Cartels of mutually satisfied mediocrities
This week: Digital Twin Mega-Study, predicting results, the curious preference for low quality, small language models, AnyUp
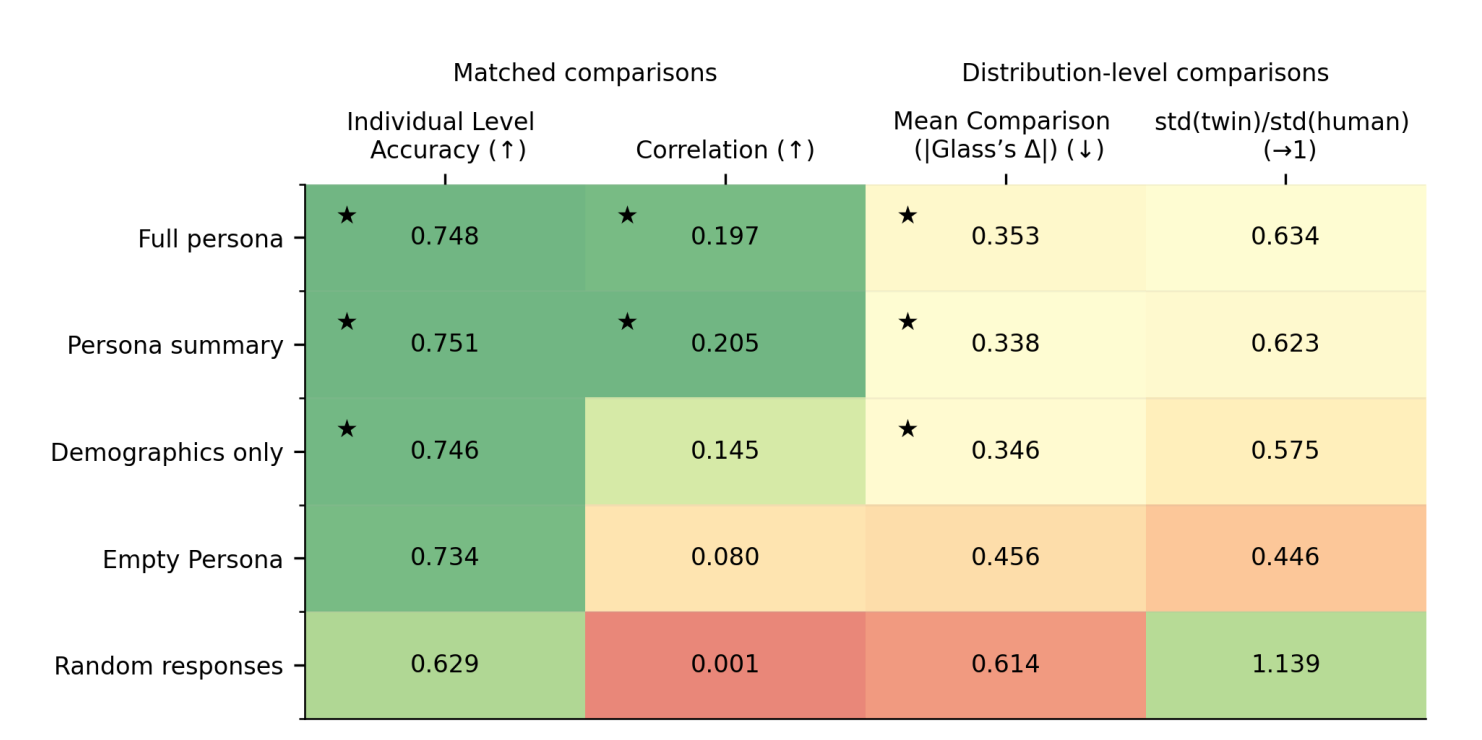
A Mega-Study of Digital Twins Reveals Strengths, Weaknesses and Opportunities for Further Improvement
Where does the twin begin?
