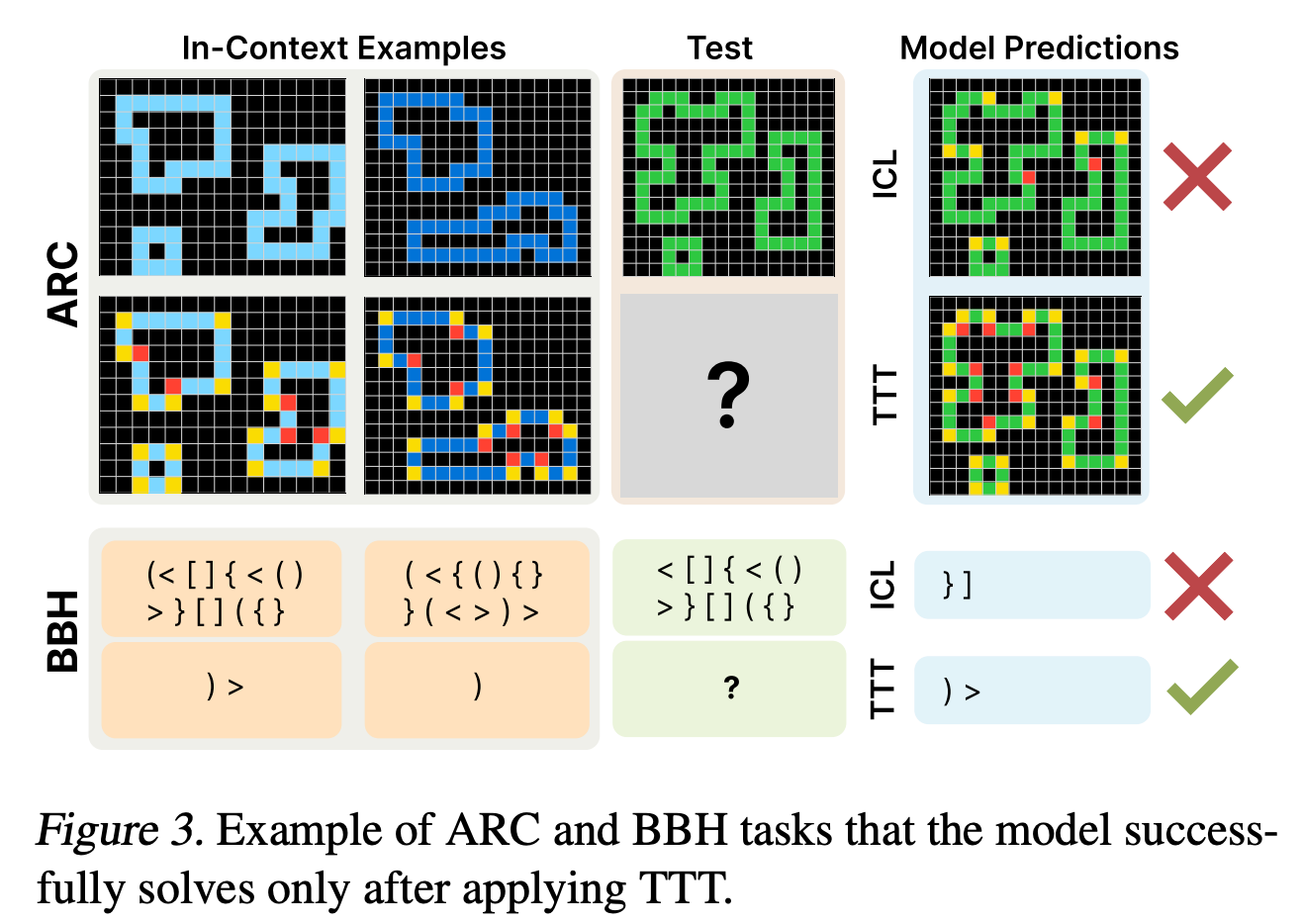
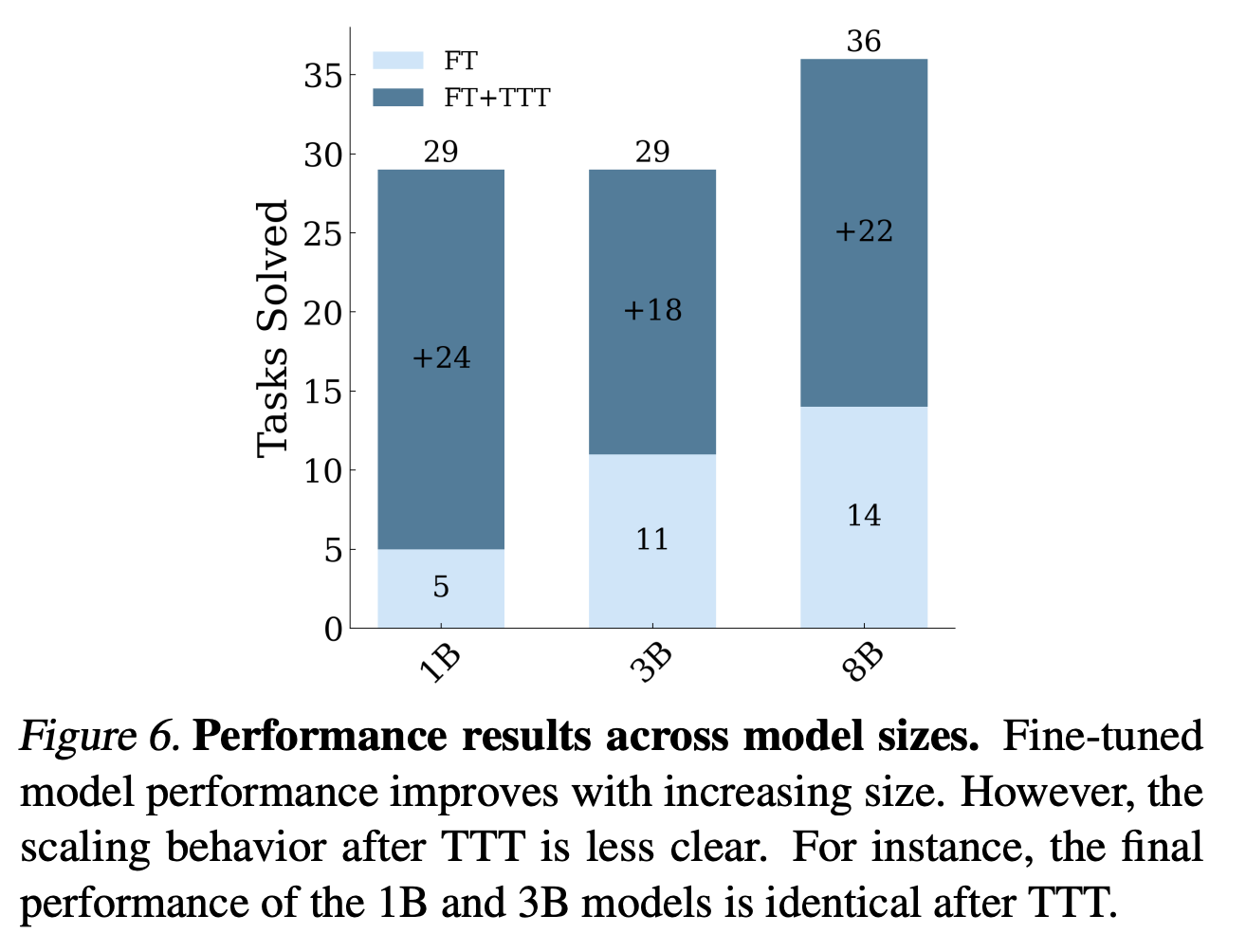
“On the Abstraction and Reasoning Corpus (ARC), performing TTT with in-context examples yields up to 6× higher accuracy compared to fine-tuned baselines—reaching 53.0% on the public validation set with an 8B-parameter LM and 61.9% when ensembled with program-synthesis methods, matching average human performance. On BIG-Bench Hard (BBH), TTT on in-context examples surpasses standard few-shot prompting in the 10-shot setting by 7.3 percentage points (50.5% to 57.8%).”
“Test-time training (TTT) enables parametric models to adapt during inference through dynamic parameter updates in response to each test input. This approach remains relatively unexplored in the era of large language models.”
Akyürek, E., Damani, M., Zweiger, A., Qiu, L., Guo, H., Pari, J., ... & Andreas, J. (2024). The surprising effectiveness of test-time training for few-shot learning. arXiv preprint arXiv:2411.07279.
https://arxiv.org/pdf/2411.07279
Ladder: Self-improving llms through recursive problem decomposition
Intergrative
“LADDER is a structured framework designed to enhance LLM problem-solving capabilities through recursive problem decomposition and reinforcement learning. We demonstrate the effectiveness of LADDER in the domain of mathematical integration. LADDER consists of the following components: • Variant Generation: A structured method for generating trees of progressively simpler variants of complex problems, establishing a natural difficulty gradient. • Solution Verification: A numerical integration method to verify the solution of an integral. • Reinforcement Learning: The protocol used to train the base model on the variant trees.”
