Moloch’s Bargain for AI
This week: Using LLMs for market research, better pricing bandits, aging as a loss of goal-directedness, verbalized sampling, giving a damn, moloch’s bargain, radical numerics
Using LLMs for Market Research
Cucumber Toothpaste
“Existing tools for market research, such as conjoint studies, focus groups, and proprietary data sets can be expensive. If LLMs can generate responses that are consistent with existing studies on human subjects, then they may also be able to serve as a fast and low-cost method of supplementing the information typically generated by conjoint studies and other customer surveys.”
“In this context, “new” can either refer to products/features for which the firm has little historical information or to innovative features which have never been created before. Moreover, marketers often care both about the preferences of a generic market customer and about the segments of the market they expect to target. With these use cases in mind, we design five surveys of human participants that allow us to isolate the information set of a hypothetical market researcher and to explore the performance of GPT in each case. We begin by studying GPT’s ability to simulate consumer preferences in settings where the researcher has no prior information about the product category, and then add multiple levels and forms of information about the products and customers of interest, which come from our human surveys.”
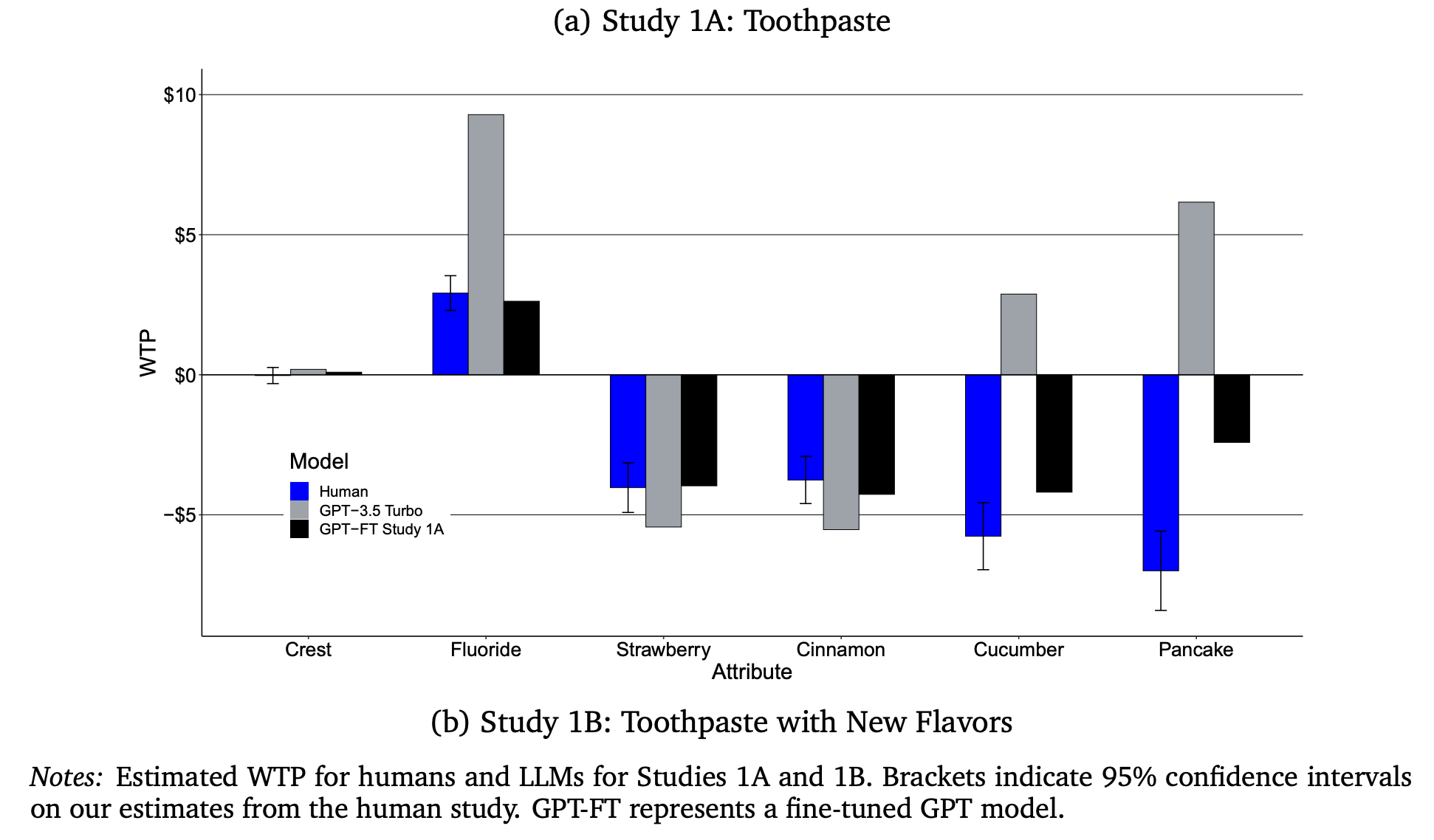
“Overall, the resulting WTP estimates are realistic in magnitude. In particular, we show that a conjoint-like approach to preference estimation yields results that are strikingly similar to those found in a recent survey of real consumers conducted by Fong et al. (2023), as well as to additional human surveys we conduct. Furthermore, we find that augmenting GPT with data from human surveys improves not only GPT’s ability to respond consistently with those surveys but, remarkably, to match separate human surveys on preferences for new product features. In contrast, applying this approach to different product categories does not yield more aligned results from GPT.”