“One may speculate, and test in future research, that several of the results we observe are due to properties of the base LLM being transferred to digital twins. For example, it is likely that the under-dispersion of answers by digital twins is the result of the homogeneity of the base model not being sufficiently offset by the individuallevel information contained in digital twins. Similarly, the inability of digital twins to improve individual-level accuracy may be due to systematic errors originating from the base LLM.”
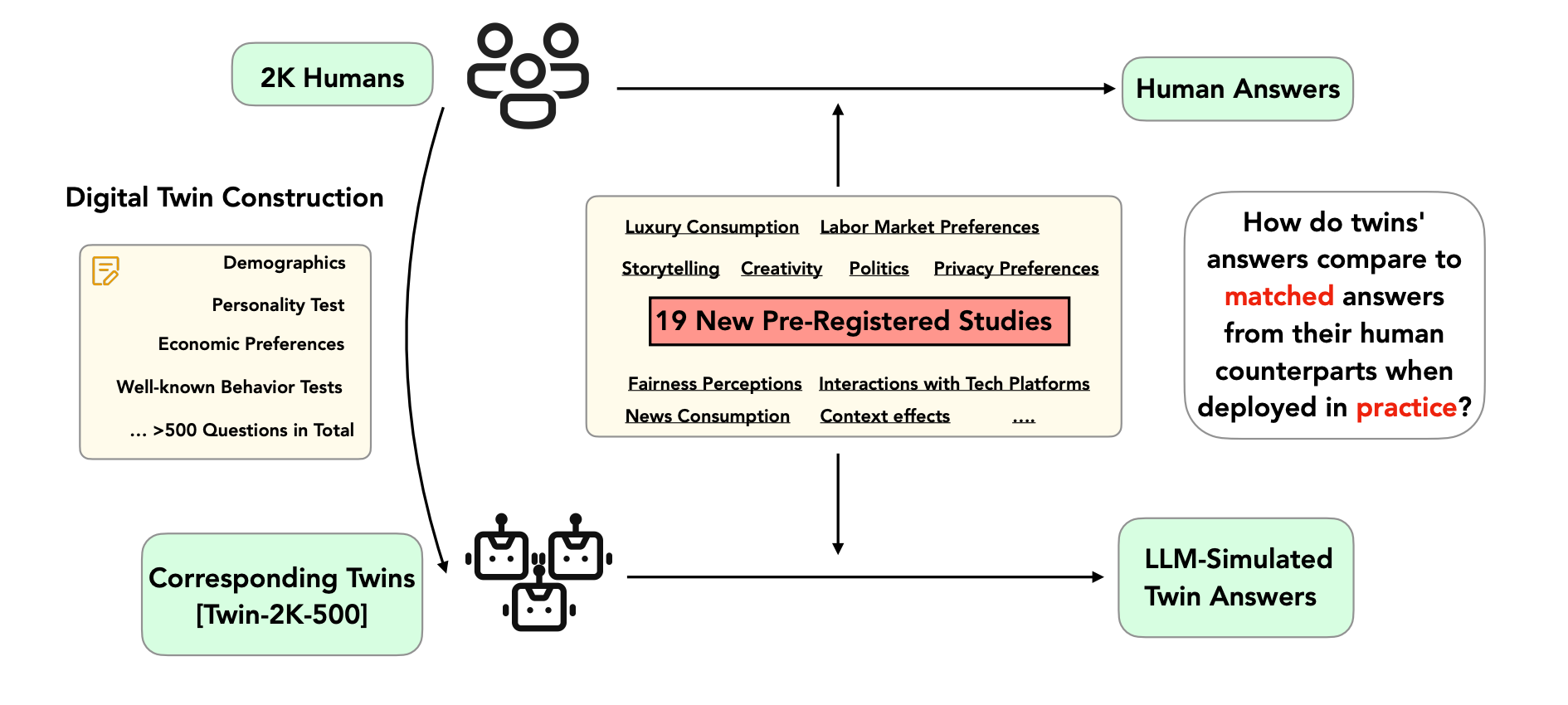
“Our findings also raise the question of how we should reasonably think about digital twins. In particular, based on our results it may not be realistic to think about them as “clones” of humans, but rather as hyper-rational, quasi-omniscient versions of humans, with implicit values partly imbued by their base LLM. This may influence which use cases are more promising for future research and practical applications. Perhaps use cases that consider digital twins as well-informed advisors are more promising than use cases that consider digital twins as carbon copies of their human counterparts.”