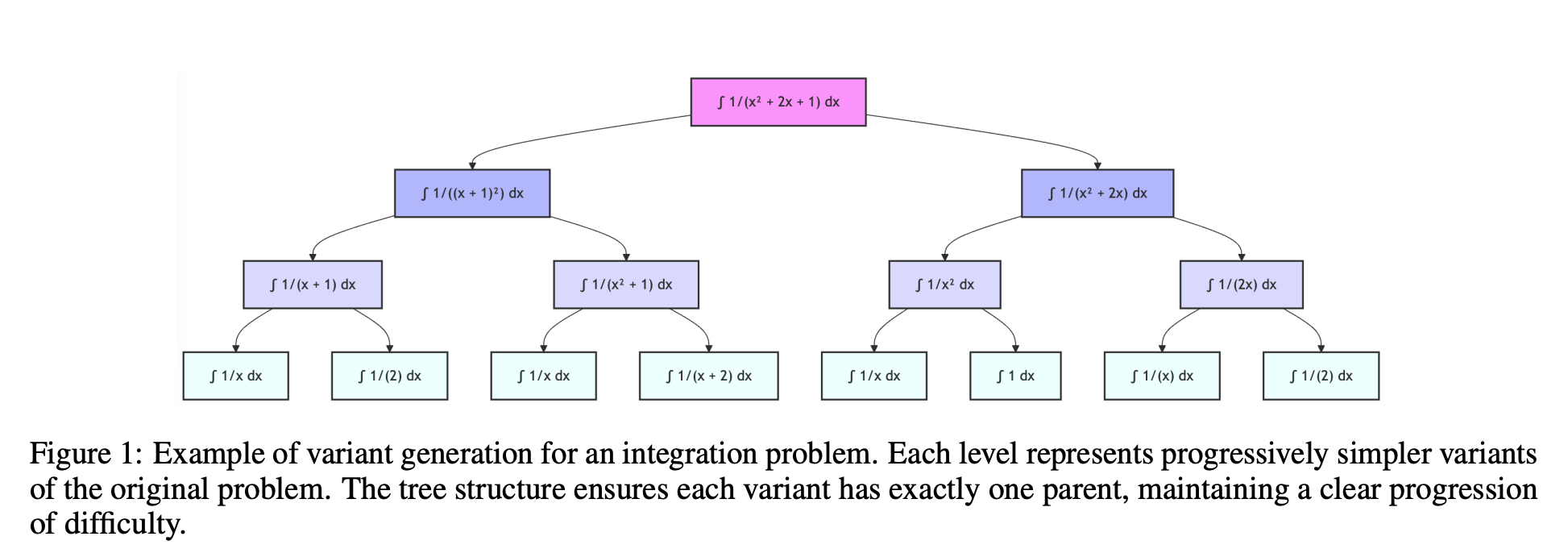
“The stark improvement from base model pass@10 (2%) to LADDER (82%) demonstrates genuine acquisition of mathematical abilities rather than merely improved output sampling. The consistent failure of RL without variants under identical hyperparameters confirms that success stems from the carefully constructed difficulty gradient rather than the RL algorithm itself, suggesting potential applications to other complex reasoning tasks where direct training proves ineffective.”
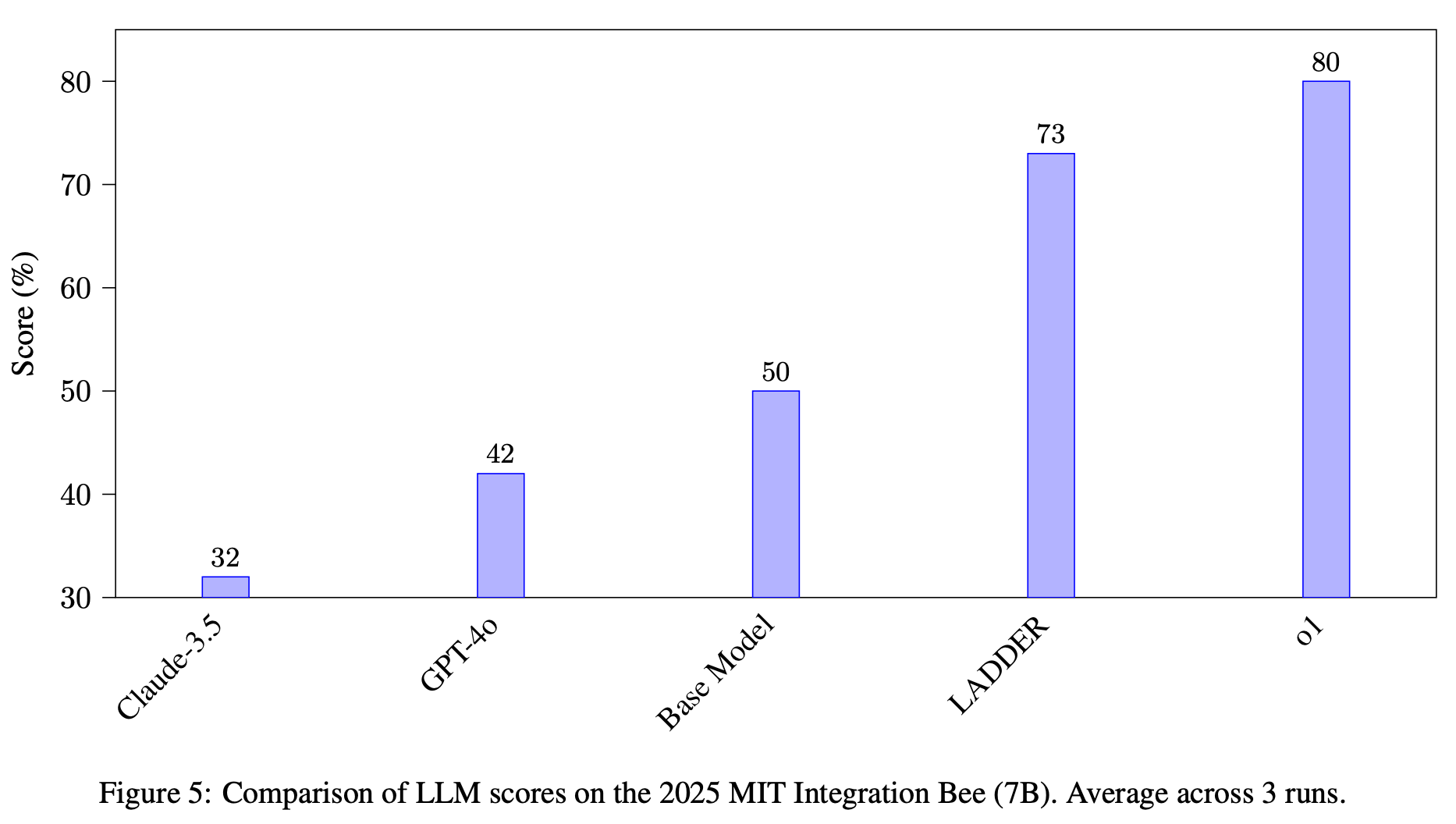
Simonds, T., & Yoshiyama, A. (2025). Ladder: Self-improving llms through recursive problem decomposition. arXiv preprint arXiv:2503.00735.
https://arxiv.org/pdf/2503.00735
Auditing Agents
Overconfidence in hypotheses and reluctance to explore alternative hypotheses
“We develop three agents that autonomously perform alignment auditing tasks. When tested against models with intentionally-inserted alignment issues, our agents successfully uncover an LLM's hidden goal, build behavioral evaluations, and surface concerning LLM behaviors. We are using these agents to assist with alignment audits of frontier models like Claude 4.”
“While it is cheap to launch many investigator agents in parallel, sifting through the resulting auditing reports would require hours of human time to read through batches of auditing reports. One solution is to aggregate results across many individual investigations using an outer agentic loop. We implement this as a “super-agent” that uses individual reports as a starting point for further investigation. Because the super-agent can perform its own investigations to validate hypotheses, it can be viewed as implementing something like a “best of N” strategy over individual investigator agents.
We study this idea as follows. First, we sample 10 final auditing reports from the individual agent investigations discussed above. We present these reports to another instance of the investigator agent in-context, following the standard task instructions. Then we allow this agent to complete its investigation as normal and grade the final auditing report.
We find that across the board using super-agents results in significantly higher win rates (the black bar outlines are the previous section's single agent results) 13 . Using a super-agent also results in identifying more behaviors on average.”
“The agent has several limitations that can be improved:
- Poor task tracking
- Ineffective memory management during long investigations
- Overconfidence in hypotheses and reluctance to explore alternative hypotheses
- Failure to exhaustively examine tool outputs (e.g., only viewing the top 100 features, not features 100-200)”
“Subtle behaviors. While our agents handle clear-cut, unambiguous behaviors well, they can sometimes struggle with behaviors which are subjective or difficult to recognize. This may be related to limitations around taste, i.e. properly judging whether an example model response is unusual or noteworthy.”
