Looped Language Models
This week: Looped Language Models, less superhuman, privacy, attribute importance, political connections, musky drama, economic lit search
Scaling Latent Reasoning via Looped Language Models
A third scaling axis?
“We present and open-source Ouro, named after the recursive Ouroboros, a family of pre-trained Looped Language Models (LoopLM) that instead build reasoning into the pre-training phase through (i) iterative computation in latent space, (ii) an entropy-regularized objective for learned depth allocation, and (iii) scaling to 7.7T tokens.”
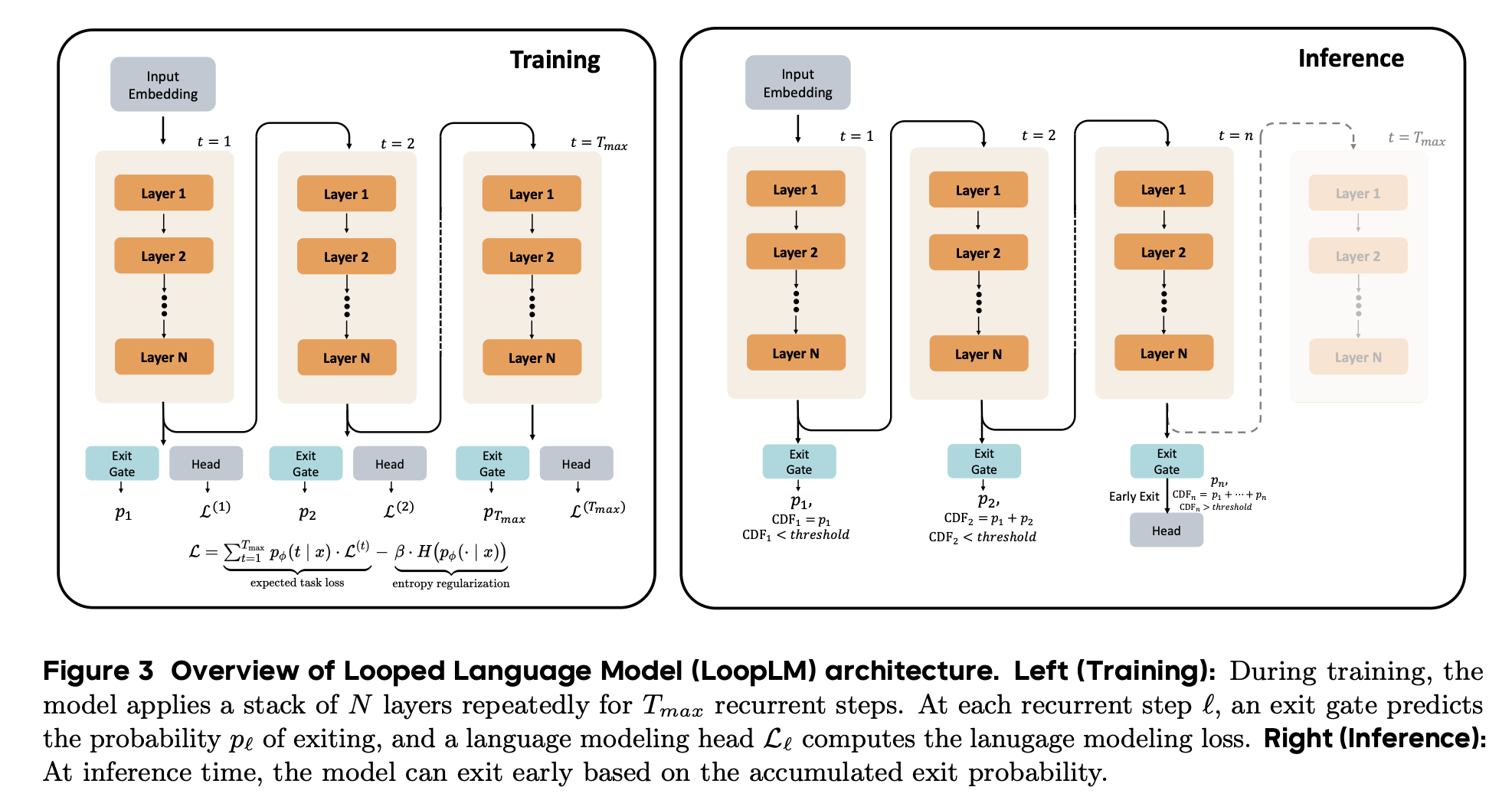
“Why LoopLMs achieve far better performance when the parameter counts do not increase? Although potential enhanced reasoning capabilities were observed in [7], the source of the advantage remains unclear.”