Peng, T., Gui, G., Merlau, D. J., Fan, G. J., Sliman, M. B., Brucks, M., ... & Toubia, O. (2025). A Mega-Study of Digital Twins Reveals Strengths, Weaknesses and Opportunities for Further Improvement. arXiv preprint arXiv:2509.19088.
https://papers.ssrn.com/sol3/papers.cfm?abstract_id=5518418
Predicting results of social science experiments using large language models
High Adjusted R Square

“We prompted an advanced, publicly-available LLM (GPT-4) to simulate how representative samples of Americans would respond to the stimuli from these experiments. Predictions derived from simulated responses correlate strikingly with actual treatment effects (r = 0.85), equaling or surpassing the predictive accuracy of human forecasters. Accuracy remained high for unpublished studies that could not appear in the model’s training data (r = 0.90). We further assessed predictive accuracy across demographic subgroups, various disciplines, and in nine recent megastudies featuring an additional 346 treatment effects.”

“This work suggests that LLM-based approaches can offer insights for both basic scientific theory building and real-world intervention design, competitive with the primary tools used at present by social and behavioral scientists and expert practitioners. For instance, our approach can be used to run quick, low-cost LLM-based pilot studies to help researchers identify high-yield ideas to investigate, generate effect size predictions for use in Bayesian priors and/or power analyses, estimate the reliability of past work and identify studies in need of replication.”
