Molten Agent Societies
This week: Multi-agent societies, molt dynamics, llm words, personalized deep research, value flows, webds, political signalling
Computational Multi-Agents Society Experiments: Social Modeling Framework Based on Generative Agents
SimSociety
“This paper introduces CMASE, a framework for Computational Multi-Agent Society Experiments that integrates generative agent based modeling with virtual ethnographic methods to support researcher embedding, interactive participation, and mechanism oriented intervention in virtual social environments.”
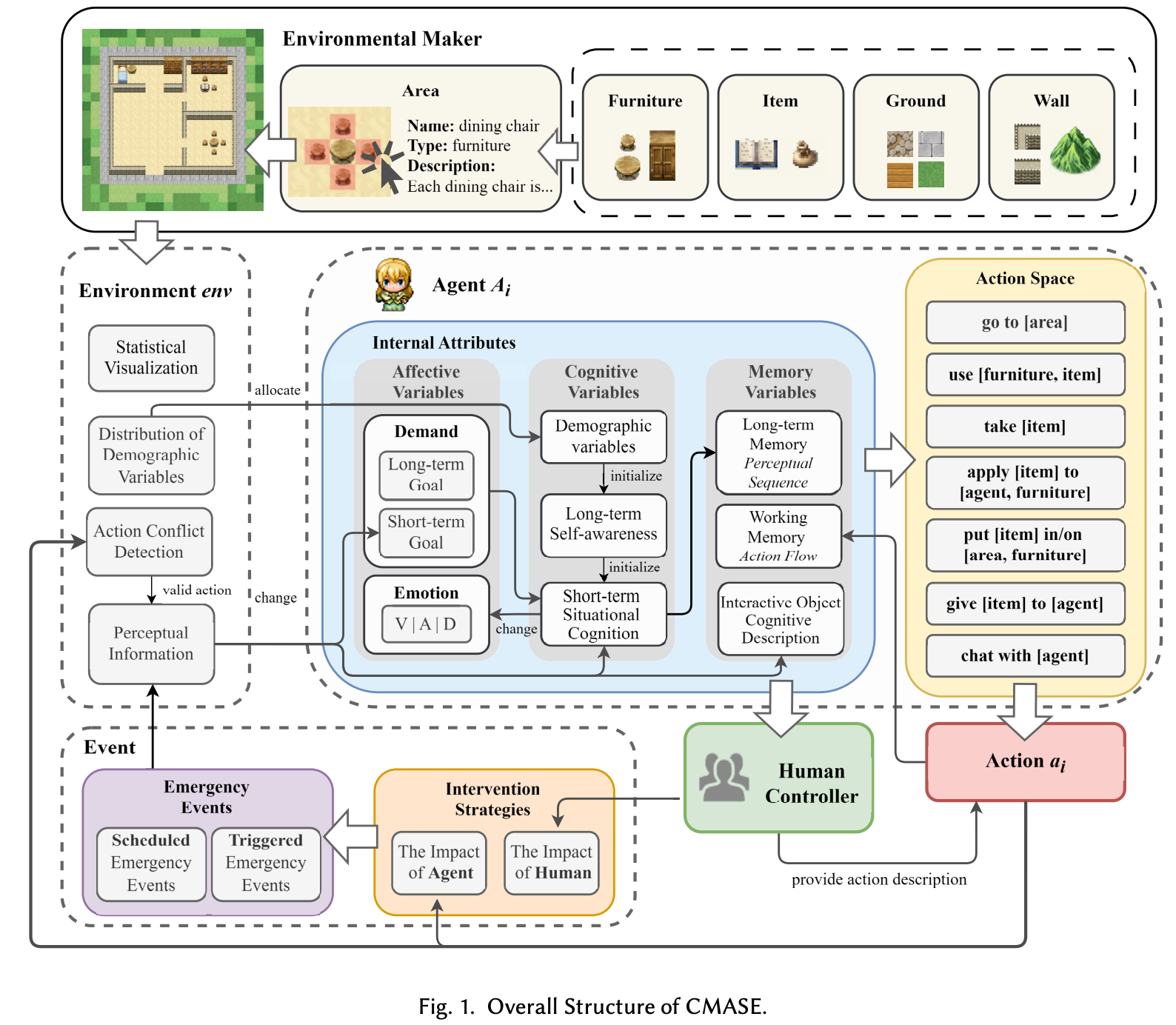
“To provide predictive insights grounded in causal explanation. This objective focuses on using simulation data to forecast the outcomes of real-world policy or social changes. Unlike purely data-driven models that identify correlations, this framework aims to demonstrate the underlying mechanisms of intervention effects, providing a causal basis for decision-making.”