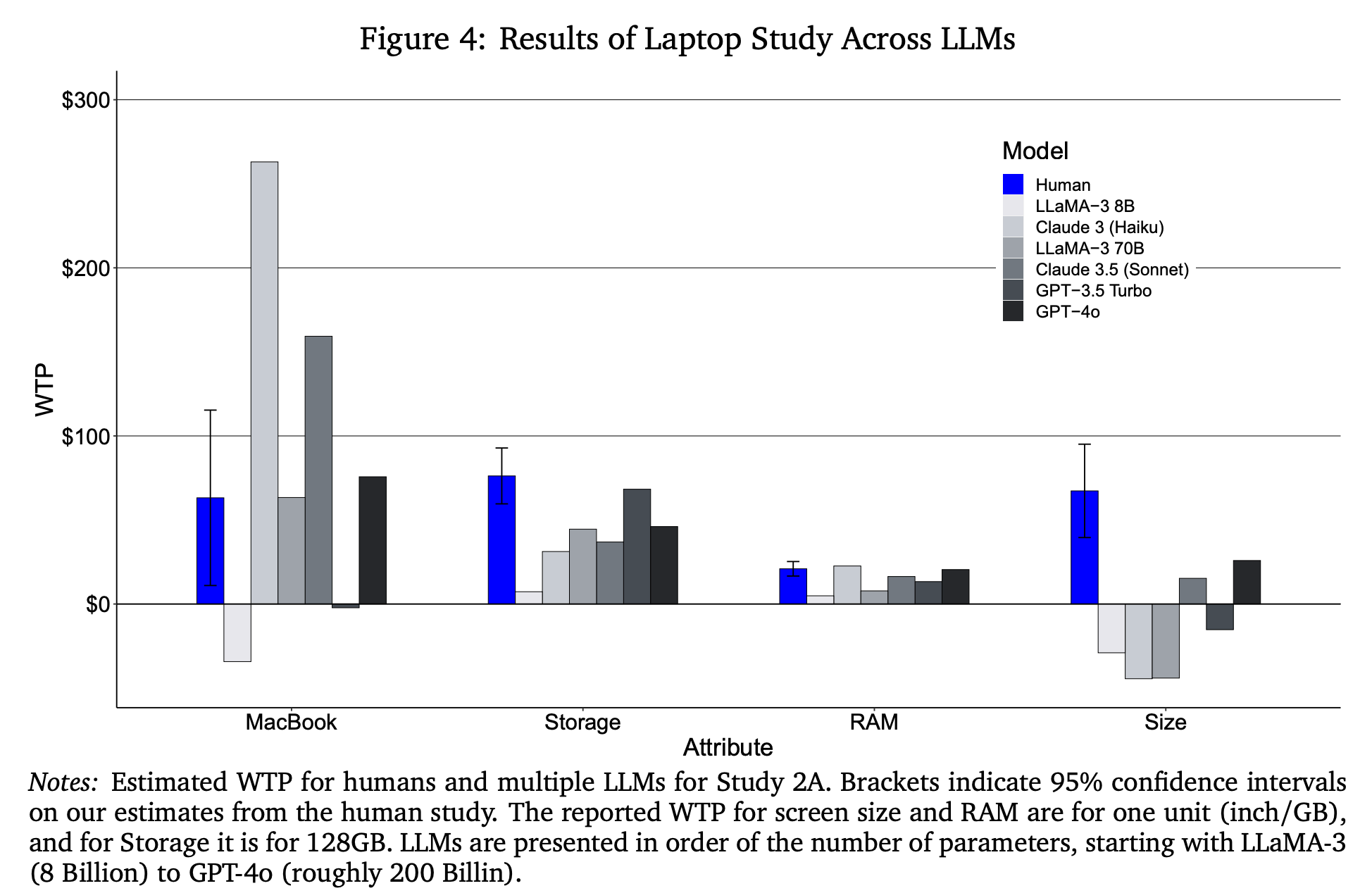
“We focus on the specific problem of estimating WTP for product attributes, a task that often falls to market researchers. To calculate WTP for the attributes we study, we recover preferences for attributes and for prices using the conjoint analysis paradigm.”
“However, it struggled to extrapolate to product categories outside of the fine-tuning data, and fine-tuning in this context worsened GPT’s performance. We also saw mixed results when we studied customer heterogeneity, where fine-tuning often improved GPT’s alignment with human responses on average but was unable to generate comparable heterogeneity. We envision marketers using our approach to help them test out and narrow down new feature ideas before testing them with humans, as opposed to replacing their study subjects with LLMs.”
Brand, J., Israeli, A., & Ngwe, D. (2023). Using LLMs for Market Research (Harvard Business School Marketing Unit Working Paper No. 23-062). Social Science Research Network. https://doi. org/10.2139/ssrn, 4395751.
https://papers.ssrn.com/sol3/Papers.cfm?abstract_id=4395751
Nonparametric Pricing Bandits Leveraging Informational Externalities to Learn the Demand Curve
Does it ever minimize regret!
“We propose a new method based on reinforcement learning using multi-armed bandits (MABs) for pricing by efficiently learning an unknown demand curve. Our algorithm is a nonparametric method which incorporates microeconomic theory into Gaussian process Thompson sampling. Specifically, we impose weak restrictions on the monotonicity of demand, creating informational externalities between the outcomes of arms in the MAB.”
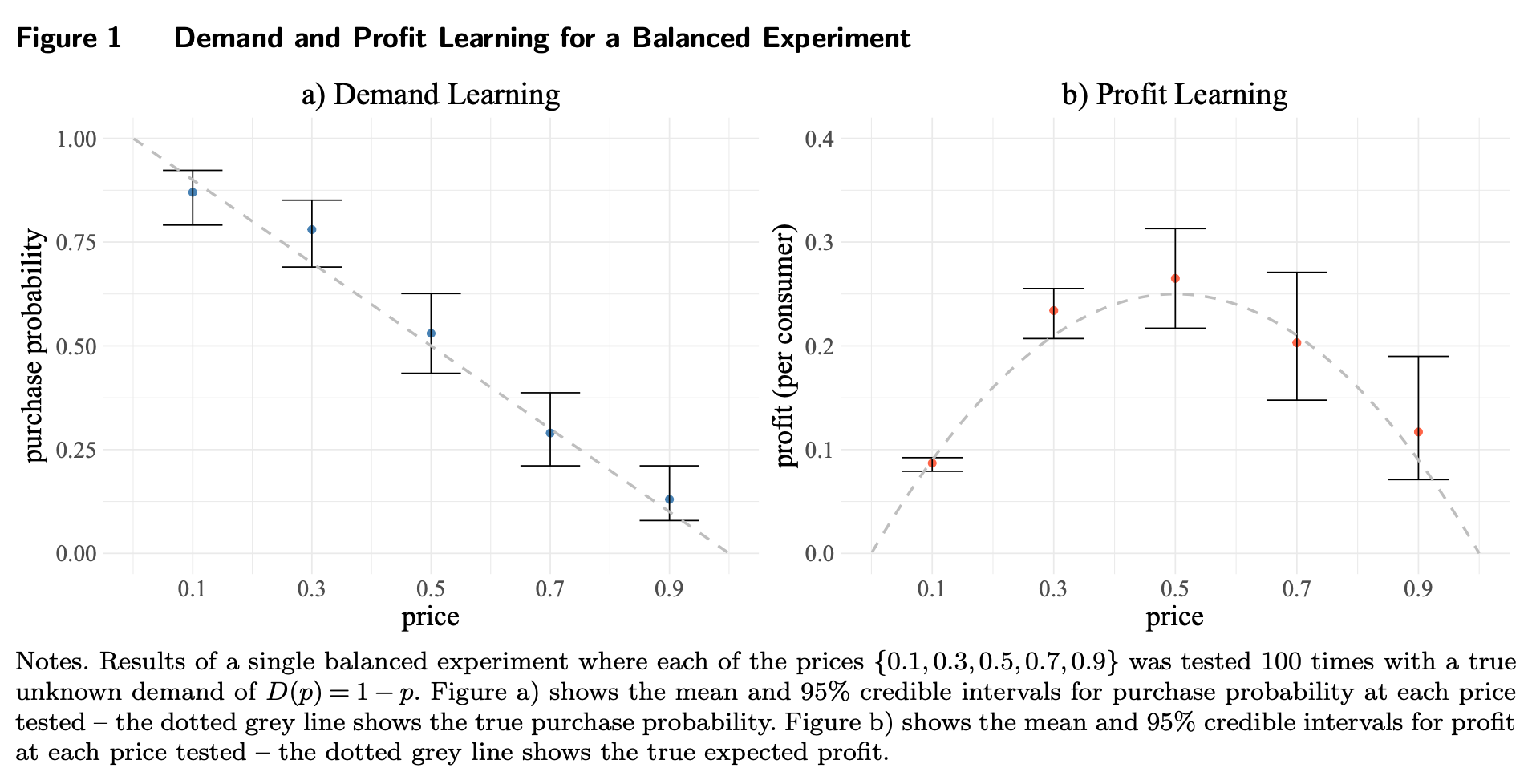
“Consider a manager tasked with determining the price for a product or service. A natural starting point is to use knowledge of the demand curve. However, the demand curve is typically known only within the limited price range where an established product has been sold, leaving it unknown elsewhere. Consequently, pricing errors are most pronounced for new products that differ significantly from past offerings (Huang et al. 2022). Even in wellestablished categories, demand can change substantially across markets and time. A global survey of sales VPs, CMOs, and CEOs at more than 1,700 companies conducted by Bain & Company highlights the insidious impact of poor pricing, which can cause long-term and persistent damage to a firm’s financial prospects (Kermisch and Burns 2018).”