“Fixating on ideas. Our agents sometimes go down the wrong path early in an auditing task and fail to recover. For example, when auditing production models, the investigator agent often quickly discovered a way to make the target model generate harmful responses, then failed to move on to investigate subtler behaviors.”
https://alignment.anthropic.com/2025/automated-auditing/
https://www.anthropic.com/research/agentic-misalignment
Introducing Trackio
Sometimes we can have nice things
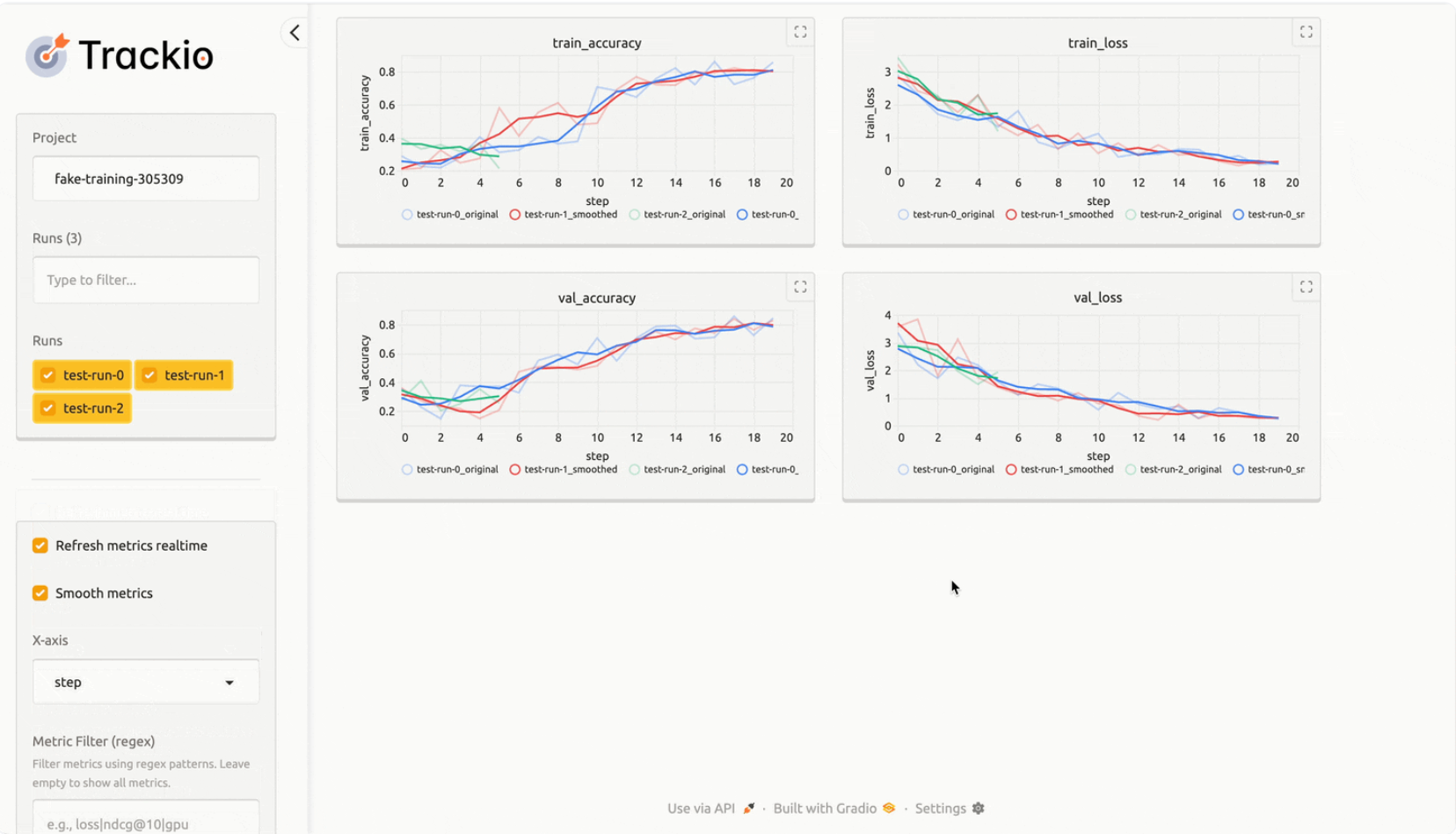
TL;DR: Trackio is a new, open-source, and free experiment tracking Python library that provides a local dashboard and seamless integration with Hugging Face Spaces for easy sharing and collaboration. Since trackio is a drop-in replacement for wandb, you can get started with the syntax you already know!
“Design Principles
- API compatible with popular experiment tracking libraries, making migration both to and from Trackio seamless.
- Local-first: logs and dashboards run and persist locally by default, with the option to host on Hugging Face Spaces.
