HARKing: Hypothesizing After Results are Known
This week: Augmentation potential, AI and the fed, GSPO, building an American TMSC, building a search engine, and self-adaptive reasoning
Future of Work with AI Agents: Auditing Automation and Augmentation Potential across the US
Employee stances are major factors for why a technology is adopted or maliciously complied with
“…we propose a principled, survey-based framework to investigate which occupa- tional tasks workers want AI agents to automate or augment. We look at the entire workforce that could be impacted by digital AI agents by sourcing occupational tasks from the U.S. Department of Labor’s O*NET database. Compared to occupation-level studies, task-level auditing allows us to better capture the nuanced, open-ended, and contextual nature of real-world work. Our auditing framework takes a worker-centric approach by soliciting first-hand insights from domain workers actively performing the tasks. To guide domain workers in providing well-calibrated responses, we empower them to share their experiences and articulate their reasoning through an audio-enhanced survey system. Crucially, our framework expands beyond the binary view of automation.”
“Domain workers want automation for low-value and repetitive tasks (Figure 4). For 46.1% of tasks, workers express positive attitudes toward AI agent automation, even after reflecting on potential job loss concerns and work enjoyment. The primary motivation for automation is freeing up time for high-value work, though trends vary significantly by sector.”
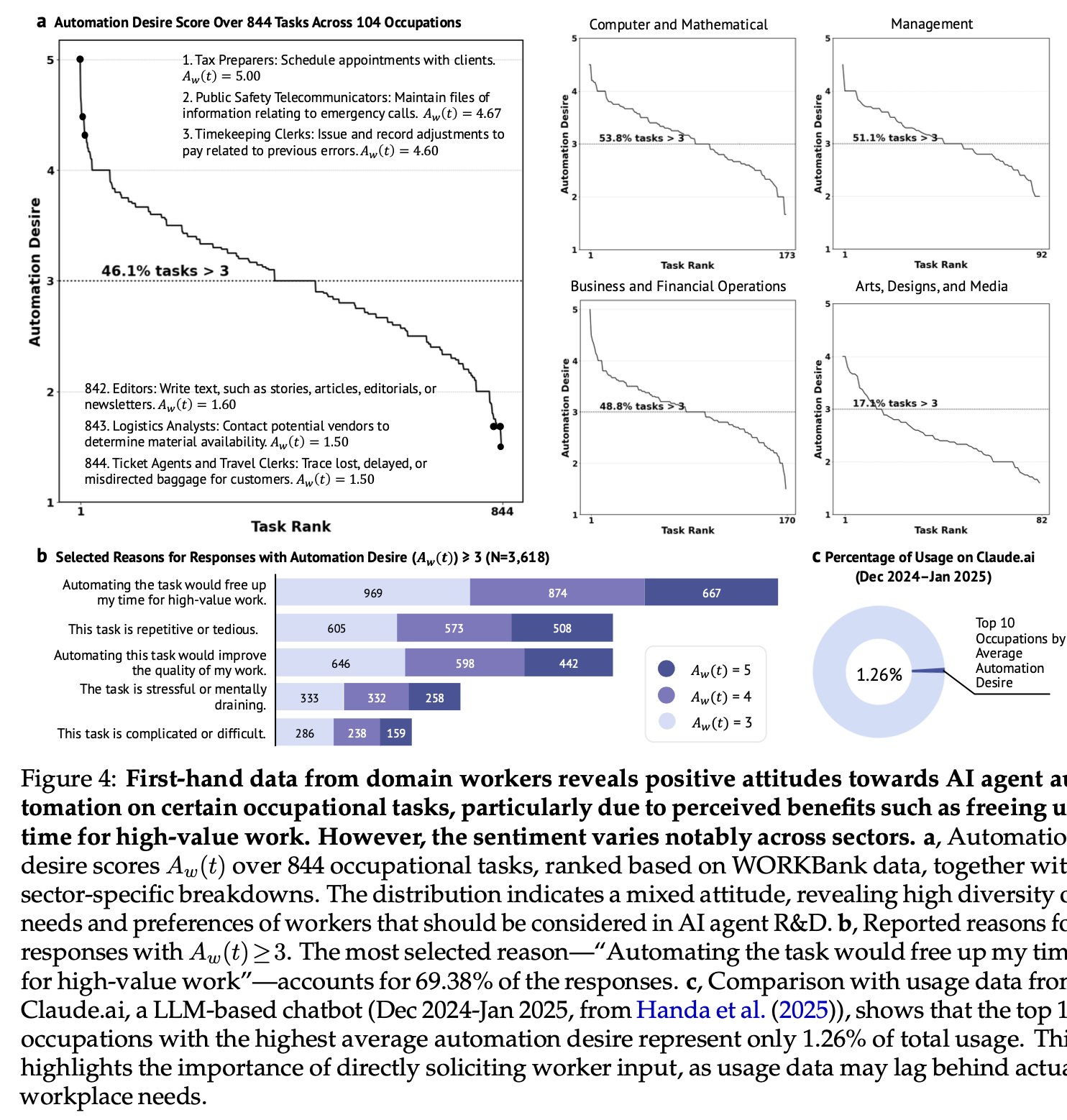
“Notably, when we compare our findings with usage data from Claude.ai, an LLM-based chatbot used between Dec 2024 and Jan 2025 (Handa et al., 2025), we find that the top 10 occupations with the highest average automation desire account for only 1.26% of total usage. This mismatch highlights a disconnect: occupations where workers most