Lag Eats Free
This week: Forecasting the economic effects of AI, GEPA, MemCollab, Pokemon, Pi, and the revenge of the data scientist
Forecasting the Economic Effects of AI
Diffusion … … … lags
“The median respondent in each group expects substantial advances in AI capabilities by 2030, small declines in labor force participation consistent with demographic shifts, and an annual GDP growth rate of 2.5%, which exceeds both the typical medium-run (2.0%) and long-run (1.7%) baseline forecasts from government agencies and private-sector forecasters.”
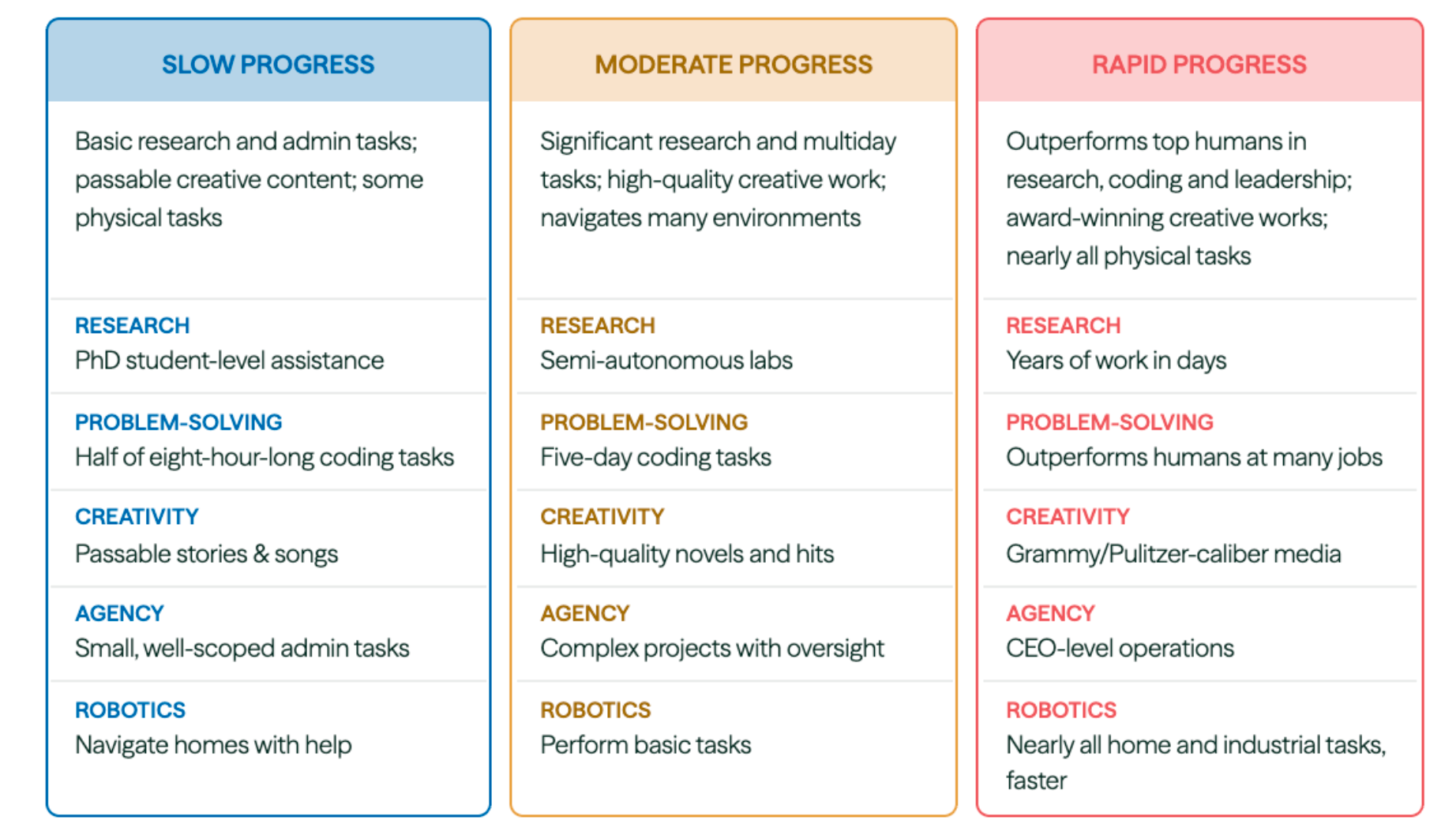
“As we documented in our Section 4 variance decomposition, the primary source of disagree- ment among economists is likely not about whether AI capabilities will advance signifi- cantly—majorities assign meaningful probability to the moderate or rapid scenario—but about how quickly the economy can absorb these potentially transformative capabilities, and what absorption will lead to in terms of economic impacts. Specifically, economists who share similar views on the likelihood of rapid AI progress nevertheless diverge on the likely rate of diffusion, the extent to which new job creation will offset displacement, the degree to which lags will occur between adoption and productivity gains, and how institutional and regulatory responses will shape the transition.”