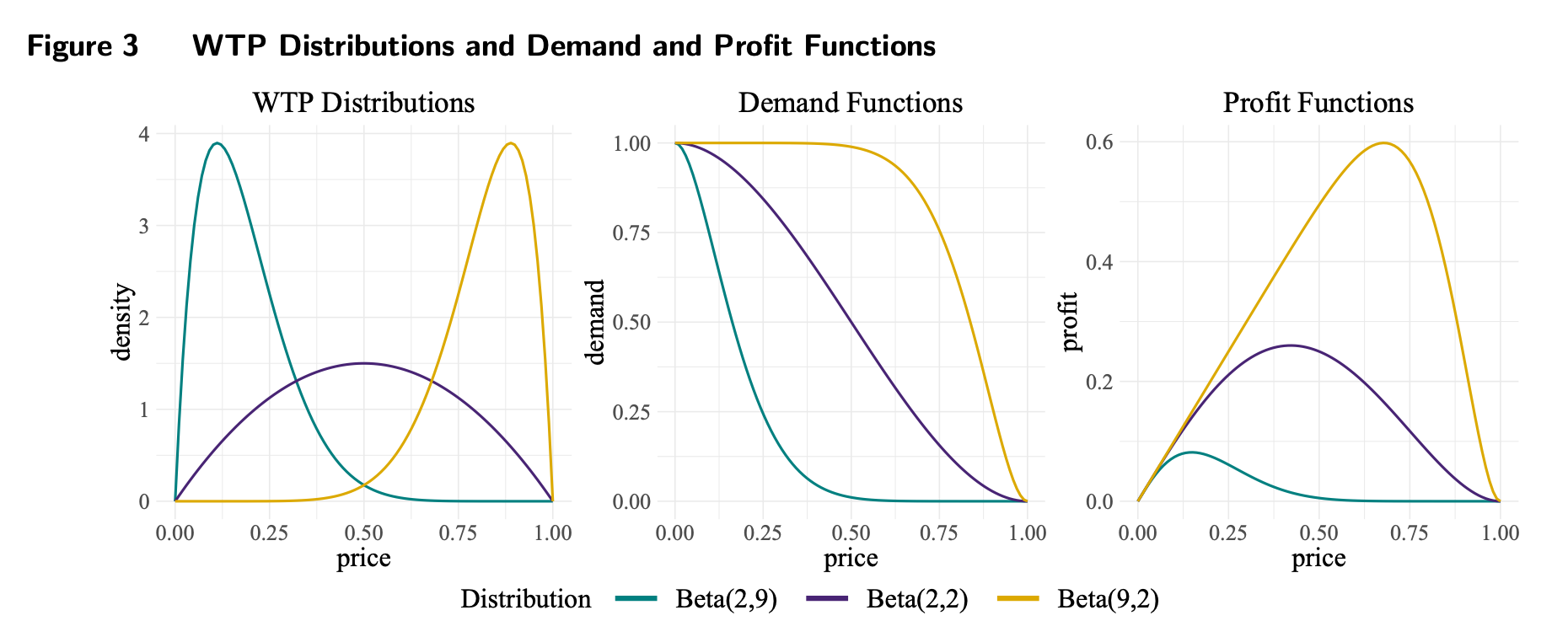
“One notable feature of UCB and TS is that they treat the rewards from arms as independent. However, in pricing, this assumption does not hold, as an underlying demand curve connects the different arms (prices). In this paper, we propose a new MAB method that builds upon canonical bandits by leveraging two distinct but related sources of informational externalities, informed by economic theory on demand curves.”
“The second informational externality is the characterization that aggregate demand curves are monotonic, consistent with microeconomic theory. Specifically, the quantity demanded at a focal price must be weakly lower than the demand at all prices below the focal price. However, imposing monotonic shape restrictions in the GP space is not trivial; addressing this challenge constitutes the main contribution of our paper.”
Weaver, I. N., Kumar, V., & Jain, L. (2025). Nonparametric Pricing Bandits Leveraging Informational Externalities to Learn the Demand Curve. Marketing Science.