desire automation are currently underrepresented in LLM usage. This suggests that existing usage patterns may be skewed toward early adopters or specific job types, rather than reflecting broader demand. Such a gap reinforces the value of our worker-centric audit, which surfaces latent needs that may not yet appear in usage logs.”

“Contrasting worker and AI expert perspectives delineate four task zones. While workers’ preferences offer valuable guidance for socially beneficial AI agent deployment, delivering impact ultimately depends on aligning those preferences with technical feasibility. To investigate this, we jointly consider the worker-rated automation desire Aw(t) and expert-assessed technological capability Ae(t), visualized as a desire-capability landscape in Figure 5 a. This landscape divides into four zones:
- Automation “Green Light” Zone: Tasks with both high automation desire and high capability. These are prime candidates for AI agent deployment with the potential for broad productivity and societal gains.
- Automation “Red Light” Zone: Tasks with high capability but low desire. Deployment here warrants caution, as it may face worker resistance or pose broader negative societal implications.
- R&D Opportunity Zone: Tasks with high desire but currently low capability. These representpromising directions for AI research and development.
- Low Priority Zone: Tasks with both low desire and low capability. These are less urgent for AIagent development.”
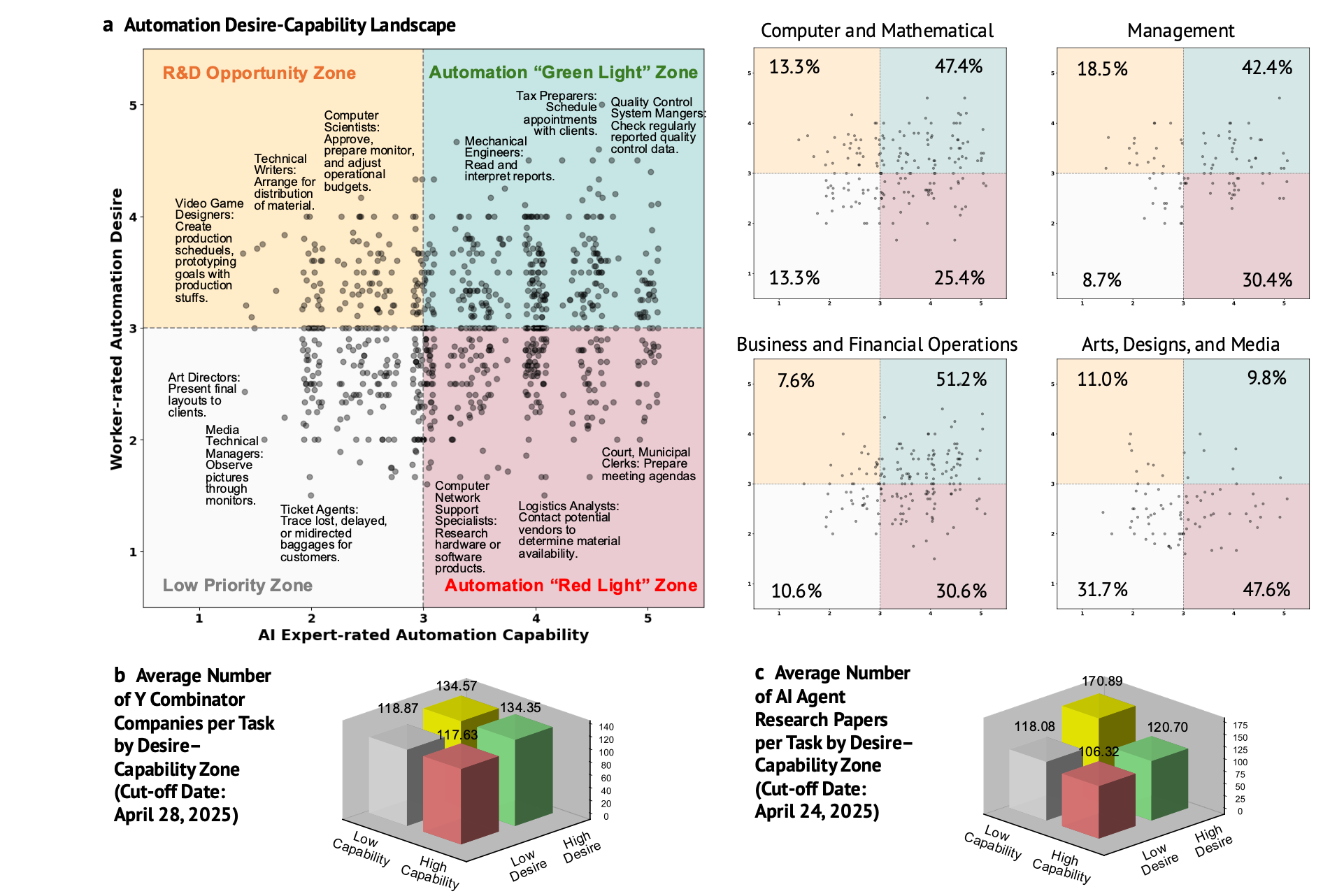
“By integrating both worker and expert perspectives, we introduce the automation desire–capability landscape, which offers actionable insights for prioritizing AI agent research and investment. Besides the traditional automate-or-not dichotomy, our Human Agency Scale (HAS) uncovers diverse patterns of AI integration across occupations, with a dominant inverted-U trend that underscores the potential for human–agent collaboration.”