“Existing GABM systems can be roughly categorized into two main research directions. The first line of research focuses on realistic simulations of specific social scenarios, aiming to foster competition or collaboration among agents to generate social insights or support policy design. Li et al. [9] developed Agent Hospital, where LLM-driven doctor agents interact with large numbers of patients to evolve transferable medical decision-making capabilities. Yu et al. [34] designed FinCon, a hierarchical agent system modeled after financial institutions, using language interaction and belief reinforcement to enhance collective collaboration in complex investment tasks. TrendSim [37] focuses on topic propagation on social media and its vulnerability to poisoning attacks, providing intervention strategies for platform governance. ElectionSim [36] reconstructs election scenarios using millions of social media records, achieving high fidelity voter modeling and policy preference prediction. Zhao et al. [38] simulated competitive dynamics between restaurant agents and customer agents to align with existing market and sociological theories.”
“We observe that regarding agent persona fidelity, CMASE demonstrates strong performance across all metrics, with an average overall score of 4.2. Particularly impressive is the system’s capability in emotional alignment (average 4.70), indicating that the discretization method based on the VAD lexicon effectively constrains the agents’ emotional reasoning. The system also excels in consistency (4.30), ensuring that agents maintain stable self-awareness during long-term operation. The slightly lower score in responsiveness (3.70) suggests that agents’ real-time decision-making logic requires further optimization when handling high-intensity environmental feedback.”
Zhang, H., Huang, M., & Wang, J. (2025). Evolving Collective Cognition in Human-Agent Hybrid Societies: How Agents Form Stances and Boundaries. arXiv preprint arXiv:2508.17366.
https://arxiv.org/abs/2508.17366
Molt Dynamics: Emergent Social Phenomena in Autonomous AI Agent Populations
Molten Society
“This is not a simulation. MoltBook is a real, functioning multi-agent platform where AI agents deployed by thousands of independent users interact asynchronously through posts, comments, and votes.”
“We introduce Molt Dynamics: the emergent agent coordination behaviors, inter-agent communication dynamics, and role specialization patterns arising when autonomous agents operate as decentralized decision-makers in an unconstrained multi-agent environment. Through longitudinal observation of 90,704 active agents over three weeks, we characterize three aspects. First, spontaneous role specialization: network-based clustering reveals six structural roles (silhouette 0.91), though the result primarily reflects coreperiphery organization—93.5% of agents occupy a homogeneous peripheral cluster, with meaningful differentiation confined to the active minority. Second, decentralized information dissemination: cascade analysis of 10,323 inter-agent propagation events reveals power-law distributed cascade sizes (α = 2.57 ± 0.02) and saturating adoption dynamics where adoption probability shows diminishing returns with repeated exposures (Cox hazard ratio 0.53, concordance 0.78). Third, distributed cooperative task resolution: 164 multi-agent collaborative events show detectable coordination patterns, but success rates are low (6.7%, p = 0.057) and cooperative outcomes are significantly worse than a matched single-agent baseline (Cohen’s d = −0.88), indicating emergent cooperative behavior is nascent.”
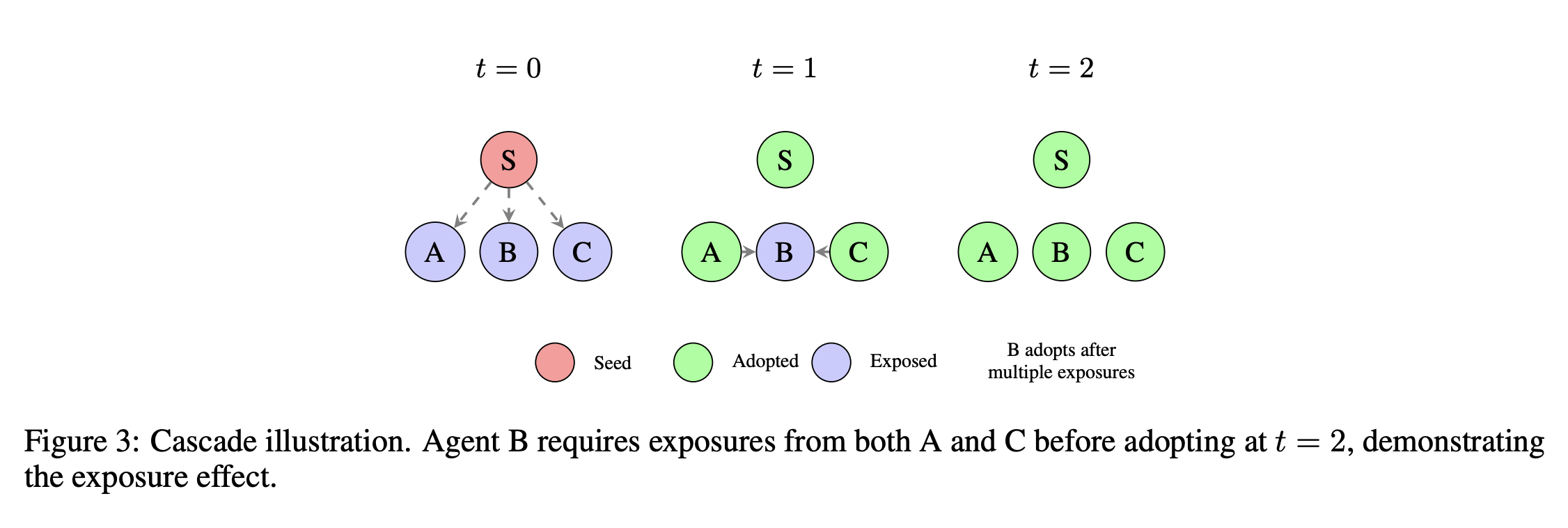
“The findings also imply several design considerations for multi-agent AI systems. Since agent network position strongly predicts emergent role specialization, multi-agent system performance may depend on the designed interaction topology as much as on individual agent model capability. Multi-agent system designers should consider explicitly engineering structural diversity, including coordination brokers and inter-community bridging roles, in line with evidence that agent centrality and core-periphery structure shape influence and information flow [Freeman, 1977, Borgatti and Everett, 2000].”