Hewitt, L., Ashokkumar, A., Ghezae, I., & Willer, R. (2024). Predicting results of social science experiments using large language models. Preprint.
https://samim.io/dl/Predicting results of social science experiments using large language models.pdf
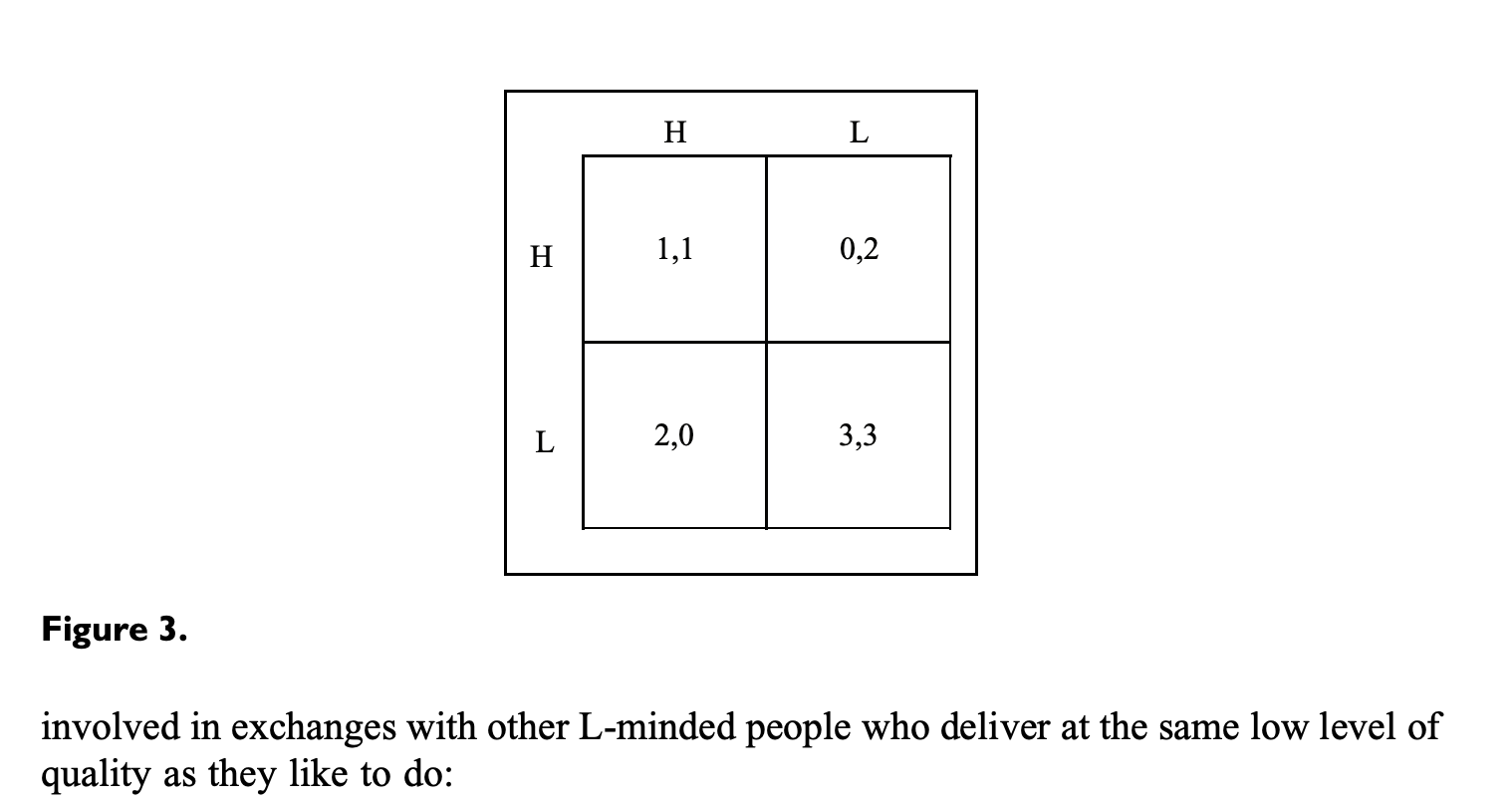
The LL game: The curious preference for low quality and its norms
cartels of mutually satisfied mediocrities
“We argue that high-quality collective outcomes are endangered not only by self-interested individual defectors, but by ‘cartels’ of mutually satisfied mediocrities.”
“Unless we suspect the existence of a bias due to the fact that we deserved unfavourable treatment, we can be confident that the sum of our independent experiences amounts to a statistically significant sample, representative of the universe of encounters with the kind of people with whom we have interacted.”
“To admit to L-ness could attract punishment or at least ridicule, especially when the norms of an institution overtly assume that H standards are to be expected – shouting ‘The king has no clothes’ would fatally undermine the legitimacy of the exchange or institution in which L doers thrive.”