Shao, Y., Zope, H., Jiang, Y., Pei, J., Nguyen, D., Brynjolfsson, E., & Yang, D. (2025). Future of Work with AI Agents: Auditing Automation and Augmentation Potential across the US Workforce. arXiv preprint arXiv:2506.06576.
https://arxiv.org/pdf/2506.06576
AI And The Fed
“bureaucratic processes often clash with agile innovation cycles that drive adoption in the private sector”
“This paper examines how central banks can strategically integrate artificial intelligence (AI) to enhance their operations. Using a dual-framework approach, we demonstrate how AI can transform both strategic decision-making and daily operations within central banks, taking the Federal Reserve System (FRS) as a representative example. We first consider a top-down view, showing how AI can modernize key central banking functions. We then adopt a bottom-up approach focusing on the impact of generative AI on specific tasks and occupations within the Federal Reserve and find a significant potential for workforce augmentation and efficiency gains. We also address critical challenges associated with AI adoption, such as the need to upgrade data infrastructure and manage workforce transitions.”
“Early evidence suggests that the adoption of AI in government lags behind its implementation in the private sector (SAS Institute Inc., 2024), given the fundamental structural differences between these sectors. Unlike private firms that prioritize profit maximization or operational efficiency, a central bank is driven by public policy objectives, and often navigates ambiguous situations without a single “ground truth”.6 Beyond that, bureaucratic processes often clash with agile innovation cycles that drive adoption in the private sector.”
“Despite collecting petabytes of data, governments lack the infrastructure to prepare it for the AI era. In contrast, private-sector firms oftent circumvent these challenges through centralized data lakes.”