“Beyond performance, the LoopLM architecture exhibits unique properties: its iterative refinement process provides a causally faithful reasoning trace, mitigating the post-hoc rationalization issues seen in standard CoT, and its safety alignment uniquely improves with increased recurrent steps, even when extrapolating. This work establishes iterative latent computation as a critical third scaling axis beyond parameters and data.”
Zhu, R. J., Wang, Z., Hua, K., Zhang, T., Li, Z., Que, H., ... & Eshraghian, J. (2025). Scaling Latent Reasoning via Looped Language Models. arXiv preprint arXiv:2510.25741.
https://arxiv.org/abs/2510.25741
To model human linguistic prediction, make LLMs less superhuman
So 2022 was the year huh?
“Human language comprehension is a rapid and efficient process. A key reason for this is the highly predictive nature of this process: we do not wait for the next word to start constructing the meaning of the sentence, but rather do so based on our prediction of upcoming words.”
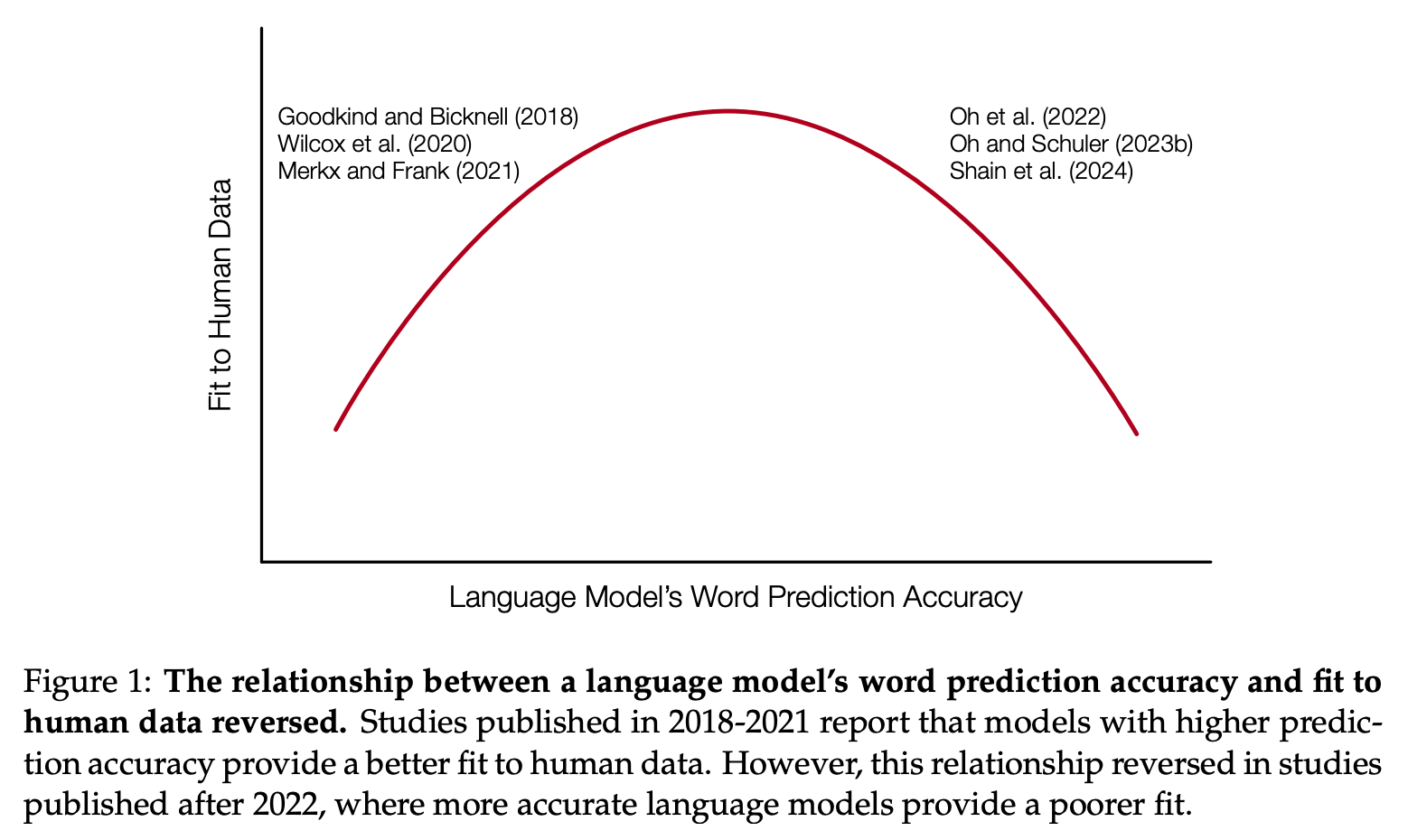
“While predictability estimates from early neural language models showed promise in predicting human behavioral measurements of linguistic prediction, in the last few years mainstream LLMs have become much more