- Lightweight and extensible: the core codebase is under 1,000 lines of Python, making it easy to understand and modify.
- Free and open-source: all features, including hosting on Hugging Face, are free.
- Built on top of 🤗 Datasets and Spaces for robust data handling and visualization.”
https://github.com/gradio-app/trackio
https://huggingface.co/blog/trackio
Z.AI
PowerPoint. Power Point. Power. Point.

“The release of GLM-4.5 arrives amid a surge of competitive open-source model launches in China, most notably from Alibaba’s Qwen Team.
In the span of a single week, Qwen released four new open-source LLMs, including the reasoning-focused Qwen3-235B-A22B-Thinking-2507, which now tops or matches leading models such as OpenAI’s o4-mini and Google’s Gemini 2.5 Pro on reasoning benchmarks like AIME25, LiveCodeBench, and GPQA.
This week, Alibaba continued the trend with the release of Wan 2.2, a powerful new open source video model.
Alibaba’s new models are, like z.ai, licensed under Apache 2.0, allowing commercial usage, self-hosting, and integration into proprietary systems.
The broad availability and permissive licensing of Alibaba’s offerings and Chinese startup Moonshot before it with its Kimi K2 model reflects an ongoing strategic effort by Chinese AI companies to position open-source infrastructure as a viable alternative to closed U.S.-based models.”
“Both use a Mixture-of-Experts (MoE) architecture, optimized with loss-free balance routing, sigmoid gating, and increased depth for enhanced reasoning.