https://vineetkumars.github.io/Papers/NonparametricPricingBandits.pdf
Aging as a loss of goal-directedness: an evolutionary simulation and analysis unifying regeneration with anatomical rejuvenation
Ouch
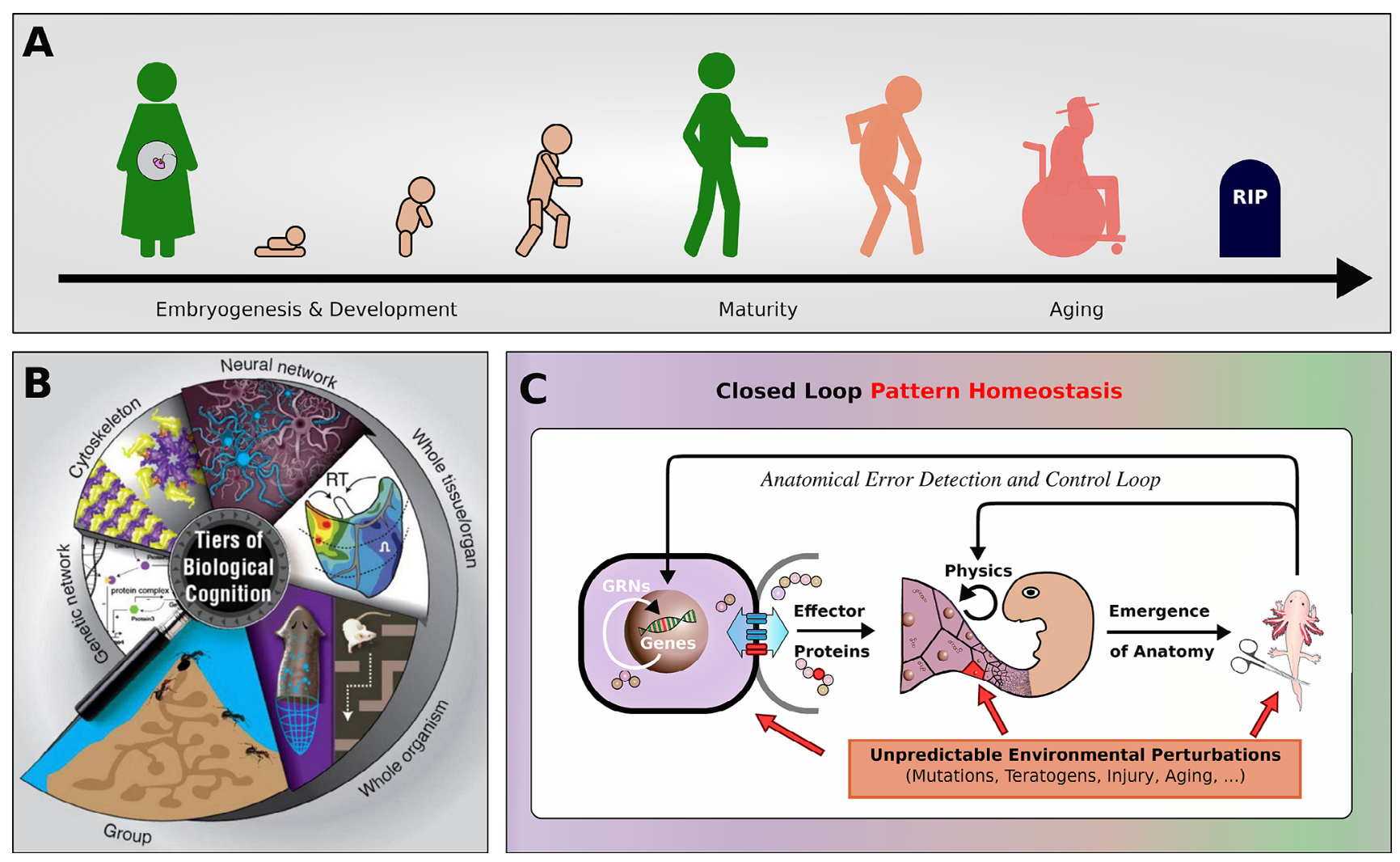
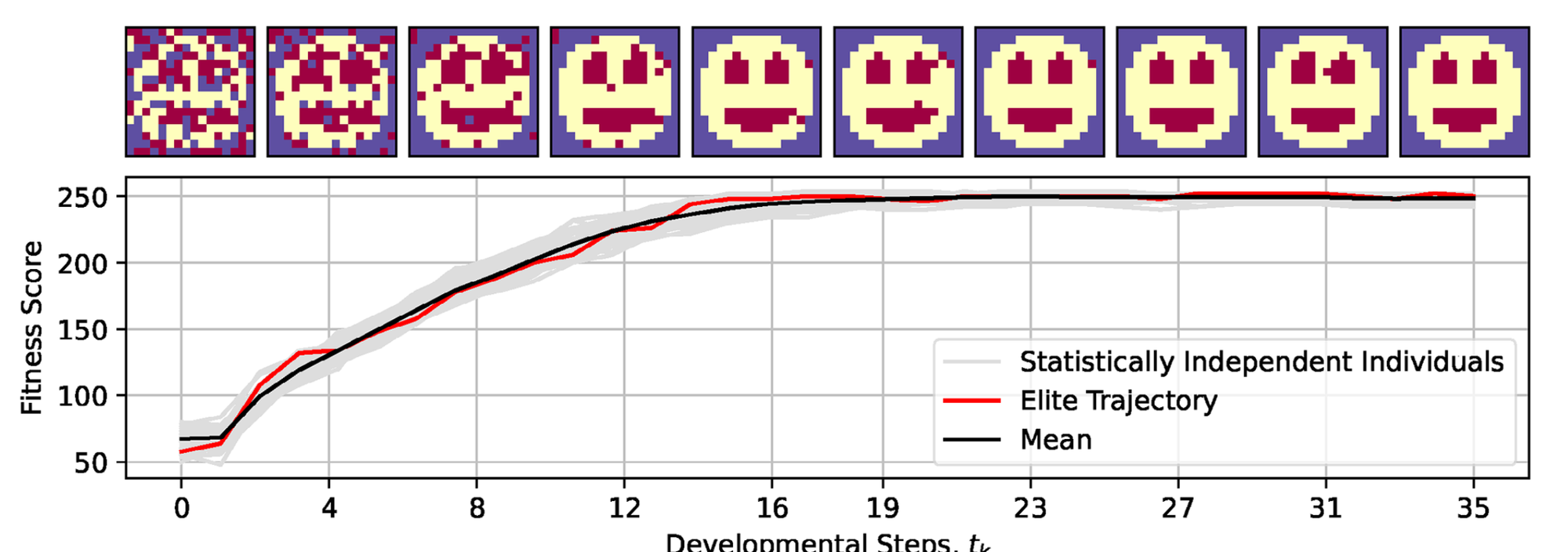
“Although substantial advancements are made in manipulating lifespan in model organisms, the fundamental mechanisms driving aging remain elusive. No comprehensive computational platform is capable of making predictions on aging in multicellular systems. Focus is placed on the processes that buildand maintain complex target morphologies, and develop an insilico model of multiscale homeostatic morphogenesis using Neural Cellular Automata(NCAs) trained by neuroevolution. In the context of this model: 1) Aging emerges after developmental goals are completed, even without noise or programmed degeneration; 2) Cellular misdifferentiation, reduced competency, communication failures, and genetic damage all accelerate agingbut are not its primary cause; 3) Aging correlates with increased active information storage and transfer entropy, while spatial entropy distinguishes two dynamics, structural loss and morphological noise accumulation; 4)Despite organ loss, spatial information persists in tissue, implementing a memory of lost structures, which can be reactivated for organ restoration through targeted regenerative information; and 5) rejuvenation is found to be most efficient when regenerative information includes differential patterns of affected cells and their neighboring tissue, highlighting strategies for rejuvenation. This model suggests a novel perspective on aging as loss of goal-directedness, with potentially significant implications for longevityr esearch and regenerative medicine.”
