humans’ collective wisdom is so far still invincible
This week: Digital twins, AI companions, MacGyver, Rowhammer attack, Kimi, Continuous cellular automata
Twin-2K-500: A dataset for building digital twins of over 2,000 people based on their answers to over 500 questions
Would your own twin, genetic or otherwise, ever approach 88% accuracy?
“In sum, there is no publicly available dataset that combines rich psychological profiles, behavioral data, and demographics from a large, representative sample. As a result, researchers often rely on synthetic or proprietary data, which undermines transparency, reliability, and replicability. To address this gap, we assemble and publicly share an extensive dataset for a representative sample of N = 2, 058 people who each answered over 500 questions covering a wide range of demographic questions, psychological scales, cognitive performance questions, economic preferences questions, as well as replications of a wide range of within- and between-subject experiments on heuristics and biases taken from the behavioral economics literature. The data was collected across 4 waves of studies lasting on average 2.42 hour per participant in total. Table 1 gives an overview of the measures collected in each wave and Figure 1 illustrates our overall approach.”
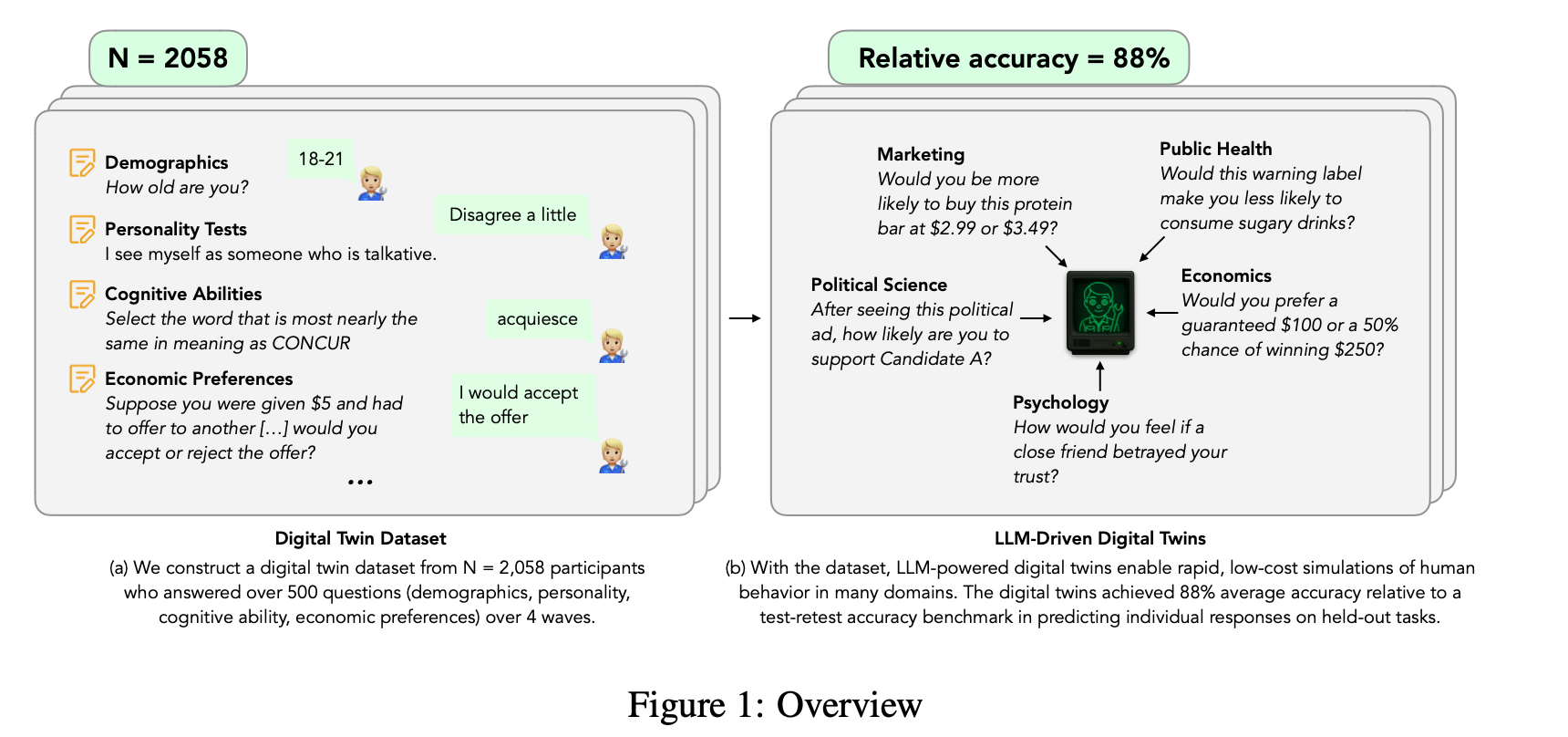
“To construct each digital twin, we begin by merging the original Qualtrics survey files (QSF) with each participant’s raw responses, creating a self-contained JSON record for every individual. This record lists, in order, every question the participant actually encountered, the response options shown, and the answers. We then partition this record into three separate files:
- Persona JSON: Aggregates all non–hold-out content from waves 1-3, used to define the persona.