accurate than humans at next-word prediction, leading to an increasing misalignment in prediction between LLMs and humans. We argue that this growing superhumanness of LLMs is due to their superior long-term memory of training examples and short-term memory of previous words in the text. To address this issue, we have advocated for creating language models with human-like long-term and short-term memory through the use of alternative training procedures and neural network architectures, and argued that new human experiments should be conducted to benchmark progress on this front.”
Oh, B. D., & Linzen, T. (2025). To model human linguistic prediction, make LLMs less superhuman. arXiv preprint arXiv:2510.05141.
https://arxiv.org/abs/2510.05141
User Privacy and Large Language Models: An Analysis of Frontier Developers' Privacy Policies
It’s mixed…not a great leading indicator for social license
“This paper analyzes the privacy policies of six U.S. frontier AI developers to understand how they use their users’ chats to train models.”
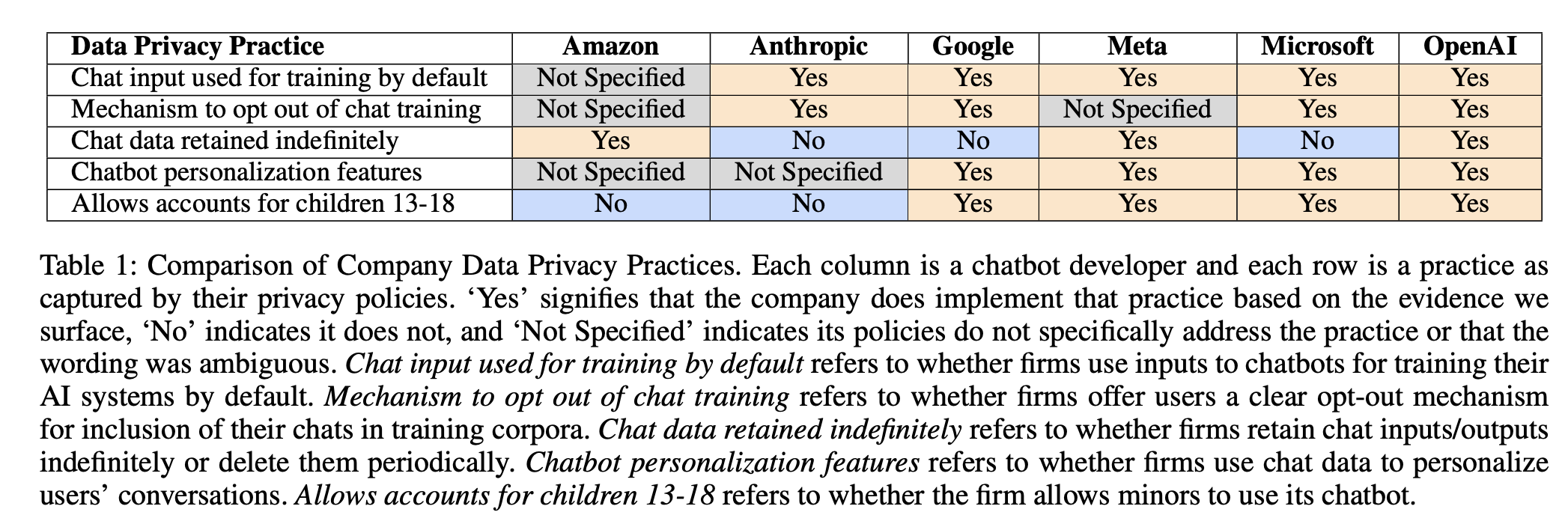
“We analyzed 28 documents across six chatbot developers, including privacy policies, linked sub-policies, and associated FAQs and guidance accessible from chat interfaces.”