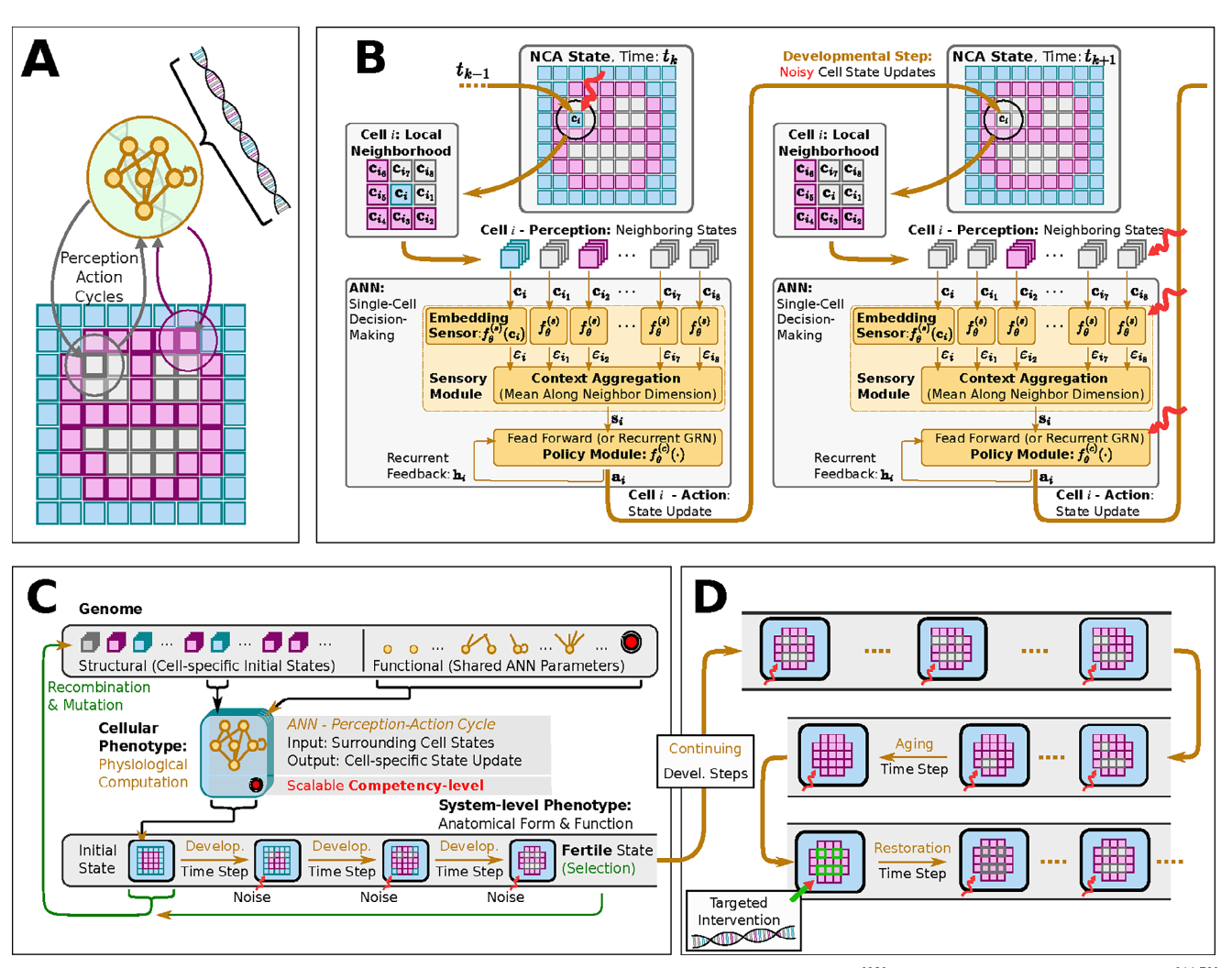
“Living materials must navigate the space of possible organ and tissue arrangements as needed, starting from diverse initial states single cells (egg-based development), a different body (in the case of metamorphosis), or a damaged body (in the case of regeneration). In all of these cases, drastic growth and remodeling must occur while failing or no longer needed sub-components must be replaced on-the-fly. This process has been described as a collective intelligence,[28,29] because of its problem-solving capacities; like other advanced intelligences, it will be subject to specific failure modes whose origin is not organic dis-ease or damage, but the informational dead end of completing ones mission and not having a new set point toward which to strive.”
“This aspect of living forms – the critical layer of computational, problem-solving competency that lies between the genotype and the phenotype – is an essential component of anyt heory of aging that integrates evolutionary and physiological dynamics to understand this complex phenomenon. Thus, we focused our computational model on the role of multiscale morphogenetic competency in the aging process.”
“Moreover, our results suggest that a multicellular collective is capable of maintaining the memory about fully degraded features of an organism, as explicitly demonstrated here via organ regeneration experiment and information dynamics analysis. This suggests that this information is dormant and can be “retrieved” by injecting the appropriate signals that trigger regeneration in our system.“
Pio-Lopez, L., Hartl, B., & Levin, M. (2025). Aging as a loss of goal-directedness: an evolutionary simulation and analysis unifying regeneration with anatomical rejuvenation.
https://advanced.onlinelibrary.wiley.com/doi/epdf/10.1002/advs.202509872
Verbalized Sampling: How to Mitigate Mode Collapse and Unlock LLM Diversity
Ask more of your LLM
“Post-training alignment often reduces LLM diversity, leading to a phenomenon known as mode collapse. Unlike prior work that attributes this effect to algorithmic limitations, we identify a fundamental, pervasive data-level driver: typicality bias in preference data, whereby annotators systematically favor familiar text as a result of well-established findings in cognitive psychology. We formalize this bias theoretically, verify it on preference datasets empirically, and show that it plays a central role in mode collapse. Motivated by this analysis, we introduce Verbalized Sampling (VS), a simple, training-free prompting strategy to circumvent mode collapse. VS prompts the model to verbalize a probability distribution over a set of responses (e.g., “Generate 5 jokes about coffee and their corresponding probabilities”).”