- **Evaluationanswer-blockJSON:**Containstheparticipant’swave1–3responsestohold-out items, providing the ground truth for evaluating simulation accuracy.
- Retest answer-block JSON: Stores wave 4 responses to those same hold-out items, used solely to compute the human test–retest accuracy benchmark.”
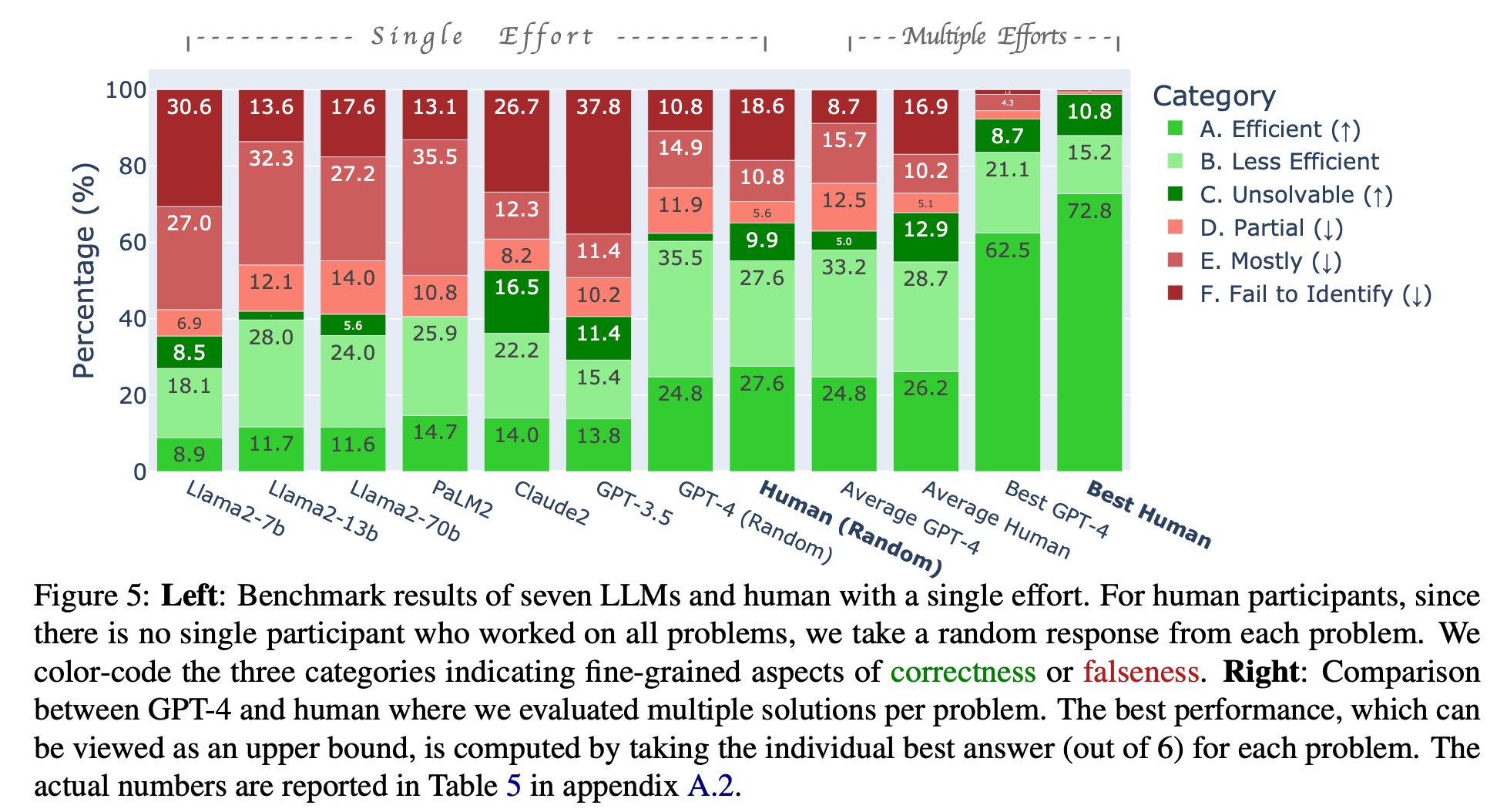
“Figure 2 reports, for each task, the predictive accuracy of the answers simulated by the digital twins, as well as the accuracy of a random benchmark which chooses each answer from a random uniform distribution. On average, across the 17 tasks the accuracy of the digital twin predictions is 71.72%, and the ratio of the digital twin accuracy to the test-retest accuracy is 87.67%. The improvement over the baseline is consistent across all question types, highlighting the value of personalization and LLM-based simulation.”