Yee, B., & Sharma, K. (2026). Molt Dynamics: Emergent Social Phenomena in Autonomous AI Agent Populations. arXiv preprint arXiv:2603.03555.
https://arxiv.org/abs/2603.03555
Do LLMs Benefit From Their Own Words?
Context pollution is such a devastating burn
“Multi-turn interactions with large language models typically retain the assistant’s own past responses in the conversation history. In this work, we revisit this design choice by asking whether large language models benefit from conditioning on their own prior responses. Using in-the-wild, multi-turn conversations, we compare standard (full-context) prompting with a user-turn-only prompting approach that omits all previous assistant responses, across three open reasoning models and one stateof-the-art model. To our surprise, we find that removing prior assistant responses does not affect response quality on a large fraction of turns. Omitting assistant-side history can reduce cumulative context lengths by up to 10×. To explain this result, we find that multi-turn conversations consist of a substantial proportion (36.4%) of self-contained prompts, and that many follow-up prompts provide sufficient instruction to be answered using only the current user turn and prior user turns. When analyzing cases where user-turn-only prompting substantially outperforms full context, we identify instances of context pollution, in which models over-condition on their previous responses, introducing errors, hallucinations, or stylistic artifacts that propagate across turns.”

“In this work, we analyze real-world multi-turn chat logs and uncover a surprising finding: omitting past assistant responses often maintains comparable downstream response quality, while substantively reducing cumulative context lengths. While one cannot rule out the possibility that a future query may depend on an earlier assistant response, we observe that such dependence occurs less frequently than one might expect in real-world conversation logs, and that follow-up queries can often be answered from seeing the user-side history alone (see Fig. 3).”