“In particular, automated research increases the potential for Hypothesizing After Results are Known (HARKing), given that AI can effortlessly produce artificially coherent narratives and post-hoc theoretical justifications to fit observed data patterns.”
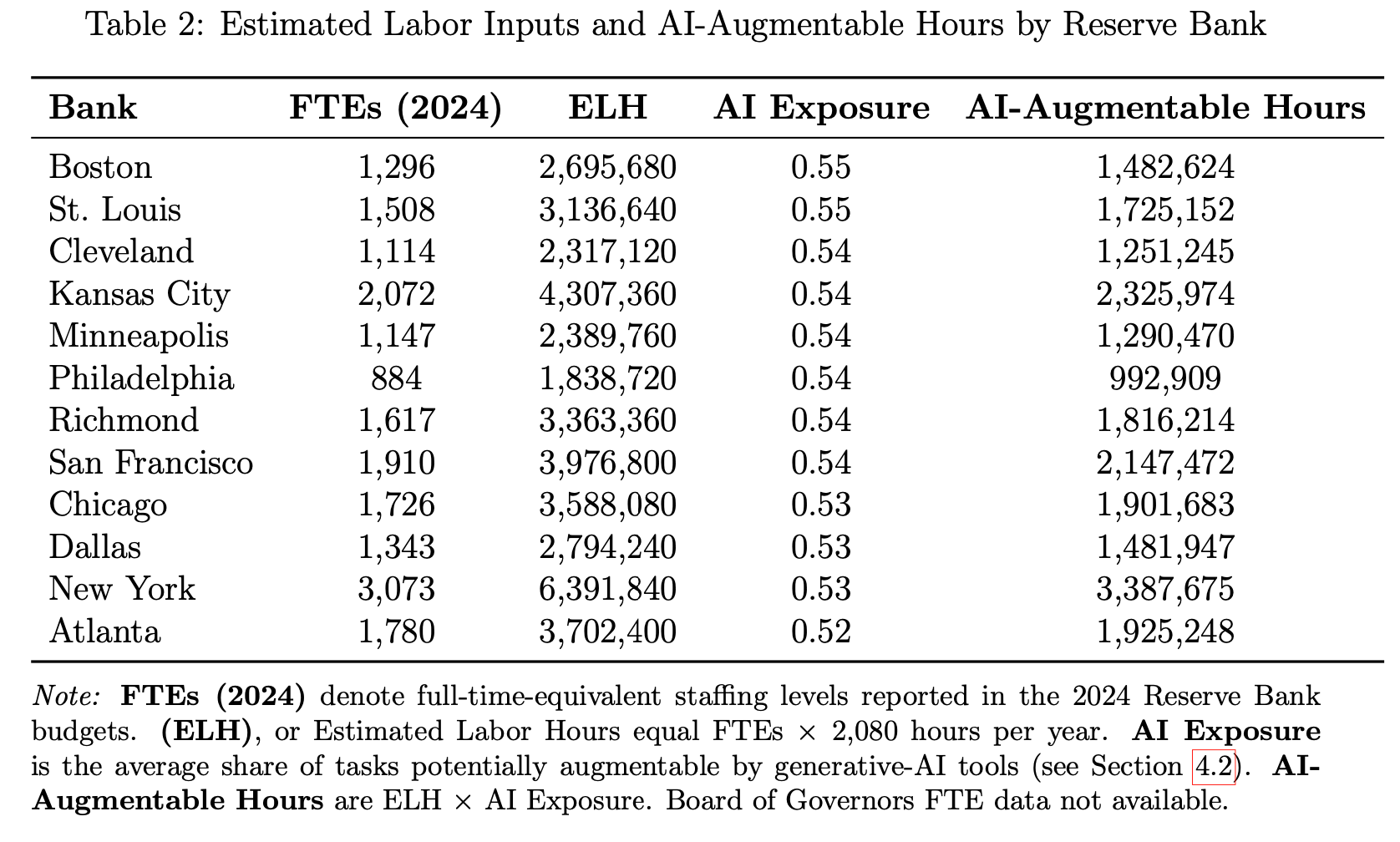
“In addition, rather than depending primarily on external hires, the BIS argues that central banks must cultivate an organizational culture of continuous learning and innovation. This includes establishing dedicated AI training tracks, appointing AI “champions”, and creating cross-functional AI governance bodies that oversee model risk frameworks and audit. Most importantly, the Fed already employs individuals with significant AI research expertise or practical AI-related skills, giving it a strong base on which it could build these internal initiatives.”