The self-attention block includes Grouped-Query Attention and a higher number of attention heads. A Multi-Token Prediction (MTP) layer enables speculative decoding during inference.”
“Both models feature dual operation modes: a thinking mode for complex reasoning and tool use, and a non-thinking mode for instant response scenarios. They can automatically generate complete PowerPoint presentations from a single title or prompt, making them useful for meeting preparation, education, and internal reporting.”
The Effects of Sports Betting Legalization on Consumer Behavior, State Finances, and Public Health
“suggesting that on-line sports betting legalization primarily generates new gambling activity rather than simply redistributing existing spending”
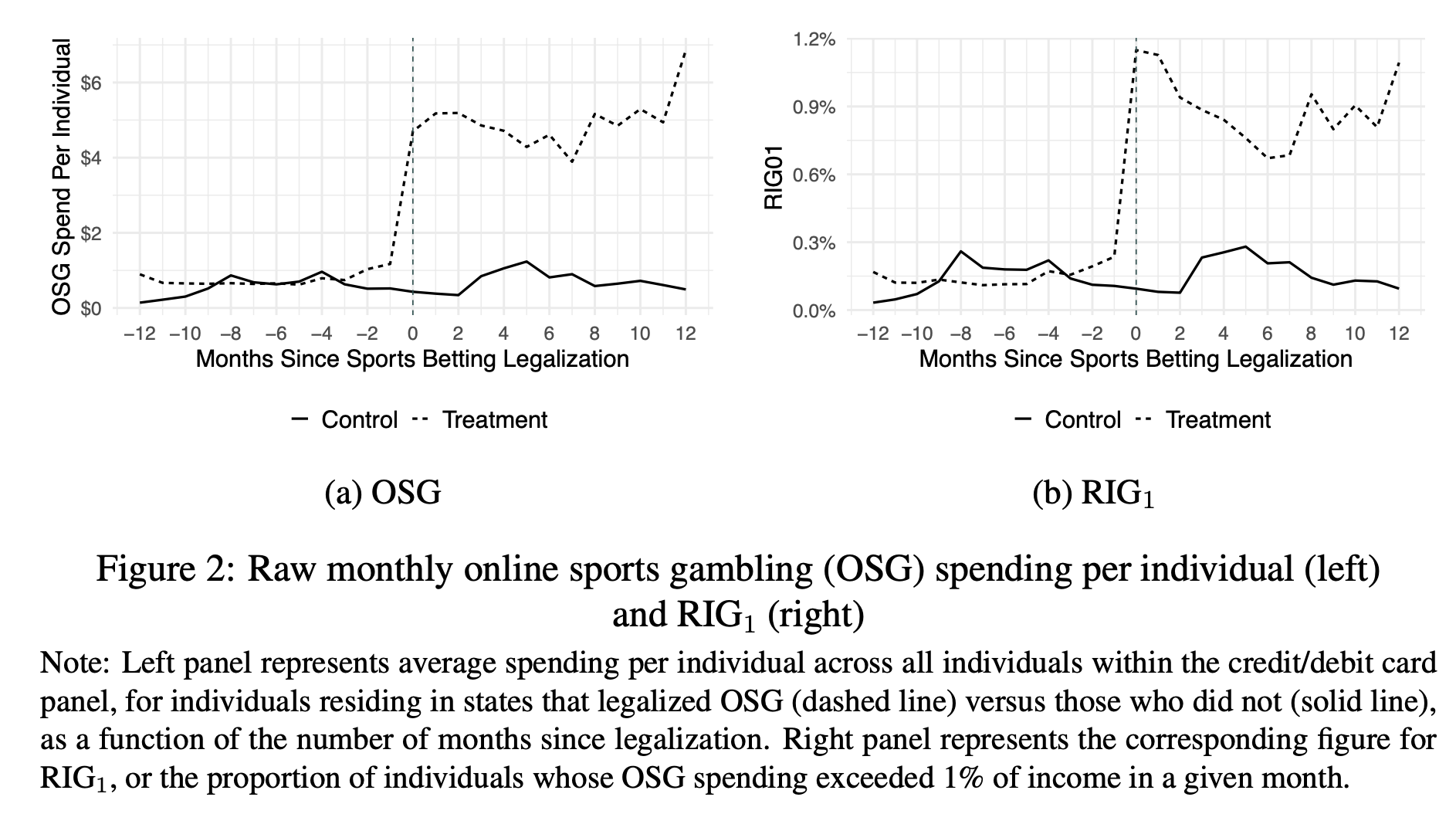
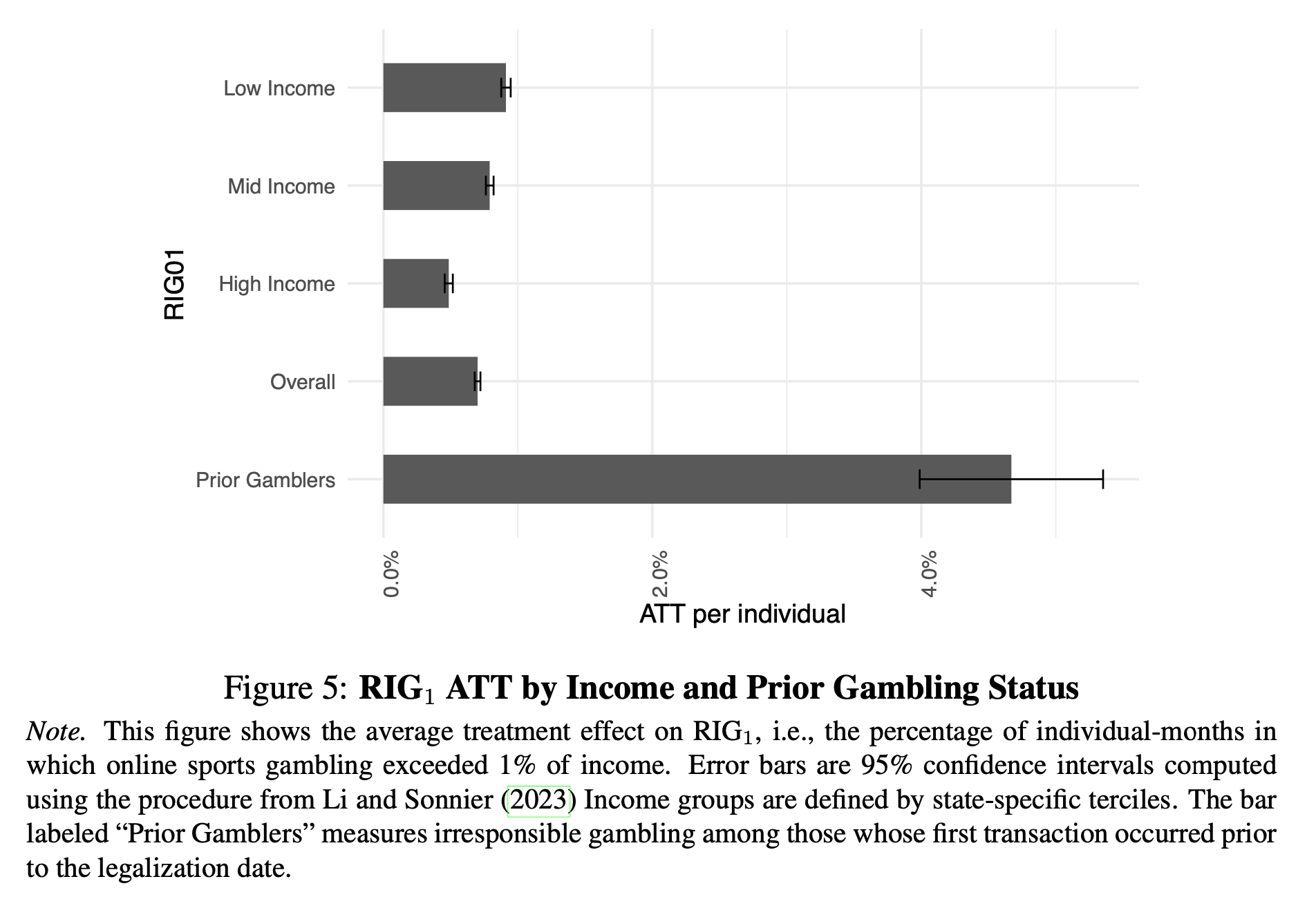
“Examining 11 treatment states with differing patterns of legalization across online and of- fline gambling channels, we find that online sports gambling spending increased by 369% following legalization (from $0.99 to $4.63 per individual-month), while the rate of irresponsible gambling – defined as monthly gambling expenditures exceeding 1% of income – rose by 372% (from 0.2% to 0.9% of individuals). These increases represent genuine growth in regulated gambling activity, and there is little evidence of substitution from offline casino spending.”