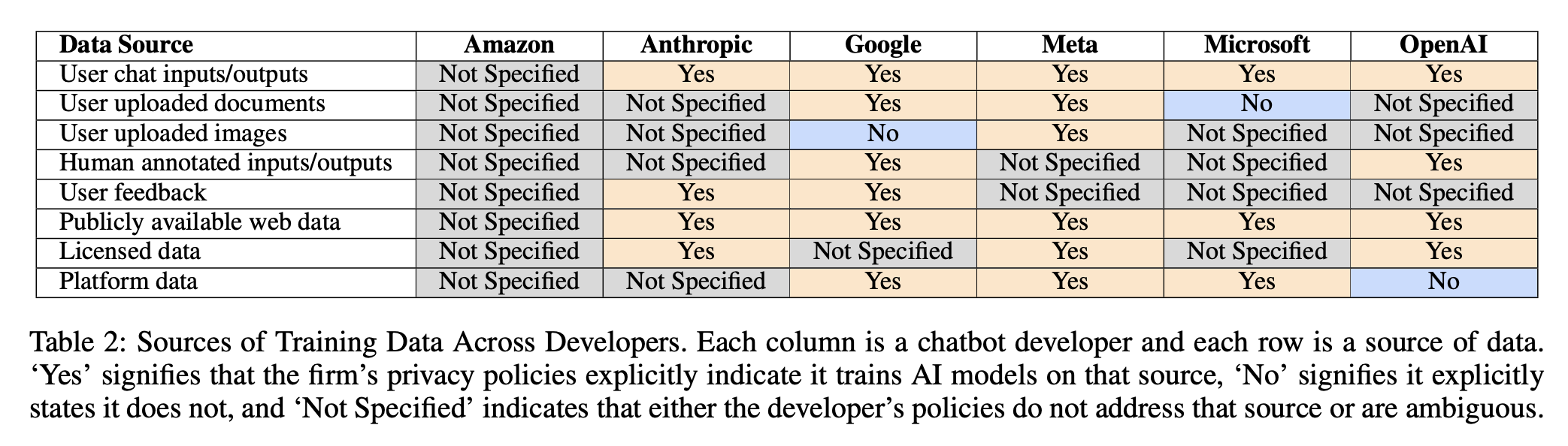
“Each of the major platforms have, at best, a poor track record with respect to responsible use of consumers’ personal data for non-AI related purposes. While fully analyzing our findings within the framework of GDPR is out of scope for this paper, it is worth noting that of the companies that referenced GDPR in their policies, all made claims to legitimate interest as the basis for their data collection.”
“If people believe they are being exploited and manipulated for their data to benefit tech companies above all, then the public will be reluctant to accept the tradeoffs no matter the potential societal gain.”