“The tolerance of L-ness can be experienced as flexibility, acceptance of each other’s shortcomings and of the unavoidable ‘noise’ produced by lives subject to conflicting demands.”
Gambetta, D., & Origgi, G. (2013). The LL game: The curious preference for low quality and its norms. Politics, philosophy & economics, 12(1), 3-23.
https://diegogambetta.org/wp-content/uploads/2022/06/the_ll_game.pdf
Small Language Models are the Future of Agentic AI
The investors aren’t going to like to hear this
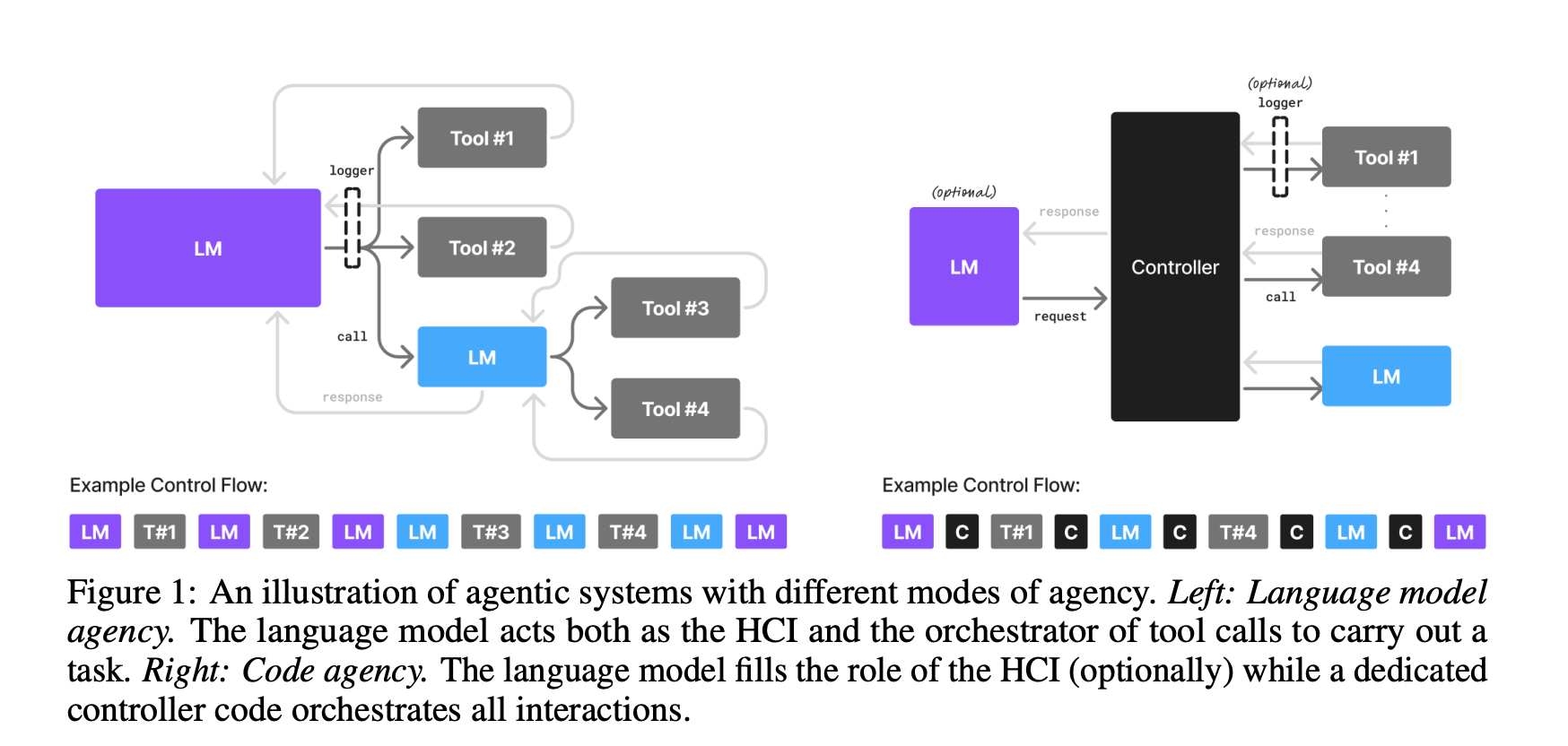
“Here we lay out the position that small language models (SLMs) are sufficiently powerful, inherently more suitable, and necessarily more economical for many invocations in agentic systems, and are therefore the future of agentic AI. Our argumentation is grounded in the current level of capabilities exhibited by SLMs, the common architectures of agentic systems, and the economy of LM deployment. We further argue that in situations where general-purpose conversational abilities are essential, heterogeneous agentic systems (i.e., agents invoking multiple different models) are the natural choice. We discuss the potential barriers for the adoption of SLMs in agentic systems and outline a general LLM-to-SLM agent conversion algorithm.”
“Small models provide significant benefits in cost-efficiency, adaptability, and deployment flexibility. These advantages are specifically valuable in agentic workflows where specialization and iterative refinement are critical.”