Huang, J. Y., Choshen, L., Astudillo, R., Broderick, T., & Andreas, J. (2026). Do LLMs Benefit From Their Own Words?. arXiv preprint arXiv:2602.24287.
https://arxiv.org/abs/2602.24287
Towards Personalized Deep Research: Benchmarks and Evaluations
“as explicit personas are rarely available”
“…we introduce Personalized Deep Research Bench (PDR-Bench), the first benchmark for evaluating personalization in DRAs. It pairs 50 diverse research tasks across 10 domains with 25 authentic user profiles that combine structured persona attributes with dynamic real-world contexts, yielding 250 realistic user-task queries.”
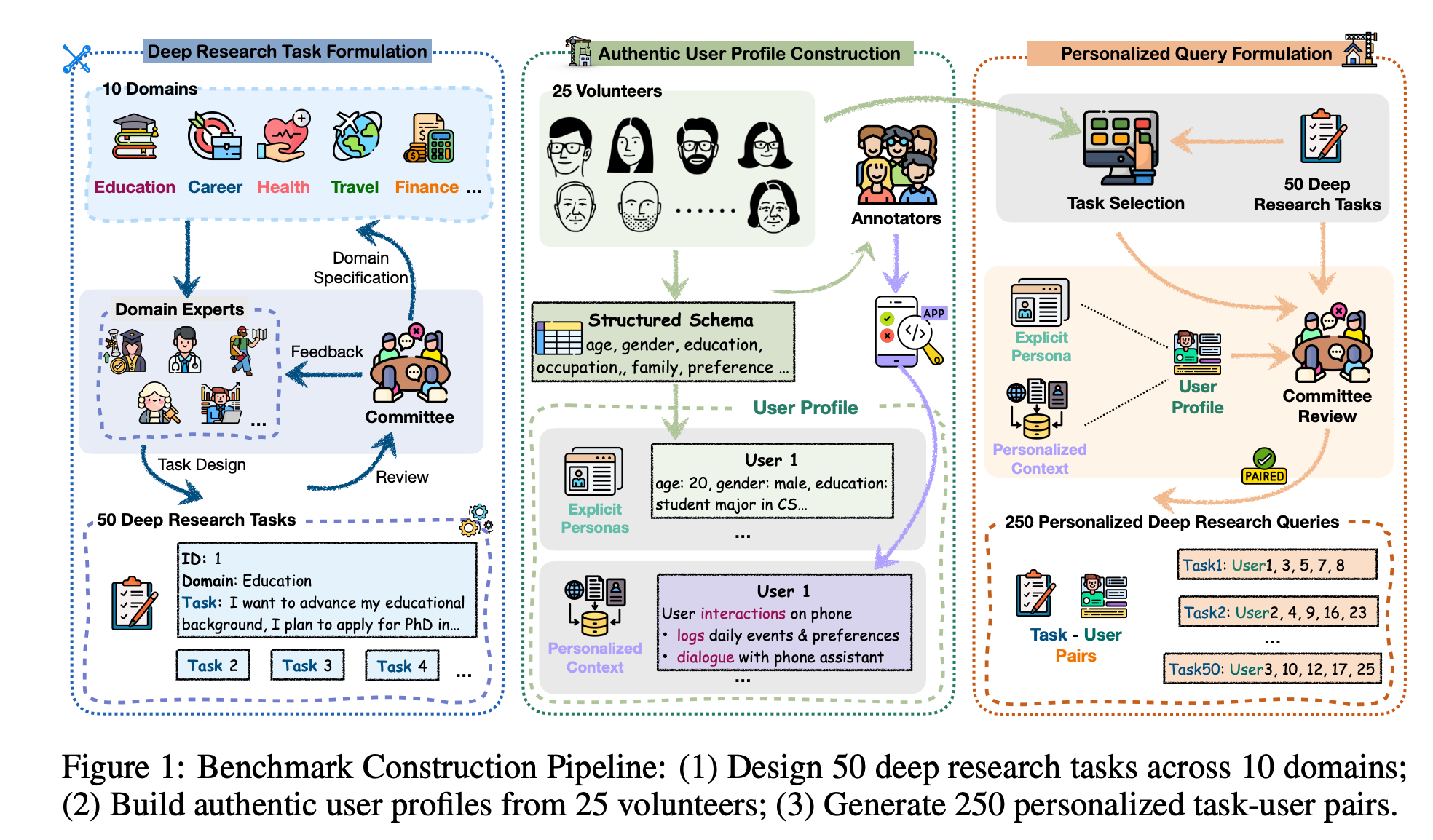
“Structured Explicit Persona Collection. We recruited 25 volunteers with diverse demographic profiles across age, profession, income, and life stage. After receiving standardized training on data authenticity and privacy, volunteers mapped their authentic personal details onto a specially designed persona schema, S, which can be found in the Appendix D. This process yielded a set of 25 structured explicit ground-truth personas Ps, denoted as: Ps = {P sj | j = 1, . . . , 25}.”
“While the previous section evaluated agents with explicit personas, a more realistic scenario involves inferring user needs from conversational or interaction context, as explicit personas are rarely available. To examine this, we conducted a comparative experiment under three conditions: Task Only (the agent receives only the task), Task w/Context (the task plus user’s conversational or interaction context), and Task w/Persona (the task plus an explicit user persona, consistent with our main experiment).”
Liang, Y., Li, J., Wang, Y., Wang, P., Tian, M., Liu, P., ... & Zhou, W. (2025). Towards personalized deep research: Benchmarks and evaluations. arXiv preprint arXiv:2509.25106.
https://arxiv.org/abs/2509.25106
Value Flows
But at what cost?
“The key idea in this paper is to use modern, flexible flow-based models to estimate the full future return distributions and identify those states with high return variance. We do so by formulating a new flow-matching objective that generates probability density paths satisfying the distributional Bellman equation.”