King, J., Klyman, K., Capstick, E., Saade, T., & Hsieh, V. (2025, October). User Privacy and Large Language Models: An Analysis of Frontier Developers’ Privacy Policies. In Proceedings of the AAAI/ACM Conference on AI, Ethics, and Society (Vol. 8, No. 2, pp. 1465-1477).
https://arxiv.org/abs/2509.05382
Communicating Attribute Importance Under Competition
When it’s the competitors’ best interests to frame honestly
“We analyze a situation where two firms each receive a noisy signal about the true attribute importance and communicate to consumers through cheap-talk messages. Following these communications, consumers decide whether to incur a cost to explore the category by visiting stores. Our findings reveal a truthful equilibrium where firms honestly report their received signals. In this equilibrium, firms can can credibly convey information about the more important attribute if their messages align, thereby encouraging store visits and purchase. Interestingly, firms may still find it advantageous to truthfully highlight an attribute, even if it doesn’t align with their competitive advantage. Moreover, we show that without competition (i.e., a single firm communicating), this truthful equilibrium does not exist.”
“To prevent consumers from disengaging from the product category, it is in the common interest of the firms in the category to provide consumers with guidance on the significance of key attributes, helping to simplify decision-making and potentially increasing the total demand for the product category.”
“Truthful messages increase the likelihood of consistent consumer messages, clarifying attribute importance and enhancing consumer beliefs. This encourages consumers to engage more deeply with the product category, which they might otherwise avoid, making both firms better off. Conversely, if a firm misrepresents its competitive attribute, it may likely to lead to inconsistent messages between firms, creating consumer confusion about which attributes are important. This misalignment can deter consumer interaction with the product category, ultimately harming both firms.”
Lee, J. Y., Shin, J., & Yu, J. (2025). Communicating attribute importance under competition. Marketing Science.
https://papers.ssrn.com/sol3/Delivery.cfm?abstractid=4990162
Beyond political connections: a measurement model approach to estimating firm-level political influence in 41 countries
General bribery
“Importantly, our approach allows us to calibrate a measure of influence and to estimate its distribution across representative samples of companies. We believe this gives us the novel chance to see how political influence moves with underlying governance measures.”
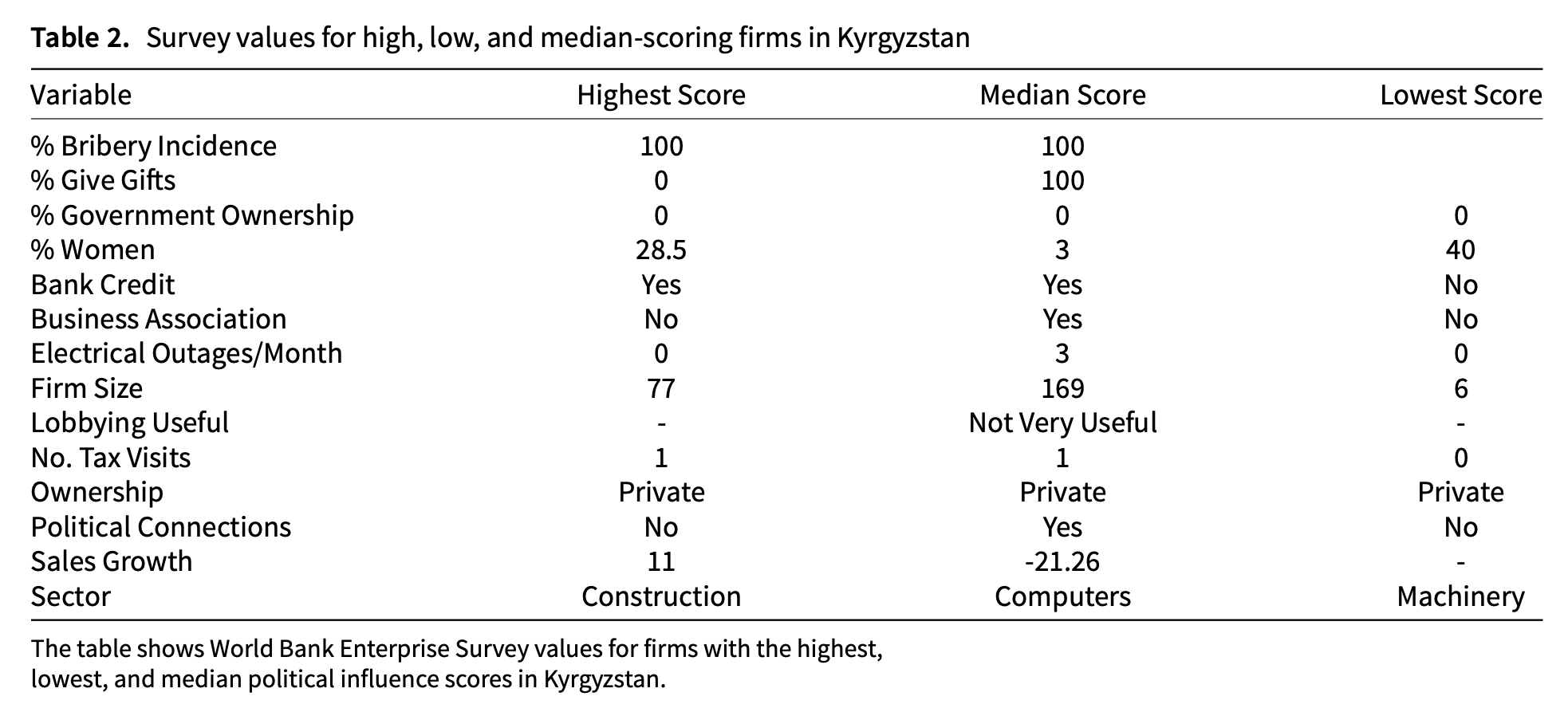