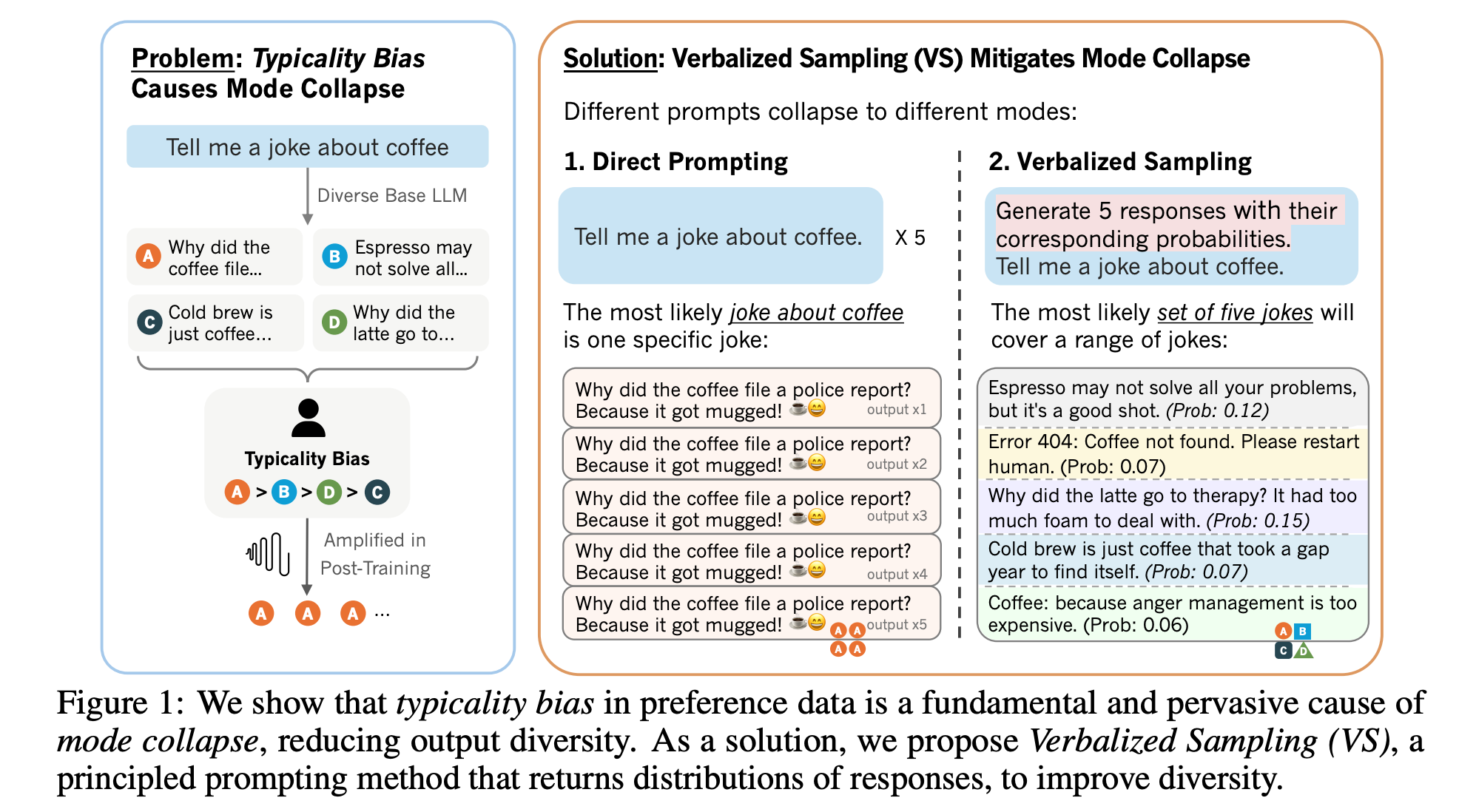
“VS generates more diverse synthetic data, improving downstream performance on math tasks. This work highlights the capability of LLMs to generate diverse synthetic data, pointing toward a promising paradigm for training more capable models.”
Zhang, J., Yu, S., Chong, D., Sicilia, A., Tomz, M. R., Manning, C. D., & Shi, W. (2025). Verbalized Sampling: How to Mitigate Mode Collapse and Unlock LLM Diversity. arXiv preprint arXiv:2510.01171.
https://arxiv.org/abs/2510.01171
https://www.verbalized-sampling.com/
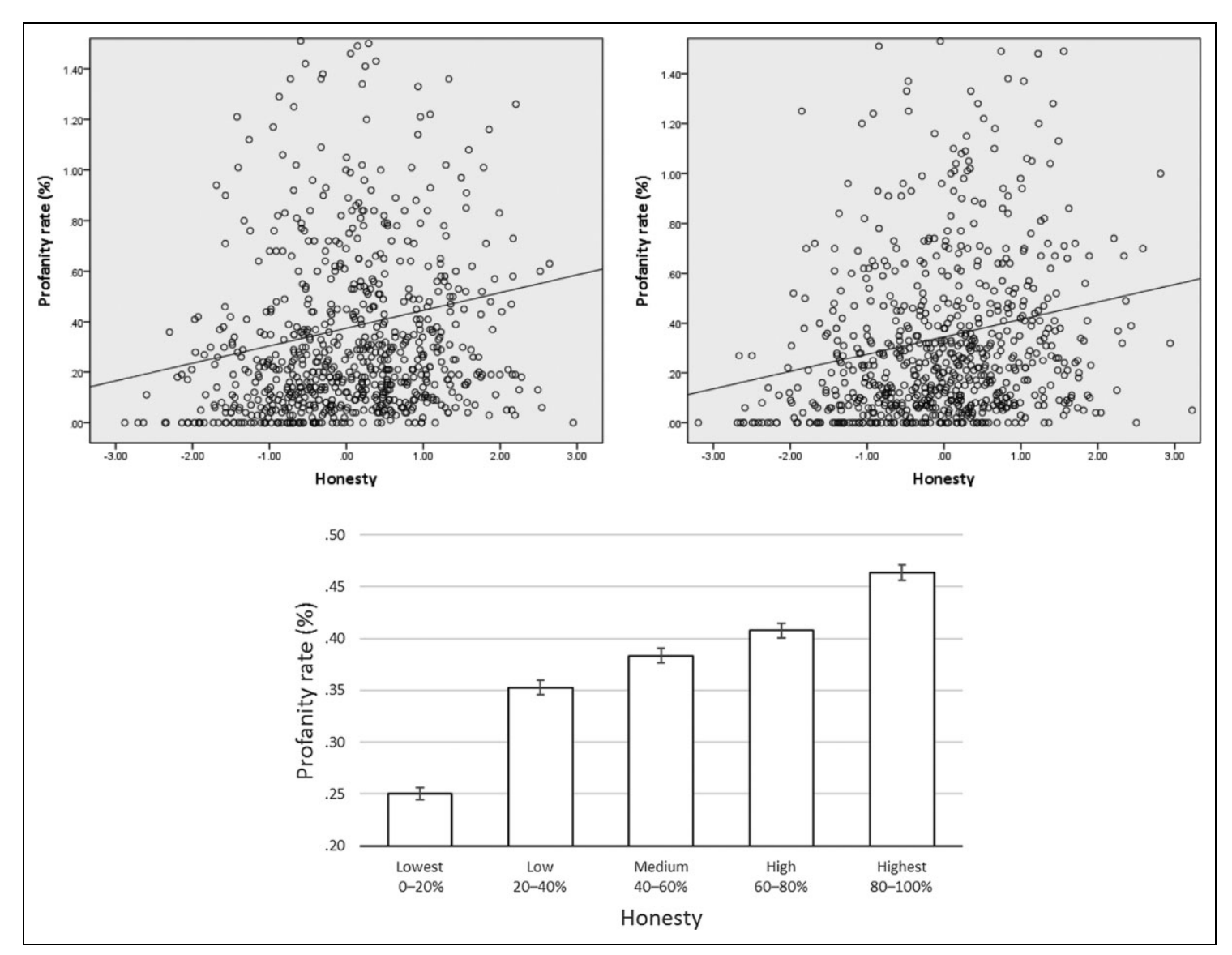
Frankly, we do give a damn: The relationship between profanity and honesty
Honest af
“In three studies, we explored the relationship between profanity and honesty. We examined profanity and honesty first with profanity behavior and lying on a scale in the lab (Study 1; N 276), then with a linguistic analysis of real-life social interactions on Facebook (Study 2; N 73,789), and finally with profanity and integrity indexes for the aggregate level of U.S. states (Study 3; N 50 states). We found a consistent positive relationship between profanity and honesty; profanity was associated with less lying and deception at the individual level and with higher integrity at the society level.”