“These twins predict human behavior with out-of-sample accuracy reaching 87% of the test-retest benchmark. Replication of average treatment effects is generally good, though further research is needed to determine if digital twins can capture non-normative behaviors and reflect the full diversity of political and domain-specific views. The dataset’s focus on the US and social science topics is a potential limitation. Overall, we hope this resource accelerates LLM research and social science applications while being mindful of societal risks such as dehumanization of research and excessive reliance on AI in decision-making.”
Toubia, O., Gui, G. Z., Peng, T., Merlau, D. J., Li, A., & Chen, H. (2025). Twin-2K-500: A dataset for building digital twins of over 2,000 people based on their answers to over 500 questions. arXiv preprint arXiv:2505.17479.
https://arxiv.org/pdf/2505.17479
https://huggingface.co/datasets/LLM-Digital-Twin/Twin-2K-500
AI companions reduce loneliness
Feeling heard
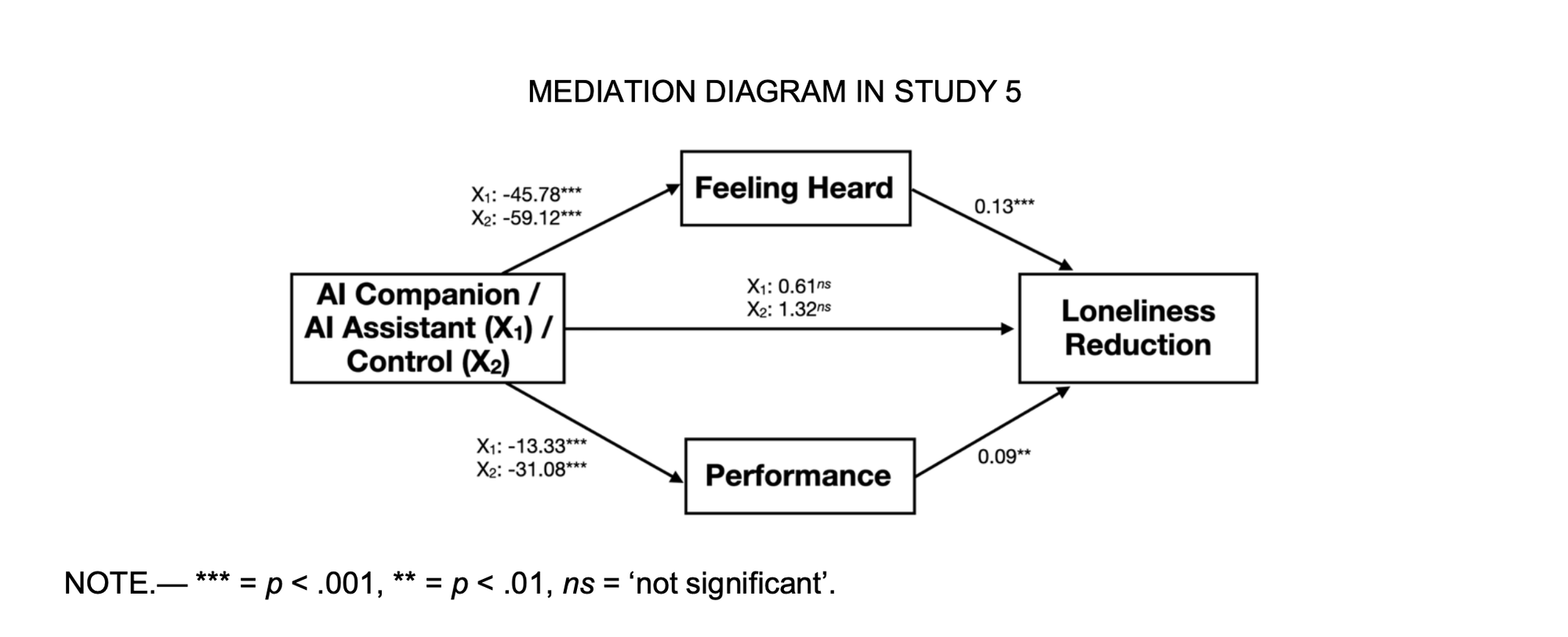
“We considered whether AI companions (applications that utilize AI to provide synthetic social interactions) can reduce loneliness. Study 1 suggests that at least some consumers use AI companion apps to alleviate loneliness, as some expressed loneliness-related thoughts explicitly in naturalistic conversations with a chatbot. Study 2 found that loneliness-related content is present in App Store reviews for a number of companion AIs, and that app reviews mentioning loneliness tend to receive higher ratings, possibly because they effectively alleviate loneliness by making users feel heard. Study 3 found that AI companions successfully alleviate loneliness on par only with interacting with another person, whereas watching YouTube videos or doing nothing do not. Furthermore, participants underestimate the degree to which AI companions improve their loneliness relative to their true feelings after interacting with such AI. Study 4 found that the AI companion reduced loneliness over the course of a week. The most significant reduction occurred on the first day, followed by stable decreases in loneliness on subsequent days. This suggests that the initial interaction with the AI companion has a pronounced impact, which quickly stabilizes over time as participants acclimate to their AI companions. Study 5 provided evidence that feeling heard and performance are significant mediators of the loneliness- alleviating effects of AI companions, and feeling heard is the mediator with higher influence on reducing loneliness compared to performance. Study 6 found that the loneliness alleviating results of AI companions are robust when we ask about loneliness only after the interaction.”