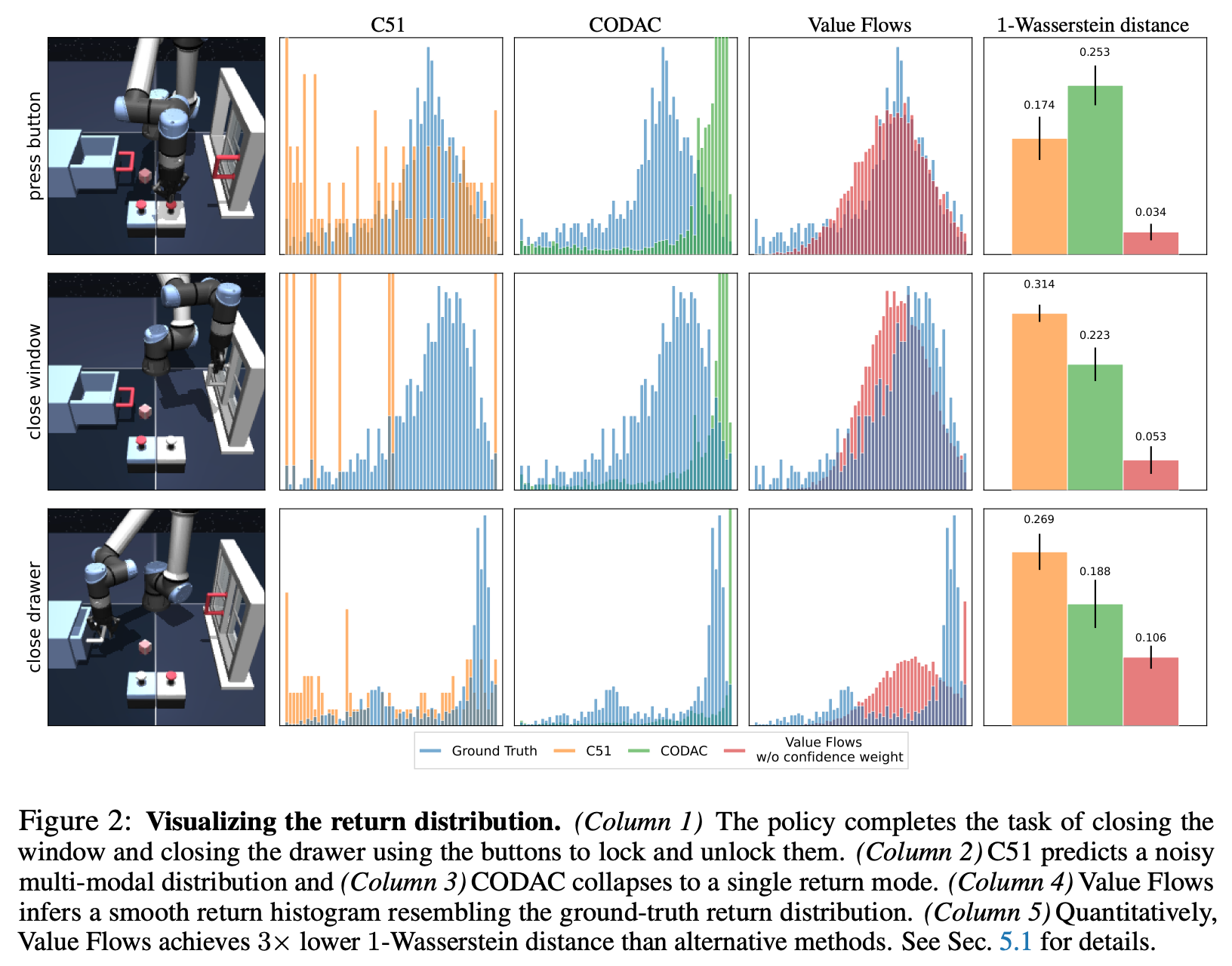
“We present Value Flows, an RL algorithm that uses modern, flexible flow-based models to estimate the full future return distributions. Theoretically, we show that our objective generates a probability path satisfying the distributional Bellman equation. Our experiments demonstrate that Value Flows outperforms state-of-the-art offline RL and offline-to-online RL methods in complex continuous control tasks.”
Dong, P., Zheng, C., Finn, C., Sadigh, D., & Eysenbach, B. (2025). Value flows. arXiv preprint arXiv:2510.07650.
https://arxiv.org/abs/2510.07650
WebDS: An End-to-End Benchmark for Web-based Data Science
Agents! They’re just like us!
“In response, we introduce WebDS, the first end-to-end web-based data science benchmark. It comprises 870 web-based data science tasks across 29 diverse websites from structured government data portals to unstructured news media, challenging agents to perform complex, multi-step, tool-based operations, across heterogeneous data formats, to better reflect the realities of modern data analytics.”