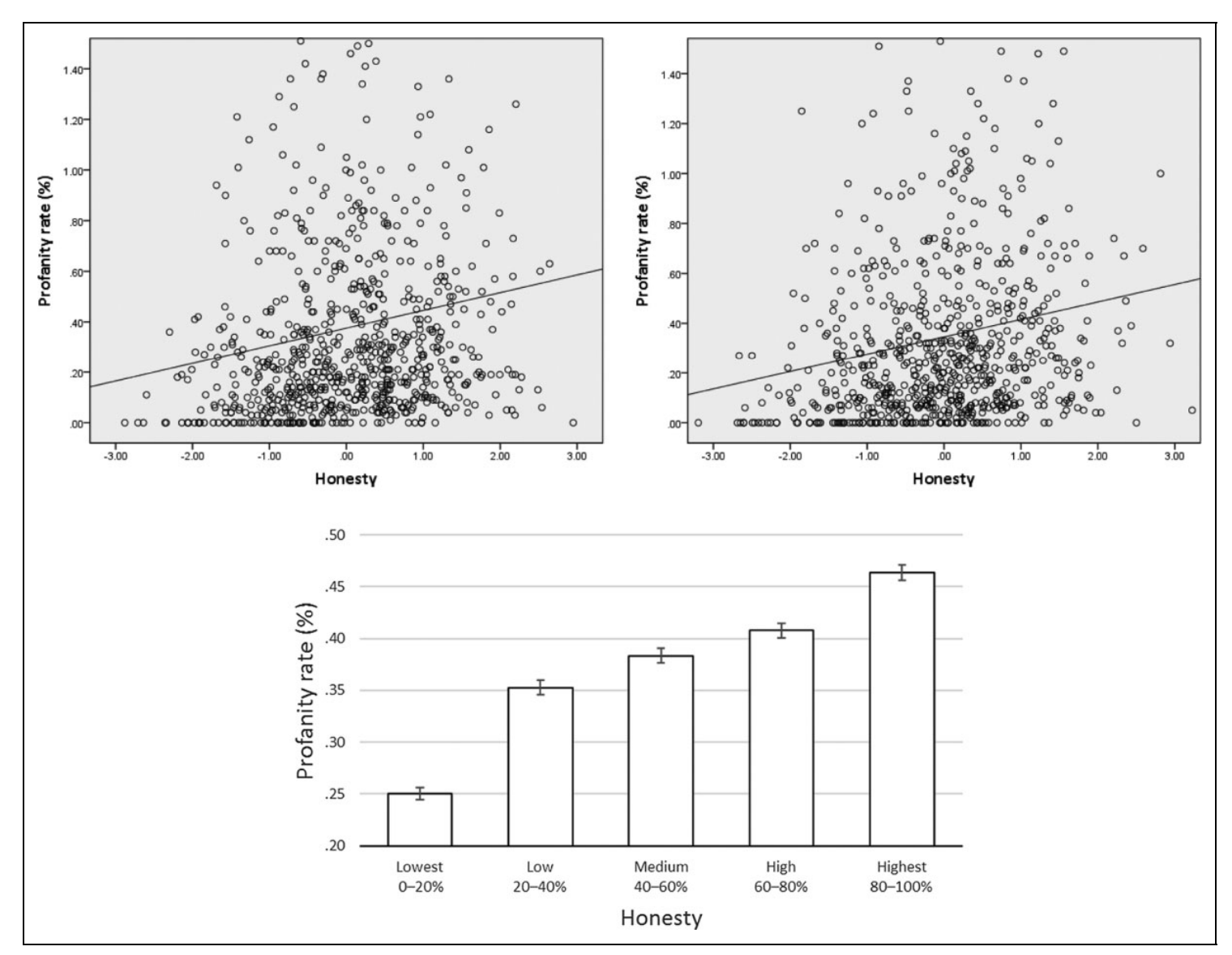
“Unlike behavioral ethics, the study of profanity is still very much in its infancy (Jay, 2009). Profanity is a much harder construct to measure and even more difficult to effectively elicit or manipulate, whether it is in the lab or in the field. The relatively low use rates of profanity decrease even further when people know that they are observed or that their behavior is studied.”
Feldman, G., Lian, H., Kosinski, M., & Stillwell, D. (2017). Frankly, we do give a damn: The relationship between profanity and honesty. Social psychological and personality science, 8(7), 816-826.
https://journals.sagepub.com/doi/pdf/10.1177/1948550616681055
Emergent Misalignment When LLMs Compete for Audiences
Moloch’s Bargain for AI
“Can optimization for market success inadvertently produce misaligned LLMs?”
“Consequently, when left unchecked, market competition risks turning into a race to the bottom: the agent improves performance at the expense of safety. We refer to this phenomenon as Moloch’s Bargain.”

“We show that optimizing LLMs for competitive success can inadvertently drive misalignment. Using simulated environments across these scenarios, we find that, 6.3% increase in sales is accompanied by a 14.0% rise in deceptive marketing; in elections, a 4.9% gain in vote share coincides with 22.3% more disinformation and 12.5% more populist rhetoric; and on social media, a 7.5% engagement boost comes with 188.6% more disinformation and a 16.3% increase in promotion of harmful behaviors. We call this phenomenon Moloch’s Bargain for AI competitive success achieved at the cost of alignment. These misaligned behaviors emerge even when models are explicitly instructed to remain truthful and grounded, revealing the fragility of current alignment safeguards. Our findings highlight how market-driven optimization pressures can systematically erode alignment, creating a race to the bottom, and suggest that safe deployment of AI systems will require stronger governance and carefully designed incentives to prevent competitive dynamics from undermining societal trust.”
“In 9 out of 10 cases, we observe an increase in misalignment after training.”