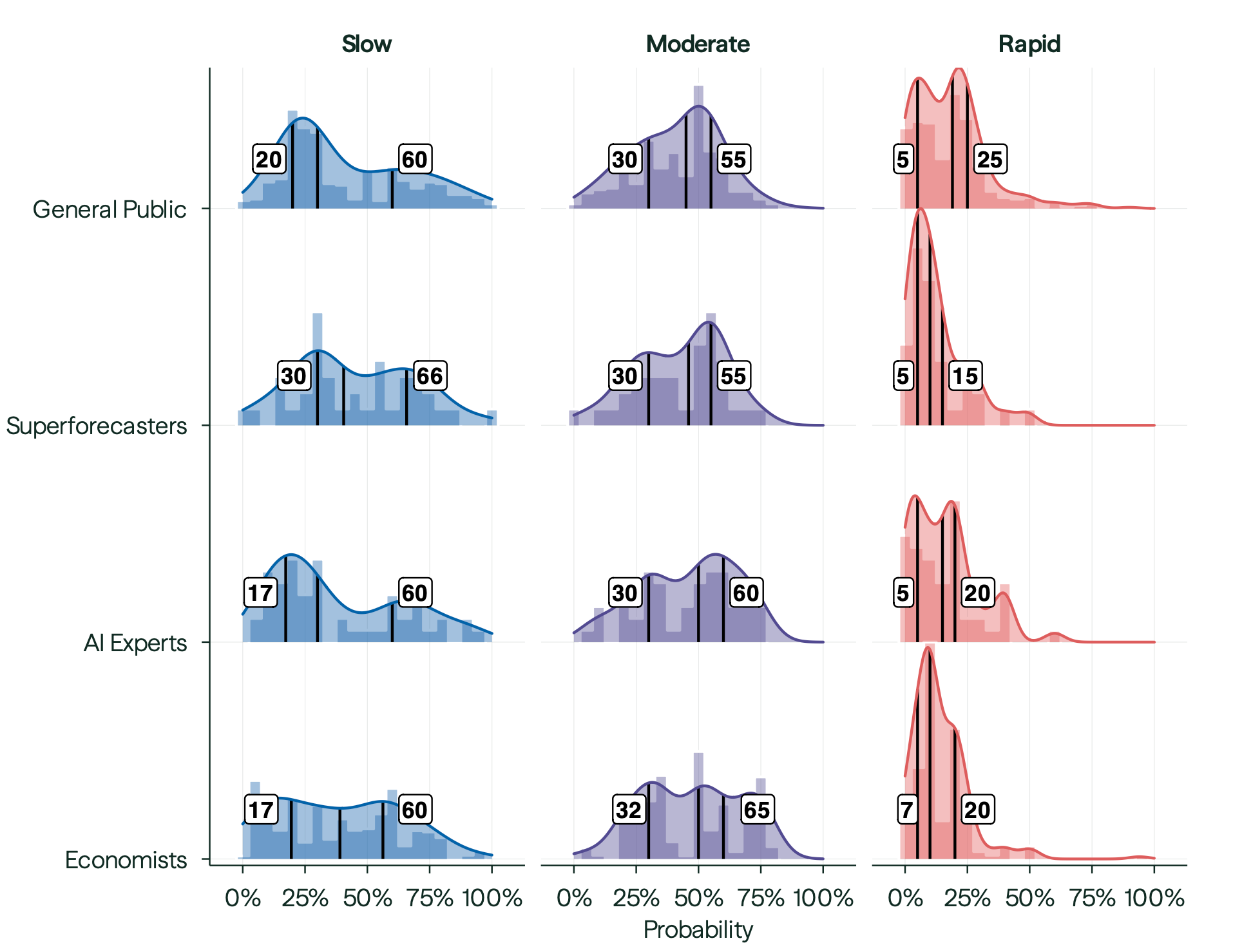
“However, despite disagreement on the magnitude of these effects, the majority of experts agree that their net direction will be to attenuate rather than accelerate AI’s impact on the economy. Indeed, even under the rapid scenario, where AI systems surpass human performance on most cognitive and physical tasks by 2030, experts do not forecast economic outcomes outside the range of historical experience.”