“Our findings confirm what to many may be intuitive: for example, that influence may be higher across the board in countries with poorer governance, as firms may find that such influence is both necessary and available. But we also uncover what we believe to be informative patterns that are new to the literature, including, for instance, that the spread of influence within a country increases at higher levels of governance, a finding we explain by the higher cost of entry of gaining influence in environments where firms must reasonably compete with other interests, including the public’s.”
“The end result is that poorer governance has a compressing effect, while improved governance widens a country’s relative distribution of influence scores. This may seem counterintuitive, as often political advantage is framed as influence doled out to a select few firms or interests. However, in the framing that we laid out at the beginning of the paper, these relationships can be squarely understood. If, as governance improves, one would expect openness and the balancing of interests (including the public writ large), so too would one anticipate higher entry and transaction costs to exert political influence. To generalize, the conceptual framework laid out at the beginning of the paper seems to undergird a finding in the data itself: open, transparent, and pluralistic governance renders political influence more expensive, resulting in fewer firms exerting such influence, and a broader distance between the most and least influential.”
Francis, D. C., & Kubinec, R. (2022). Beyond Political Connections: A Measurement Model Approach to Estimating Firm-levelPolitical Influence in 41 Economies (No. 10119). The World Bank.
Musk V. Altman, ILYA SUTSKEVER October 01, 2025
“Check yourself”



Economic Literature Search
Very cool
https://paulgp.com/econlit-pipeline/search.html
Reader Feedback
“Is anybody truly conscious of the research steering, or is it just an artifact of incentives?”
Footnotes
The workflow, from starting a scenario to interpreting the data, isn’t linear.
Typically, when you get a survey dataset for secondary analysis, you get what you get. There is no travelling back in time to ask that group just one more question. It is what it is.
Because we’re collapsing the cost of asking again and again, the process becomes iterative.
It’s how a lot of the discovery interviews have gone. Somebody will ask about mothers, only to clarify they meant mothers with children under the age of 4. With dogs. No, wait, a purebred dog. But no cat. It’s neat to listen to how people come up salient dimensions about their customers on the fly.
It’s how some of the best qualitative researchers work. They do their first group in the morning, reflect, and try asking slightly different what-if’s in the afternoon or the next day.
Incorporating iteration hasn’t necessarily been trivial.
Stay tuned.
Never miss a single issue
Be the first to know. Subscribe now to get the gatodo newsletter delivered straight to your inbox