“Central banking is approaching a major transformation. Imagine a system that rapidly and continuously collects diverse data, from traditional economic metrics and real-time spending patterns to environmental indicators, delivering immediate insights on growth, inflation, and employment. It instantly evaluates various scenarios to predict policy impacts and conducts ongoing stress tests to identify threats such as cyberattacks, natural disasters, and geopolitical crises, proactively addressing manageable risks before they escalate.”
“Translating this potential into reality hinges on overcoming significant misunderstandings about AI. Nontechnical observers frequently underestimate the rapid pace of AI development, focusing solely on its present capabilities. Technical experts, on the other hand, while deeply familiar with AI’s potential, often overlook organizational and societal barriers to widespread adoption.”
“The realistic and effective adoption of AI requires recognizing that human systems—our rules, behaviors, norms—fundamentally shape technological systems, determining their ultimate form and function (e.g., Orlikowski and Gash, 1994; Lin and Silva, 2005).”
Kazinnik, S., & Brynjolfsson, E. (2025). AI and the Fed (No. w33998). National Bureau of Economic Research.
http://www.nber.org/papers/w33998
Group Sequence Policy Optimization
“its objective is ill-posed”

“In this paper, we identify that the instability of GRPO stems from the fundamental misapplication and invalidation of importance sampling weights in its algorithmic design. This introduces high-variance training noise that progressively accumulates with increased response length and is further amplified by the clipping mechanism, ultimately precipitating model collapse.”
“To address these core limitations, we propose Group Sequence Policy Optimization (GSPO), a new RL algorithm for training large language models. The key innovation of GSPO lies in its theoretically grounded definition of importance ratio based on sequence likelihood (Zheng et al., 2023), aligning with the basic principle of importance sampling. Additionally, GSPO computes the normalized rewards as the advantages of multiple responses to a query, ensuring the alignment between sequence-level rewarding and optimization.”
“Our empirical evaluation demonstrates the significant superiority of GSPO over GRPO in training stability, efficiency, and performance. Critically, GSPO has inherently resolved the stability challenges in the RL training of large Mixture-of-Experts (MoE) models, eliminating the need for complex stabilization strategies, and shows the potential for simplifying RL infrastructure. These merits of GSPO ultimately contributed to the exceptional performance improvements in the latest Qwen3 models. We envision GSPO as a robust and scalable algorithmic foundation that will enable the continued advancement of large-scale RL training with language models.”
“While mechanisms like clipping aim to manage this off-policy discrepancy, we identify a more fundamental issue in GRPO: its objective is ill-posed.”
“Instead, it introduces high-variance noise into the training gradients, which accumulates over long sequences and is exacerbated by the clipping mechanism. We have empirically observed that this can lead to model collapse that is often irreversible.”
Zheng, C., Liu, S., Li, M., Chen, X. H., Yu, B., Gao, C., ... & Lin, J. (2025). Group Sequence Policy Optimization. arXiv preprint arXiv:2507.18071.
https://arxiv.org/abs/2507.18071v1
Building an American TSMC
“Real men have fabs”

“Each American semiconductor company originally built its own semiconductor fabrication plants (also known as foundries) in the US. In the 1990s, Jerry Sanders declared boastfully, “real men have fabs.” But over time, foundry buildout slowed and eventually reversed, as it grew increasingly unfeasible to maintain foundries due to the pressure of exponential adoption and rapid miniaturization. As the market matured, only the largest semiconductor companies could sustain leading internal foundries. Today, Intel remains the only American company that maintains a leading-edge foundry on American soil.”
“The majority of this piece will unpack three options to address this critical vulnerability: do we build an American Semiconductor Manufacturing Company from scratch, borrow it from TSMC’s expertise, or “buy it” from an existing player with the right capabilities? Our conclusion is that there is only one realistic option: Intel is an unavoidable piece of the puzzle to rebuild America’s domestic semiconductor manufacturing capacity.”