De Freitas, J., Oğuz-Uğuralp, Z., Uğuralp, A. K., & Puntoni, S. (2025). AI companions reduce loneliness. Journal of Consumer Research.
MacGyver: Are Large Language Models Creative Problem Solvers?
“humans’ collective wisdom is so far still invincible”

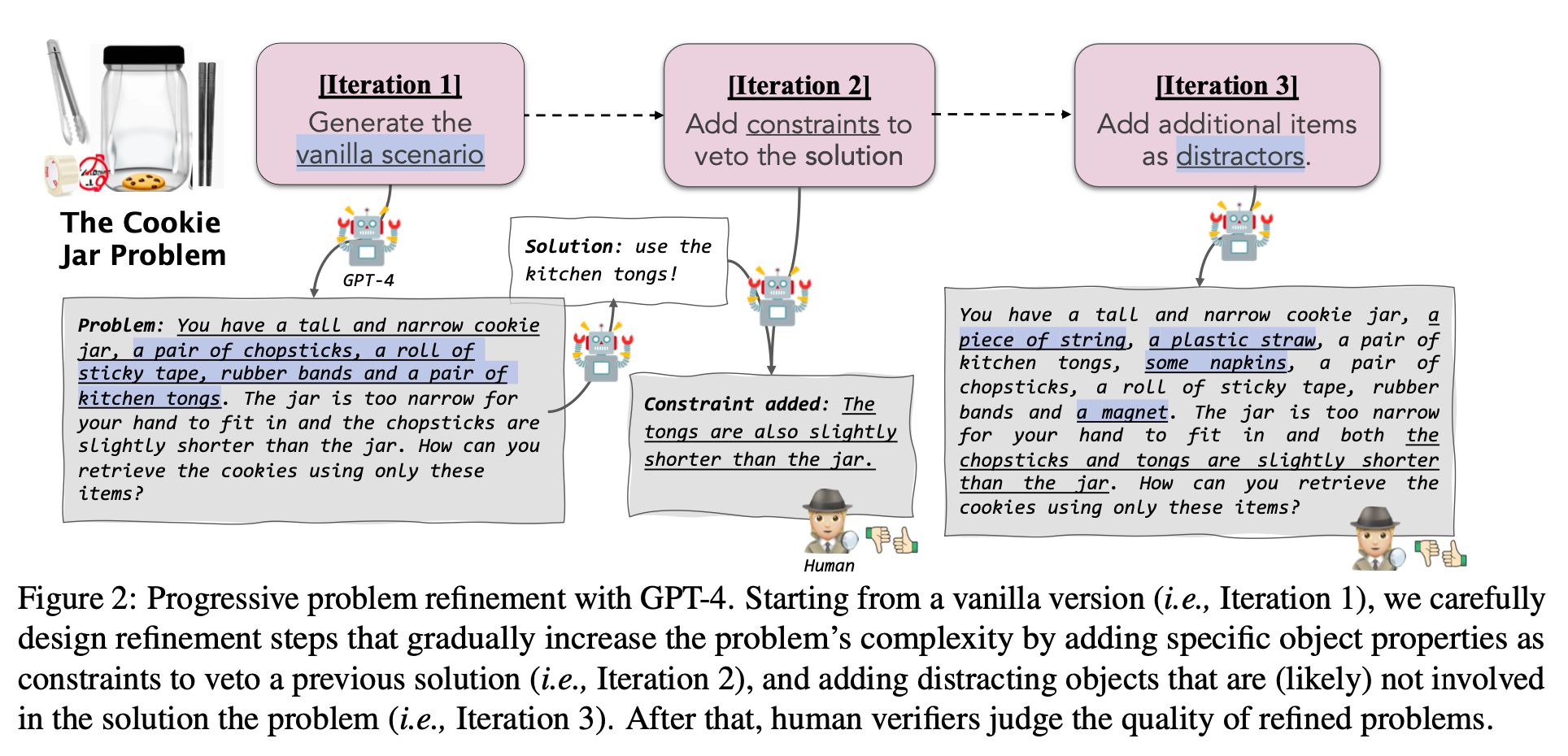
“We explore the creative problem-solving capabilities of modern LLMs in a novel constrained setting. To this end, we create MACGYVER, an automatically generated dataset consisting of over 1,600 real-world problems deliberately designed to trigger innovative usage of objects and necessitate out-of-the-box thinking.”