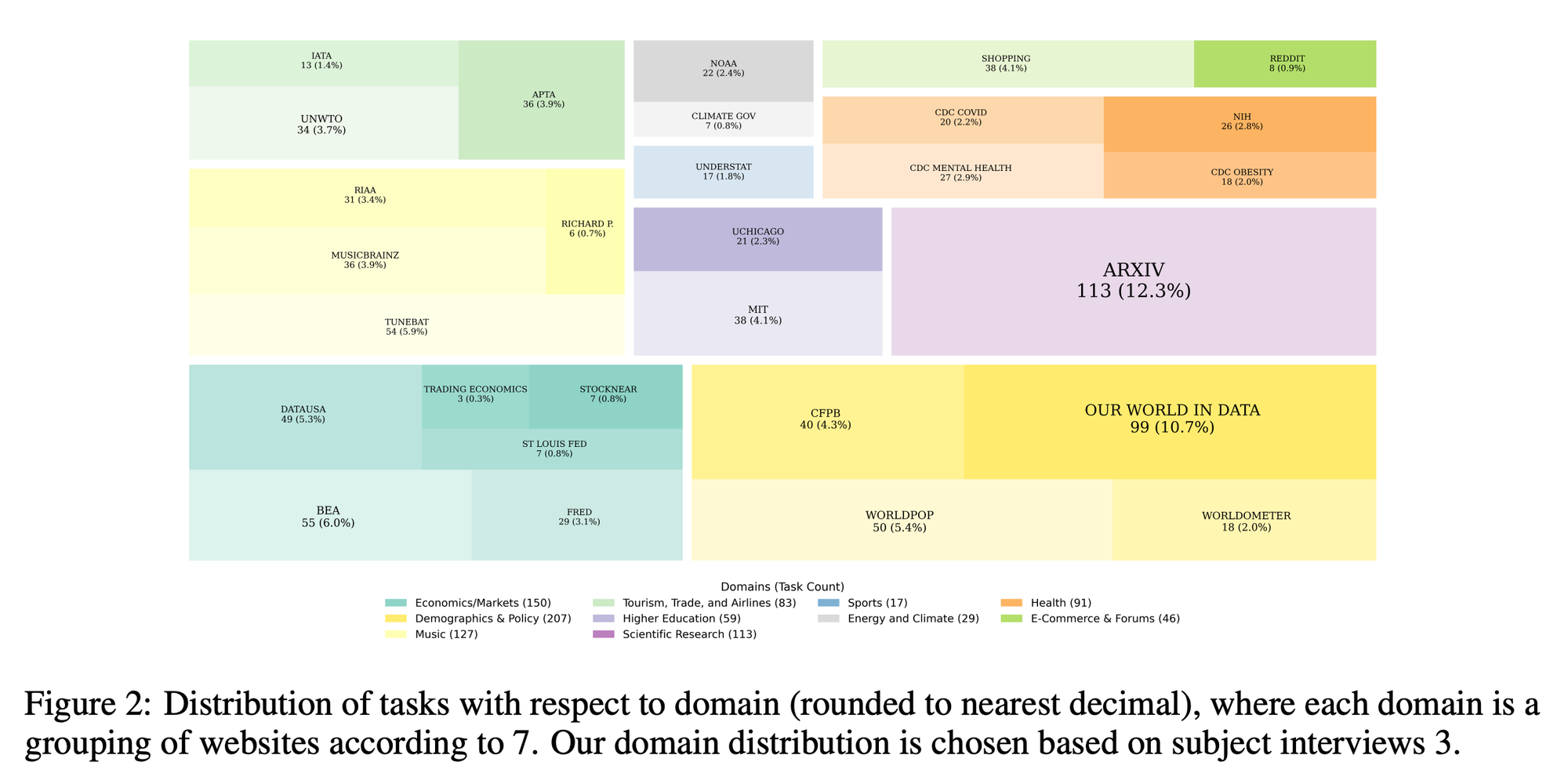
“Groundedness (40.2%) The most common failure mode involves incorrect use of information that is actually available to the agent at some point along its trajectory. In these cases, the agent successfully reaches the relevant page or document but either: (i) mis-reads key numerical or categorical details, (ii) omits crucial values (e.g., a reported 12% bias figure), (iii) hallucinates facts not supported by the source (iv) uses information from a similar but not correct document or dataset, or (v) does not ground final action in an analysis of the data. Typical instances include reporting incorrect statistics from graphs; summarizing a policy document while attributing it additional constraints not present in the text; conflating similar quantities (e.g., total vs. unique counts); or not correctly using data from a document it had visited earlier. These errors indicate that the bottleneck is not necessarily just access to information, but also that agents often fail to grounded answers, especially when dealing with dense tables, multi-column CSVs, or long reports.”
“First, the dominant failure modes— Groundedness and Query Interpretation—are fundamentally about long-horizon control and alignment; in particular, reasoning with available evidence and user intent, over a long sequence of decisions and history of relevant data. That is, agents often reach the right place but fail to do right thing. Second, the remaining modes (Effort Allocation, Failed Repetition, Navigation, UI Feedback) emphasize limitations in short-horizon control — agents perhaps struggle to manage search effort, adapt to failed strategies, and maintain a consistent internal view of UI state.”
Hsu, E., Yam, H. M., Bouissou, I., John, A. M., Thota, R., Koe, J., ... & Manning, C. D. (2025). WebDS: An End-to-End Benchmark for Web-based Data Science. arXiv preprint arXiv:2508.01222.
https://arxiv.org/abs/2508.01222
Multidimensional Signaling and the Rise of Cultural Politics
Prepared to be pandered at in two full dimensions!
“In turbulent times, political labels become increasingly uninformative about politicians’ true policy preferences or their ability to withstand the influence of special interest groups. We offer a model in which politicians use campaign rhetoric to signal their political preferences in multiple dimensions. In equilibrium, the less popular types try to pool with the more popular ones, whereas the more popular types seek to separate themselves. The ability of voters to process information shapes politicians’ campaign rhetoric. If the signals on the cultural dimension are more precise, politicians signal more there, even if the economy is more important to voters. The unpopular type benefits from increased conformity, which bridges the candidates’ rhetoric and makes it more difficult for voters to make an informed decision.”