“The re-industrialization of a successful Intel Foundry has been stymied by two core forces: (1) the gradual replacement of the traditional engineering-centric culture with a management-centric culture, resulting in inferior fabrication capabilities, and (2) an ongoing conflict of interest between internal fabrication capability and external design partners that Intel has consistently tried to ignore. Only in the last few years has it become readily apparent that something has to change. Intel is staring down the barrel of the innovator’s dilemma, and it no longer has the option of doing nothing.”
“If we fail, we may maintain exceptional chip design leadership, but we’ll continue to be held hostage to a flashpoint in the Taiwan Strait. If we succeed, America regains sovereign control over the computational substrate on which economic growth, military deterrence, and democratic AI all depend.
The question now is whether we are up to the task.”
https://research.contrary.com/deep-dive/building-an-american-tsmc
Building a web search engine from scratch in two months with 3 billion neural embeddings
“LLMs can't and shouldn't memorize all knowledge”

“A simple question I had was: why couldn't a search engine always result in top quality content? Such content may be rare, but the Internet's tail is long, and better quality results should rank higher than the prolific inorganic content and engagement bait you see today.
Another pain point was that search engines often felt underpowered, closer to keyword matching than human-level intelligence.”
“I find that one of the biggest values of neural embeddings is the ability to find great content, insights, and references. These often reside in essays and documentations, and are article-like content. Queries that are just "bookmarks" (e.g. python download windows) or exact phrase matching require a very broad index (including very obscure pages) but also don't leverage intelligence or comprehension; bookmarks could be indexed only by <title> keywords and URL substrings.”
“Despite the rise of LLMs, I think that search will always play a role: LLMs can't and shouldn't memorize all knowledge, using parameters that could be used for more intelligence and capability. Instead, LLMs can offload that to representations of knowledge via these efficient dense indices, which would also mean less hallucinations and more up-to-date information. Perhaps we will have community-maintained open-source local search indices alongside our open-source local models.”
https://blog.wilsonl.in/search-engine/
Self-adaptive reasoning for science
Significant progress in keeping a human in the loop…quite Centauri

“Long-running LLM agents equipped with strong reasoning, planning, and execution skills have the potential to transform scientific discovery with high-impact advancements, such as developing new materials or pharmaceuticals. As these agents become more autonomous, ensuring effective human oversight and clear accountability becomes increasingly important, presenting challenges that must be addressed to unlock their full transformative power. Today’s approaches to long-term reasoning are established during the post-training phase, prior to end-user deployment and typically by the model provider. As a result, the expected actions of these agents are pre-baked by the model developer, offering little to no control from the end user.”
“At Microsoft, we are pioneering a vision for a continually steerable virtual scientist. In line with this vision, we created the ability to have a non-reasoning model develop thought patterns that allow for control and customizability by scientists. Our approach, a cognitive loop via in-situ optimization (CLIO), does not rely on reinforcement learning post-training to develop reasoning patterns yet still yields equivalent performance as demonstrated through our evaluation on Humanity’s Last Exam (HLE).”