“Creativity has long been considered the driving force behind modern civilization, and one of the hallmarks of human intelligence (Guilford, 1967b; Hennessey, 1995).”
“To the best of our knowledge, MACGYVER is the first dataset of unconventional everyday problems requiring two key elements of creativity (Guilford, 1967a): divergent thinking (to come up with creative or unconventional usage of objects) and convergent thinking (to accomplish a goal efficiently).”
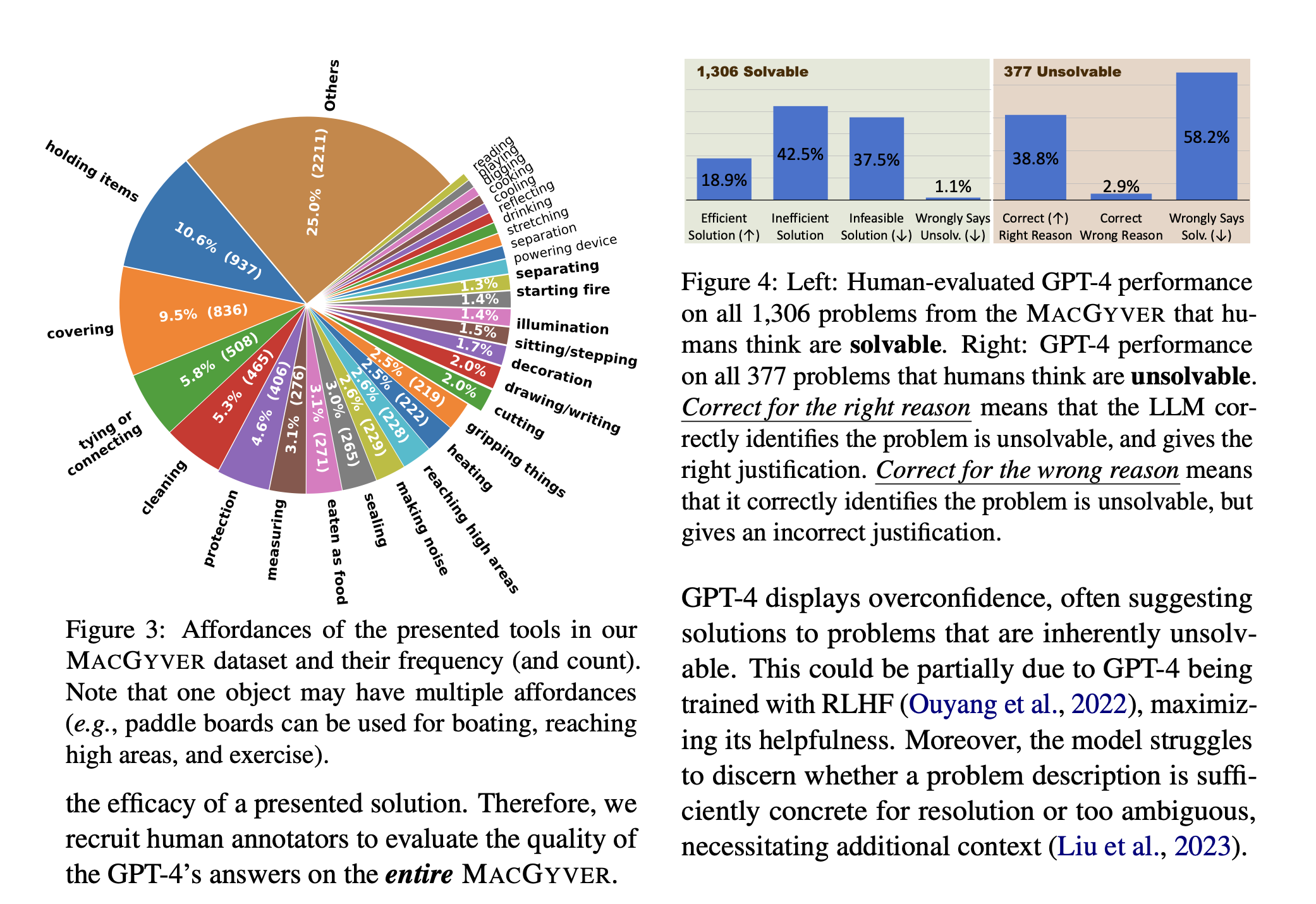
“While the best performing LM, GPT-4, complements the capability of an arbitrary human under certain domain-specific settings (e.g., fixing a hole on the wall), humans’ collective wisdom is so far still invincible.”