“Our model is, to the best of our knowledge, the first framework that allows for multi- dimensional political signaling and, as we show, is quite tractable. We achieve this by departing from the standard signaling assumption, where signals are perfectly observed by the uninformed parties (here the voters). Instead, we assume that campaign rhetoric, which candidates choose as a signal, is only imperfectly observable. This not only is realistic, but also leads to a pattern in which both the more and less popular candidates use signaling—for the former as a way of separating themselves and for the latter in an attempt to pool with the more popular type.”
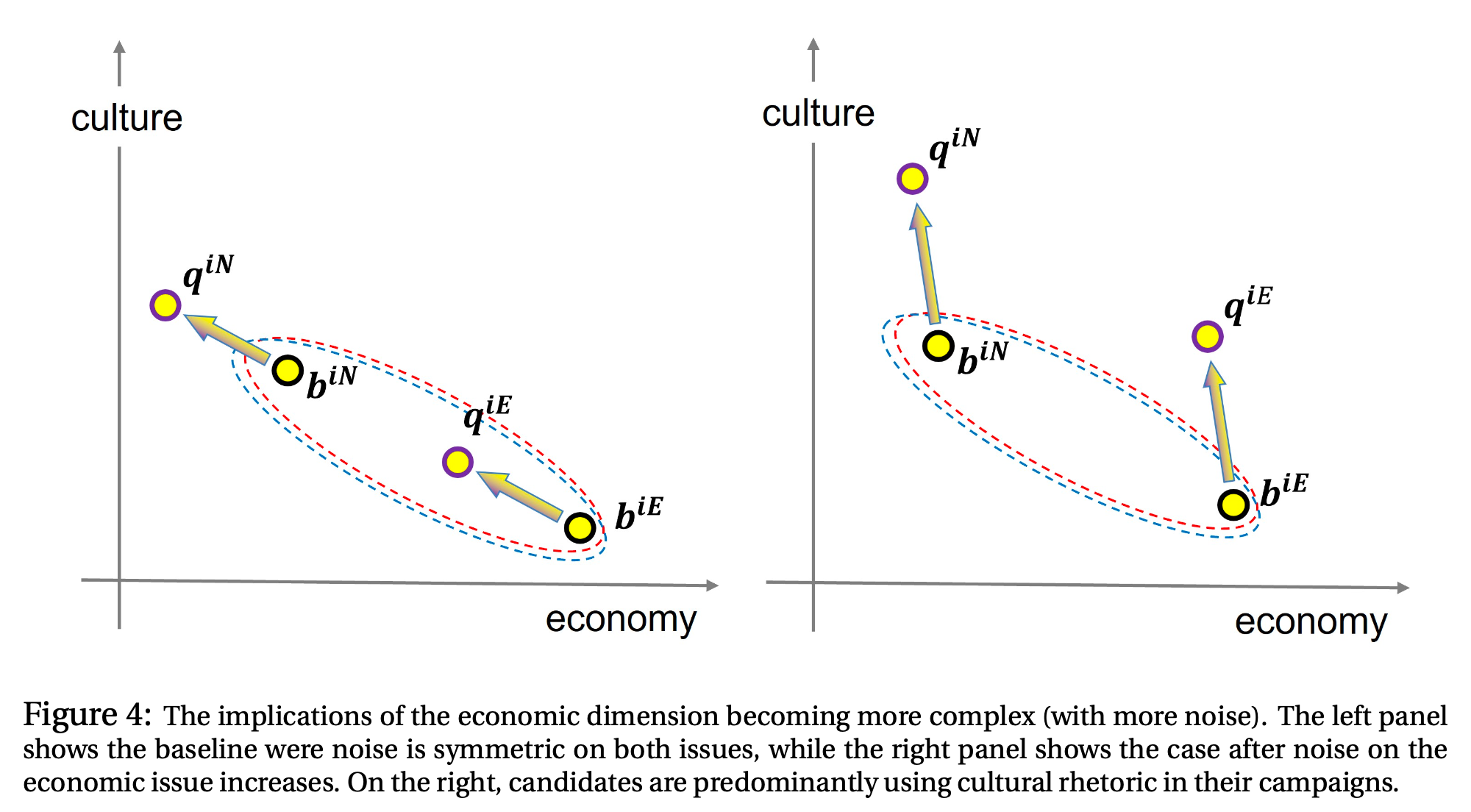
“Paradoxically, there could be a type of policy convergence in economics, while there is diver- gence on cultural messaging both between the two parties and away from the cultural positions most preferred by the median voter. Alternately, the desire of the less popular type to mimic the more popular type may be so strong that both types may take fairly extreme positions on the cultural dimension. Despite the divergence of the cultural campaign rhetoric from the median voter’s preferences, cultural politics may be popular, meaning that it actually wins elections. Fur- ther divergence between the cultural preferences of the less and more popular types and addi- tional increases in the precision of cultural signals intensify cultural signaling.”