“Instead, their written rationales point repeatedly to diffusion lags, infrastructure bottlenecks, political instability, and demographic headwinds as mechanisms that will likely prevent even highly capable AI from producing unprecedented economic outcomes in the near term.”
Karger et al. (2026) Forecasting the Economic Effects of AI.
GEPA: Reflective Prompt Evolution Can Outperform Reinforcement Learning
Think about what you said. You feel good about that?
“…we introduce GEPA (Genetic-Pareto), a prompt optimizer that thoroughly incorporates natural language reflection to learn high-level rules from trial and error.”
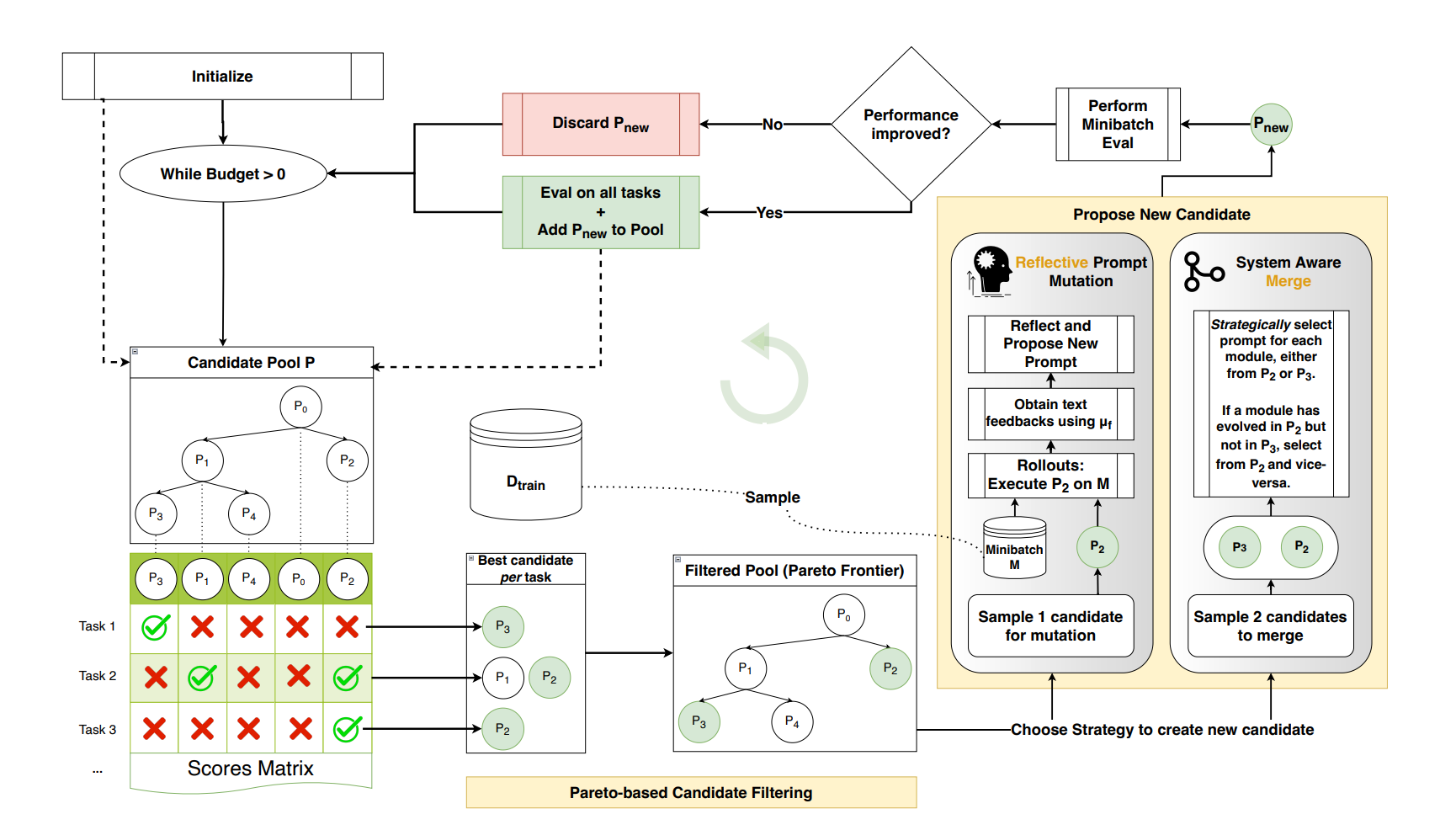
“By explicitly incorporating natural language feedback and maintaining a diverse pool of Pareto optimal candidates, GEPA rapidly adapts AI systems to new tasks. Our results across benchmarks and models suggest that language-based reflection can offer a scalable strategy for optimizing complex real-world AI workflows, especially in resource-constrained settings. GEPA also shows promise as an inference-time search strategy, showing the ability to write code in challenging domains.”
Agrawal, L. A., Tan, S., Soylu, D., Ziems, N., Khare, R., Opsahl-Ong, K., ... & Khattab, O. (2025). Gepa: Reflective prompt evolution can outperform reinforcement learning. arXiv preprint arXiv:2507.19457.
https://arxiv.org/abs/2507.19457
MemCollab: Cross-Agent Memory Collaboration via Contrastive Trajectory Distillation
There are bound to be bounded arguments about what’s in and out of bounds
“In modern deployments with heterogeneous agents, a natural question arises: can a single memory system be shared across different models?”
“Such memory can be reused across heterogeneous models while outperforming memory distilled from a model’s own trajectories (Figure 1).”