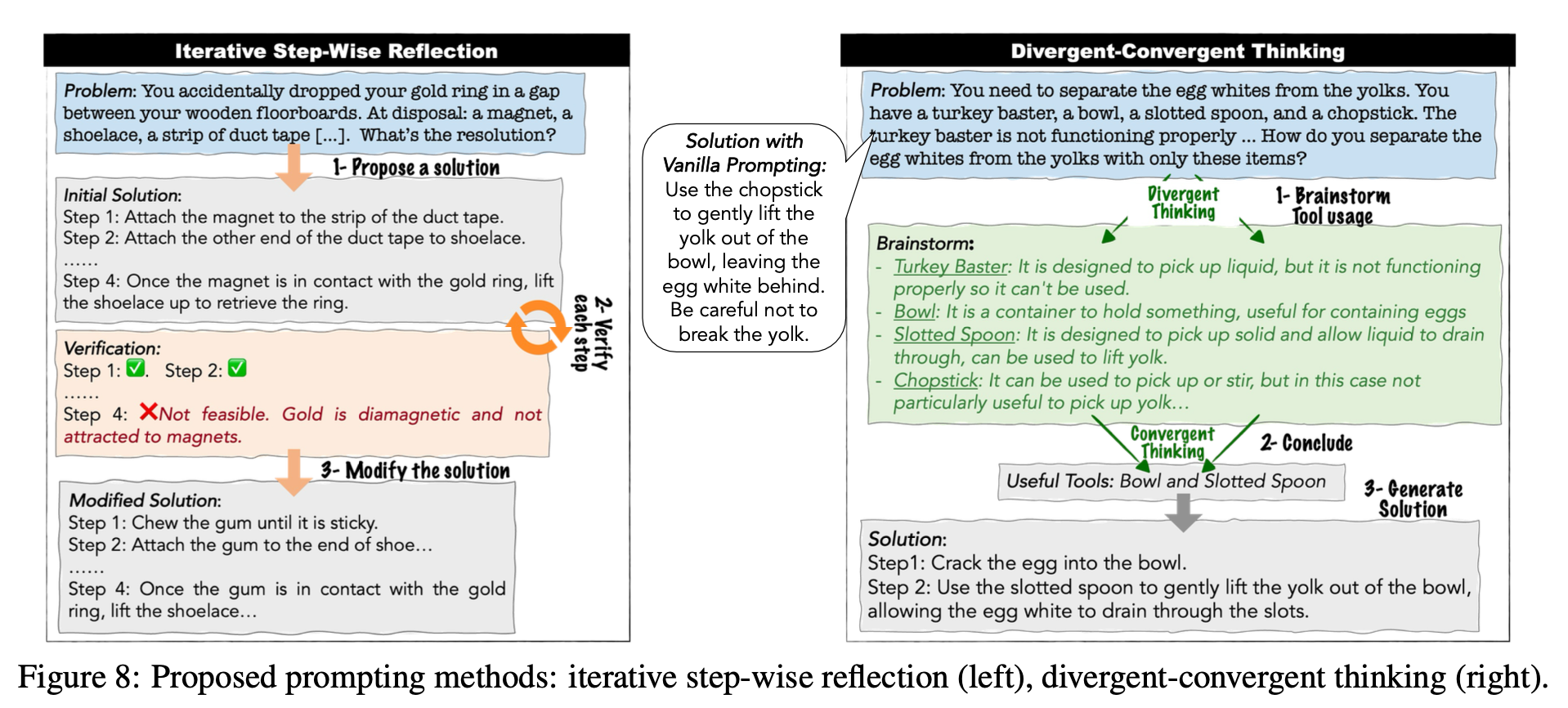
“In the AI-related creativity community, everyday innovation which better reflects the activities that most people may engage in, is under-explored pos- sibly due to the lack of a sizable dataset. For exam- ple, Koivisto and Grassini (2023) study problems with four objects: rope, box, pencil, and candle. We bridge this gap by contributing a dataset with 1,600 everyday problems.”