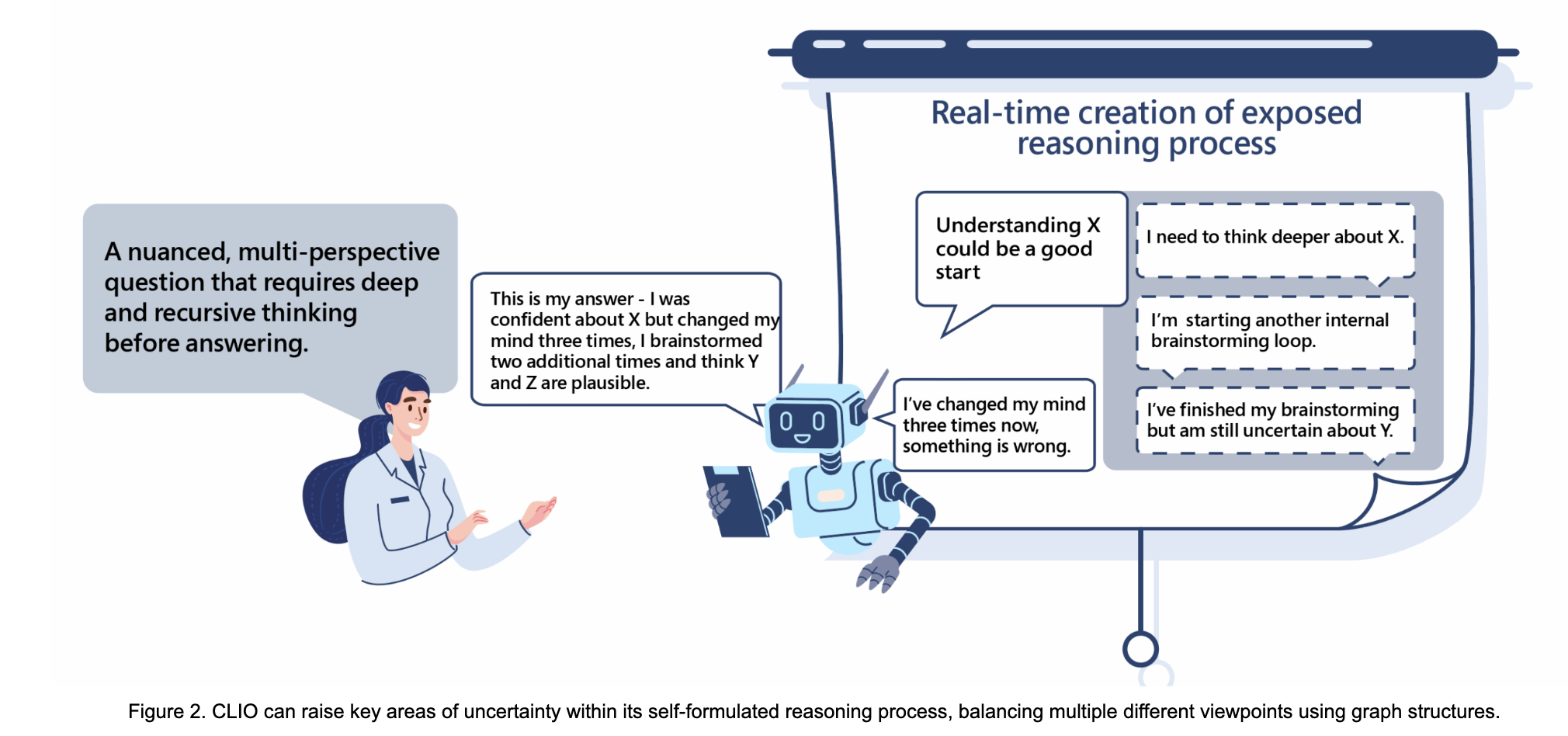
“On the other end of the spectrum, orchestrated reasoning systems tend to oversaturate the user by raising too many flags. We enable prompt-free control knobs within CLIO to set thresholds for raising uncertainty flags. This allows CLIO to flag uncertainty for itself and the end user at the proper point in time. This also enables scientists to revisit CLIO’s reasoning path with critiques, edit beliefs during the reasoning process, and re-execute them from the desired point in time. Ultimately, this builds a foundational level of trust with scientists to use them in a scientifically defensible and rigorous way. “
https://www.microsoft.com/en-us/research/blog/self-adaptive-reasoning-for-science/
Reader Feedback
“What’s really driving the inequality in income?”
Footnotes
Centaur AI is a pretty old concept. It envisions a future where human and artificial intelligence are combined, creating a hybrid approach to creation.
I started calling such people Centauri. And naturally, a fellow data scientist is going to make the connection to Babylon 5 and Peter Jurasik’s epic representation of a galactic decline. Sure, becoming Centauri may end up ruining us in the end. But we’re still at the dawn of the Centauri Empire and what a ride it will be!

Why aren’t there more Centauri? At a recent industry gathering, finally, refreshingly, algorithmic resistance was spoken about openly. I repeated the old meme that Swedish journalists adopted AI well before anybody else in North America because the Swedes had job security. If North American business leaders want to speed AI adoption, perhaps consider the effect of the technology on incentives?
If you ever have to explain incentives, don’t.
Both private and public sectors are made of people. And people explain a lot.
In this edition, there are a few clues as to make it more attractive for people to become Centauri, if they want to.