Belcak, P., Heinrich, G., Diao, S., Fu, Y., Dong, X., Muralidharan, S., ... & Molchanov, P. (2025). Small Language Models are the Future of Agentic AI. arXiv preprint arXiv:2506.02153.
https://arxiv.org/abs/2506.02153v2
AnyUp: Universal Feature Upsampling
The Universal is here
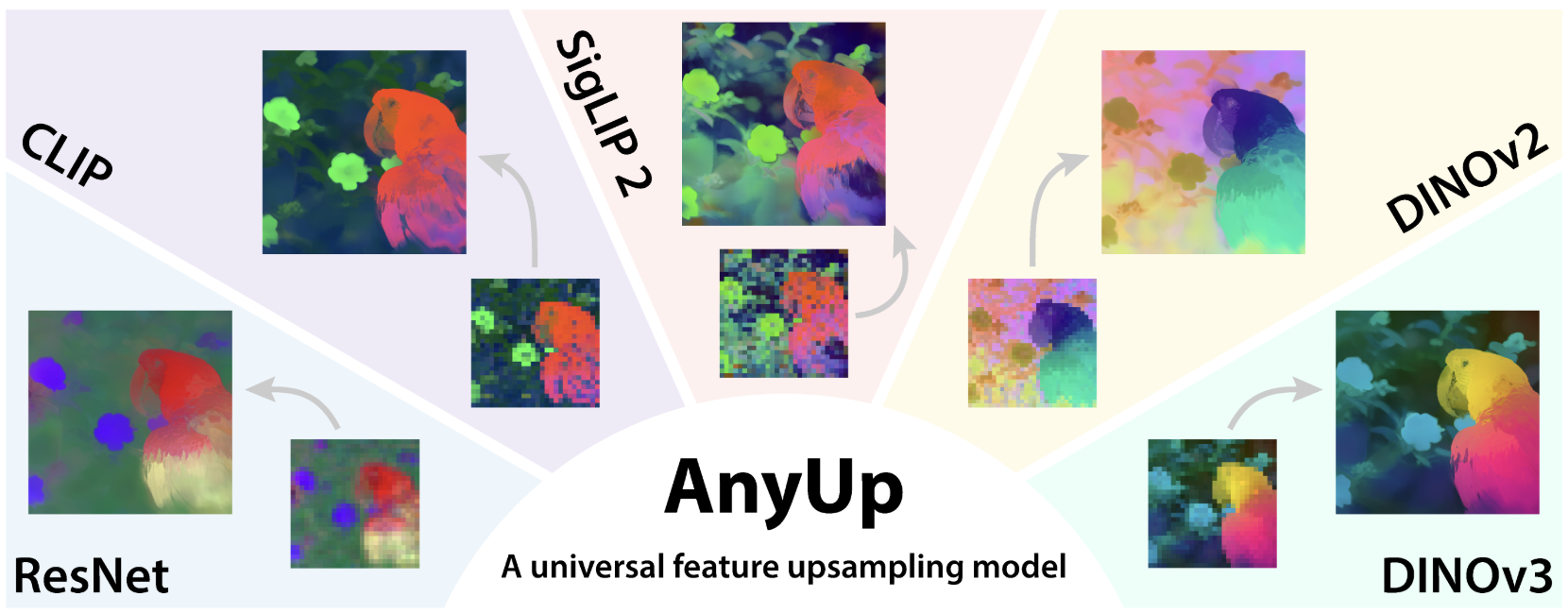
“We introduce AnyUp, a method for feature upsampling that can be applied to any vision feature at any resolution, without encoder-specific training. Existing learning-based upsamplers for features like DINO or CLIP need to be re-trained for every feature extractor and thus do not generalize to different feature types at inference time. In this work, we propose an inference-time feature-agnostic upsampling architecture to alleviate this limitation and improve upsampling quality. In our experiments, AnyUp sets a new state of the art for upsampled features, generalizes to different feature types, and preserves feature semantics while being efficient and easy to apply to a wide range of downstream tasks.”
https://github.com/wimmerth/anyup
Reader Feedback
“Okay, I wouldn’t say premature convergence. I’d say fallacy.”
Footnotes
Most initiatives fail. Not because they can’t build, but because they misread demand.
For instance, 93% of startups fail. 80% of that failure comes from misunderstanding customers.
Traditional validation costs over $200k and takes months, so most skip it. They trust their gut, a friend, or now, an LLM that just agrees with them.
What if there was another way? If you could summon your segment, test your assumptions, and validate your market: fast, rigorously, fearlessly, would you?
Never miss a single issue
Be the first to know. Subscribe now to get the gatodo newsletter delivered straight to your inbox