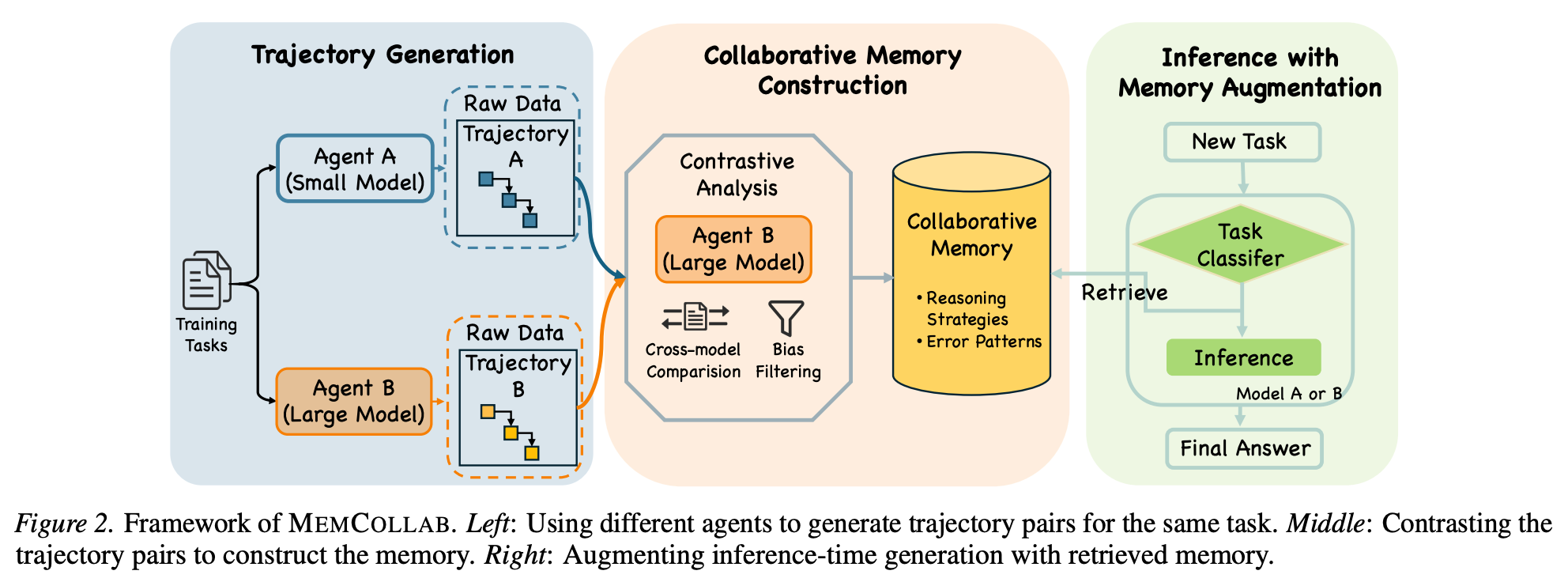
“…we propose MEMCOLLAB, a collaborative memory framework that constructs agent-agnostic memory by contrasting reasoning trajectories generated by different agents on the same task. This contrastive process distills abstract reasoning constraints that capture shared task-level invariants while suppressing agent-specific artifacts. We further introduce a task-aware retrieval mechanism that conditions memory access on task category, ensuring that only relevant constraints are used at inference time.”
Chang, Y., Wu, Y., Wu, Q., & Lin, L. (2026). MemCollab: Cross-Agent Memory Collaboration via Contrastive Trajectory Distillation. arXiv preprint arXiv:2603.23234.
https://arxiv.org/abs/2603.23234
Pokemon Agent
What agents really want
“AI-powered Pokemon gameplay agent with headless emulation, REST API, and live dashboard. Works with any LLM.”
https://github.com/NousResearch/pokemon-agent
Pi Interview Tool
Fascinating approach!
“A custom tool for pi-agent that opens an interactive form to gather user responses to clarification questions. On macOS, uses Glimpse to render in a native WKWebView window; falls back to a browser tab on other platforms.”
https://github.com/nicobailon/pi-interview-tool
The Revenge of the Data Scientist
We’re not even mad though
“What I want to convince you of is that a large portion of the harness is data science.”

“The second pitfall is unverified judges. A lot of teams use an LLM as a judge to figure out whether their AI is working. Most of the time, nobody has a good answer to “how do you trust the judge?””
“The second is metric design. Teams bundle entire rubrics into a single LLM call and default to 1-5 Likert scales. A data scientist would reduce complexity, make each metric actionable, and tie it to a business outcome. Replace subjective scales with binary pass/fail on scoped criteria. Likert scales hide ambiguity and kick the can down the road on hard decisions about system performance.”