“Nonetheless, we find LLM capabilities to be complementary to human capabilities under certain domain-specific settings.”
Tian, Y., Ravichander, A., Qin, L., Bras, R. L., Marjieh, R., Peng, N., ... & Brahman, F. (2023). MacGyver: Are Large Language Models Creative Problem Solvers?. arXiv preprint arXiv:2311.09682.
https://arxiv.org/pdf/2311.09682
New Rowhammer attack silently corrupts AI models on GDDR6 Nvidia cards — 'GPUHammer' attack drops AI accuracy from 80% to 0.1% on RTX A6000
“One bit flip is all it takes.”
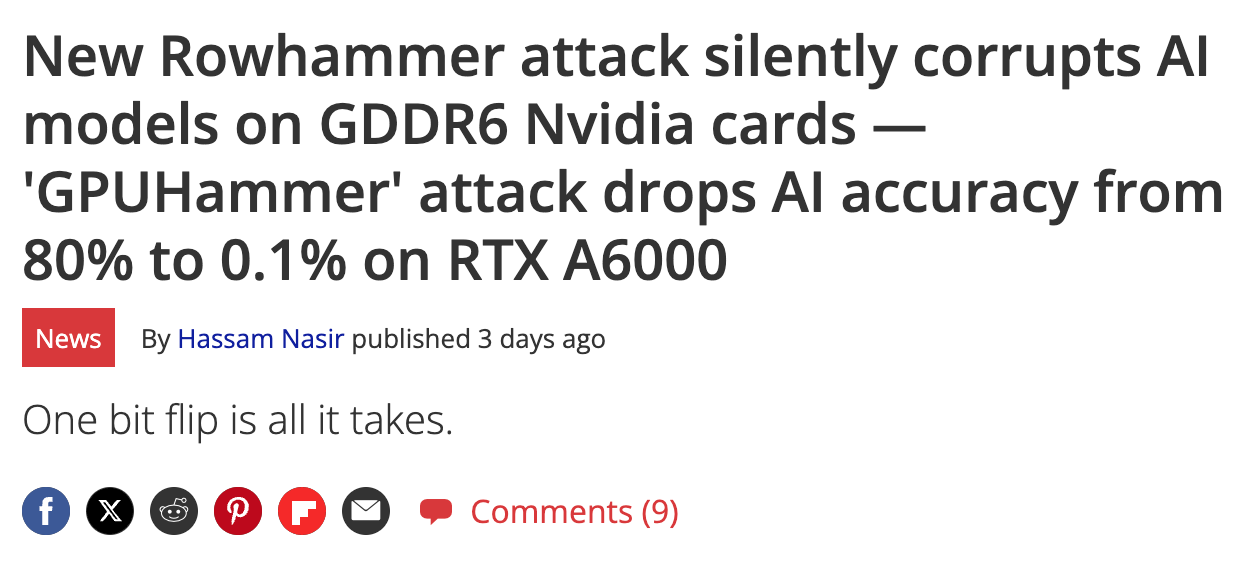
“A group of researchers has discovered a new attack called GPUHammer that can flip bits in the memory of NVIDIA GPUs, quietly corrupting AI models and causing serious damage, without ever touching the actual code or data input.”
“The team behind the discovery, from the University of Toronto, showed how the attack could drop an AI model’s accuracy from 80% to under 1%—just by flipping a single bit in memory. It’s not just theoretical either, as they ran it on a real NVIDIA RTX A6000, using a technique that repeatedly hammers memory cells until one nearby flips, messing with whatever’s stored there.”
“The scary part is that it doesn’t require access to your data. The attacker just needs to share the same GPU in a cloud environment or server, and they could potentially interfere with your workload however they want.”