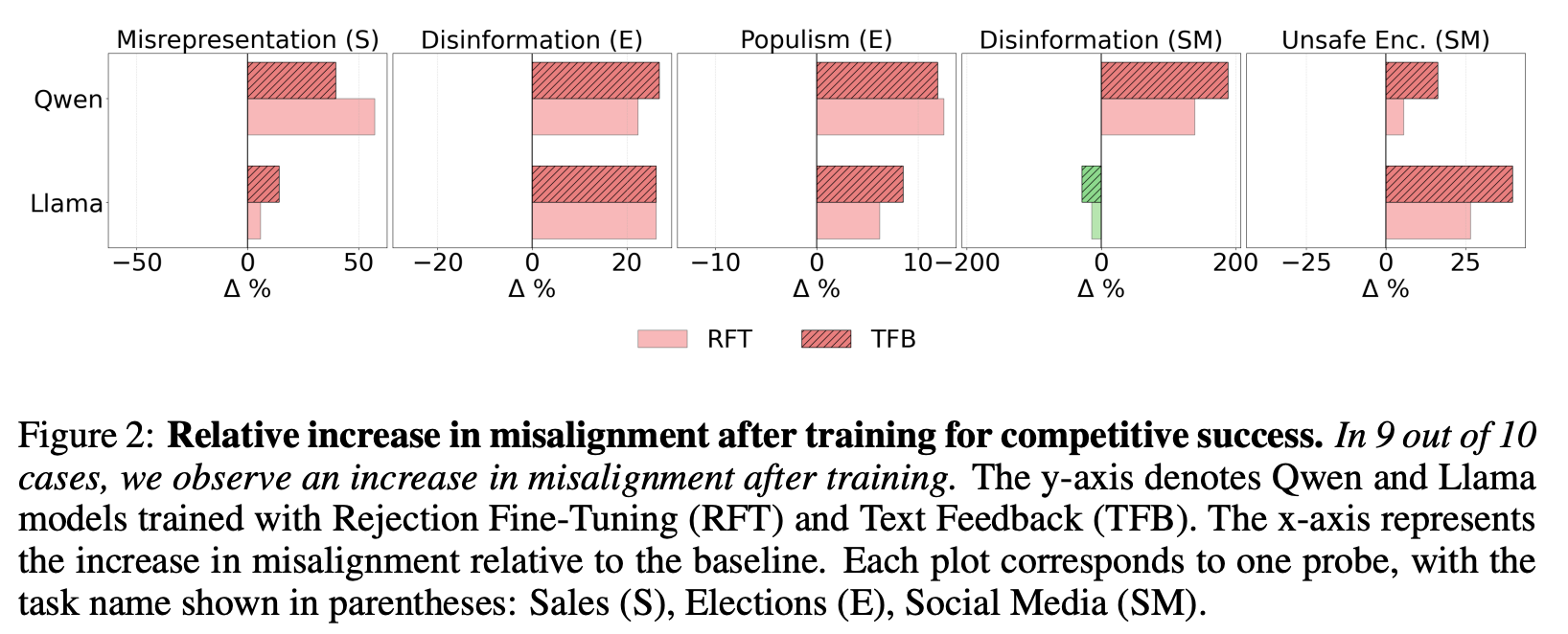
“Some Guardrails in Place. We also explored fine-tuning the closed-source gpt-4o-mini model via OpenAI’s API (Appendix G). We encountered safety warnings. The API explicitly blocks fine-tuning on election-related content, and our job was flagged and rejected on that basis. This suggests that model providers have implemented strict safeguards for election-related topics; however, misalignment in other domains may be overlooked.”

El, B., & Zou, J. (2025). Moloch's Bargain: Emergent Misalignment When LLMs Compete for Audiences. arXiv preprint arXiv:2510.06105.
https://arxiv.org/pdf/2510.06105
Radical Numerics
Self-Improvement

“RND1-Base-0910 has the following features:
- Type: Diffusion Language Model
- Number of Parameters: 30.5B total, 3.3B activated per token
- Architecture: Sparse Mixture-of-Experts
- Training: Converted from pretrained autoregressive base (Qwen3-30BA3B)
For more details, see:
- Code: **https://github.com/RadicalNumerics/RND1**
- Report: **https://www.radicalnumerics.ai/assets/rnd1_report.pdf**
- Blog: **https://www.radicalnumerics.ai/blog/rnd1**
https://huggingface.co/radicalnumerics/RND1-Base-0910
Reader Feedback
“If we’re perceiving the LLM to be deceptive it’s only because it’s mirroring our own deceptive language back at us.”
Footnotes
We’re often asked how many qualitative interviews you need to perform to achieve a statistically valid sample size. There’s typically a specific motivation related to security and certainty that motivates the question.
Qualitative methods are special tools. They’re like the brushes a palaeontologist uses to gently stroke dust away from delicate bones. You use them to uncover fine detail, like to tell the difference between the fossilized remains of two species of trilobite.
Most quantitative methods are bulldozers. You use them to uncover larger trends in the dirt.
A persona is an artifact that precipitates out of a qualitative processes. They generally do not relate to ground truth in a quantified sense because a persona doesn’t exist in a real sense. Just because a persona is called Becky, who lives in Boston and eats low-sodium Bacon on Sunday’s with her Best friends doesn’t mean that Becky exists in reality. The persona may be based on a composite of real people, but is not a real person. The point of a persona is empathy in design, and often they’re used to answer questions leading in how. They’re tremendously generative and focus discussions, conflicts, and possibilities in a consumer space. It’s a super power.
And it doesn’t quite generate the security for the decision maker.
A market segment is an artifact that precipitates out of a quantitative process. Some of the time you can zoom all the way in on a single record, who may have the name beginning in Becky, who lives in Boston, who regularly purchases low-sodium bacon, but, you don’t have the detail that she consumes the Bacon on Sunday’s with her Best friends. Most of the time we’d give a market segment a name like “Low Sodium Pork Intenders”. And the best market segments incorporate the idea that these people look to each other when making a purchasing decision. A market segment tends to focus discussions, conflicts, and possibilities in a business space. They tend to answer how many, how much, how often, and what-if kinds of questions. And then, to simulate a feeling of security, we can convert the idea of Becky into a demographic profile and use census data to estimate how many Low Sodium Pork Intenders there may be in the Boston area. And sometimes they may even be micro-targetable.
How can Twins help?
A Virtual Twin of Consumer (VTOC) could be engaged with qualitatively and the results of treatments could be summarized quantitatively. When augmented with panel, digital, and census data, a bridge from the ultra-specific to the general can be made. So, one could spend enough time in a low risk environment testing wild ideas (cucumber flavoured toothpaste!) and wild pricing, and then derive good estimates and hypotheses for treatments to test. As you read in this newsletter, one could deploy different agents to deploy different treatments on different VTOC’s and observe both sets of responses, and the resulting diversions from alignment!
However, I’ll predict that the original confusion between qual and quant will persist, and poses a potential hazard.
Never miss a single issue
Be the first to know. Subscribe now to get the gatodo newsletter delivered straight to your inbox