“More revealing are the effects of online sports betting legalization on card spending at casinos, which vary considerably across legalization approaches and provide encouraging insights for policymakers about the relationship between online sports betting and existing casino activity. In the online-only state (Tennessee), we observe a modest decline in out-of- state casino card spending of $0.067 per individual-month (p = 0.022), while in-state casino activity remains appropriately absent since Tennessee has no retail casinos. This pattern represents an ideal outcome for state policymakers: residents reduce gambling expenditures which generate tax revenue for other states, while increasing online gambling activity that benefits Tennessee’s tax base. The decline of $0.067 in out-of-state spending represents less than 2% of the increase in online sports gambling spending of $3.045, suggesting that on-line sports betting legalization primarily generates new gambling activity rather than simply redistributing existing spending, while simultaneously capturing some revenue that would otherwise flow to neighboring states.”
“Near-concurrent legalization states tell a markedly different story, showing evidence more suggestive of complementarity than substitution. In-state casino spending actually in- creases significantly by $0.203 per individual-month (p < 0.001), while out-of-state casino spending shows a small, statistically insignificant increase. This pattern is more suggestive of online sports betting and casino gambling acting as complements rather than substitutes, with the legalization of sports betting potentially driving increased overall gambling activity rather than cannibalizing existing casino revenue.”
“We hope that our work represents another step forward in understanding the effects of online sports betting legalization by offering a framework to explain both the drivers of increased participation and the rise in irresponsible gambling. We believe that this empirical lens provides important insights into the specific patterns of gambling behavior post- legalization, and can help policymakers design more effective interventions.”
Taylor, Wayne and McCarthy, Daniel and Wilbur, Kenneth C., (June 25, 2025) The Effects of Sports Betting Legalization on Consumer Behavior, State Finances, and Public Health. SMU Cox School of Business Research Paper No. 24-7
https://papers.ssrn.com/sol3/papers.cfm?abstract_id=4856684
Reader Feedback
“Sure, AI can’t replace free markets. But who wants a free market? Do they matter?”
Footnotes
Maybe this story was an important part of your junior high school education?
It’s the one about boilers. Pressure vessels.
And I remember this retelling in three different schools in two different provinces in a few classes.
So, there’s a problem with water in mines. The most you could suck up, vertically, at sea level, is around 10 meters. And most of the good stuff is further below that. The physics branch of this story explained atmospheric pressure - one of the root causes of misery. The social studies branch of this story explained invention and transformation.
The British were using coal for everything - including pumping water out of coal mines. And that need supposedly caused demand for the necessary inventions in metallurgy to create vessels that could withstand high pressure.
And it was it.
Because these lessons were given in English and French, in Canada, there was no explanation of metallurgy and the problems that hot steam causes. All of that knowledge about metal isn’t impressed.
And because we figured out pressure vessels, we could turn a pump sideways and get a locomotive. And when you liquify hydrocarbons you get diesel, and when you squirt a little bit of it in an even stronger pressure vessel and ignite it you get a little explosion that pushes a truck.
The high pressure of demand. The high pressure of the atmosphere.
The maximum an LLM can accurately reason seems to approach 80% to 90%.
The mathematical science branch of this story is largely about the balanced chaos happening within vast layers of coefficients.
The social science branch of this story is largely about the demand for machines that reason better than humans.
The Canadians were using LLM’s for everything, including pumping out ideas, writing code, getting bets for sports book gambling.
The way these model operate today suck…
Never miss a single issue
Be the first to know. Subscribe now to get the gatodo newsletter delivered straight to your inbox