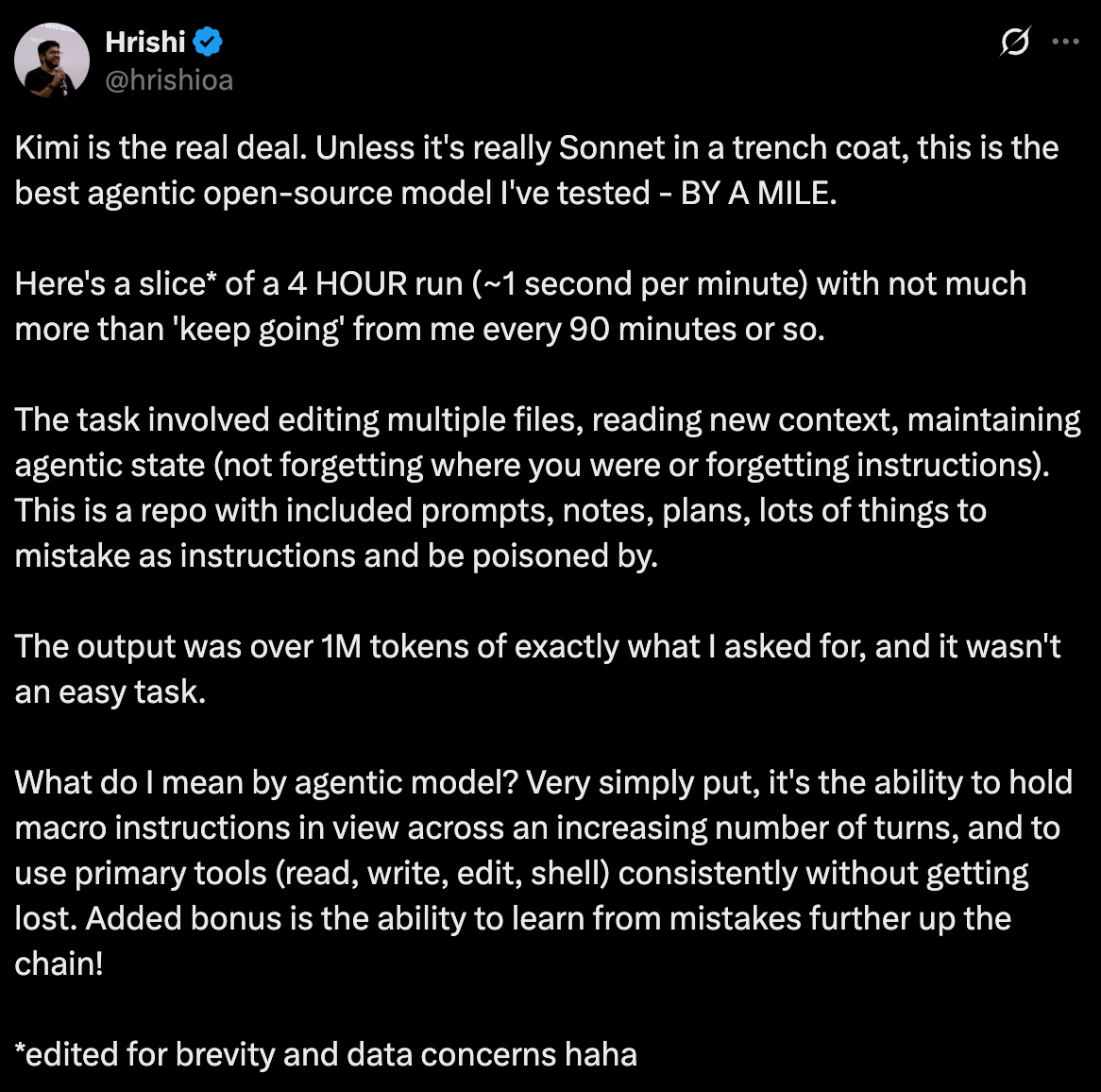
Kimi is the real deal
The ability to learn from mistakes further up the chain
https://x.com/hrishioa/status/1944459901952246152
Continuous Cellular Automata
I’m not sure what to make of it

https://www.wolframscience.com/nks/p158--continuous-cellular-automata/
https://www.mdpi.com/2673-9321/1/2/11
Reader Feedback
“What would it take for an LLM to have a world model?”
Footnotes
The logline “9 minutes could save you 9 months or more on strategic product market fit” is well received and the product delivers on the promise. Too well in fact. What’s the riskiest assumption in any Go To Market strategy? It’s the value proposition! It follows that if you want maximize your odds, you test the riskiest components of the value proposition.
In de-risking my own GTM, I tested the riskiest assumption, and ended up with a classification of blind spots.
Hooray. I got anonymized stories.
In one way, I’m excited to have stumbled onto a problem that auto-generates and reinforces upon itself. It’s like a conscious gordian knot. It’s glorious and quite exquisite.
In another way, on the scale of devastation I felt when I read Arrow Theorem’s (a 7) to when Sanjaya Malakar got voted off American Idol on Country Night in 2007 (a 0.1), I’d put it at a 1. Roughly 10 Sanjaya’s of disappointment.
For my next iteration, it’s about a simple question: Market?
Never miss a single issue
Be the first to know. Subscribe now to get the gatodo newsletter delivered straight to your inbox