“Always look at the data.”
https://hamel.dev/blog/posts/revenge/
Reader Feedback
“Are self-evolving LLM’s dangerous?”
Footnotes
Thank you for sending over companies promising Digital Twin of Consumers (DTOC) technology! I appreciate it and learn a lot.
One firm simultaneously promises both “market research with the same level of accuracy” as traditional market research and “88% similarity score average match between synthetic and traditional research.”
Interesting, baffling, claims!
Assuming the best of intentions:
People, themselves, aren’t consistent. Ask them the same battery of questions a day apart and observe the difference. If you know, you know. And what they express in market research doesn’t always align with what they do. If you know you know. And then synthetics diverge from organic behaviour. If you’ve studied enough of them, you know.
Synthetic behaviour can be concealed from even the experienced data practitioner.
I’ve made the choice not to.
I understand the short-run commercial impulse. Such claims spark immediate suspicion or immediate relief: “FINALLY! A DTOC platform that delivers accurate results!”
And I suppose where there is a desire to believe something, there are those who will form such a belief. After all, we make synthetic twins believe all sorts of things in order to modify their decision boundaries. We help organic people to believe all sorts of things in order to modify their decision boundaries.
I continue to be in awe by make-believe and what people believe.
And pretend to believe.

Never miss a single issue
Be the first to know. Subscribe now to get the gatodo newsletter delivered straight to your inbox