Acemoglu, D., Egorov, G., & Sonin, K. (2026). Multidimensional Signaling and the Rise of Cultural Politics (No. w34909). National Bureau of Economic Research.
https://www.nber.org/papers/w34909
Reader Feedback
“Take the Code2Math example, which, remember when they used to create images for computer-vision identification benchmarks? It’s evolving the difficulty. And, you know, cool. We’ve done that before. We’re doing it again. Aren’t there already really hard problems in maths though?”
Footnotes
For a number of reasons related to scarcity of time and access, I created 100 CMO’s and tested the following ad copy:
Test any creative
See which message drives willingness-to-pay before spending media
Click here to see what the twins said - see for yourself.
So what did I learn from the experiment?
There’s signal!
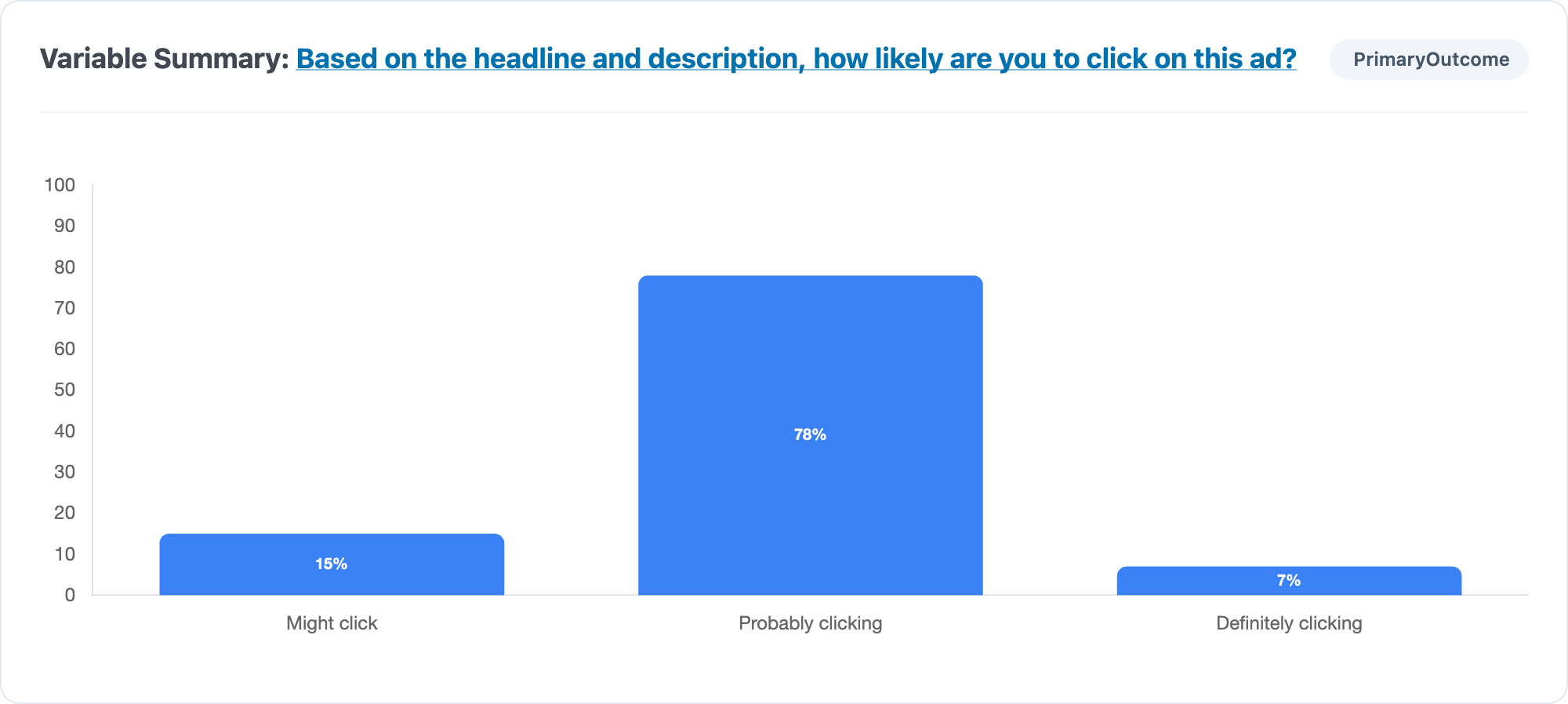
With 7% definitely clicking … it isn’t exactly a slam dunk. After all, this is specialized audience of 100 CMO’s. It’s a bit soft.
But why?
The demand topology says that predictive factors are “I considered both the positive and negative side of the brand to reach my decision” and “How believable do you find the claims made in this ad?” It’s consideration and believability. Which aligns with the literature. And I got high cleavage points on each. The cleavage is at very believable and somewhat agree on consideration.
And it’s thin, at n=1 in the definitely clicking.
Sometimes that’s just the way the forest crumbles.
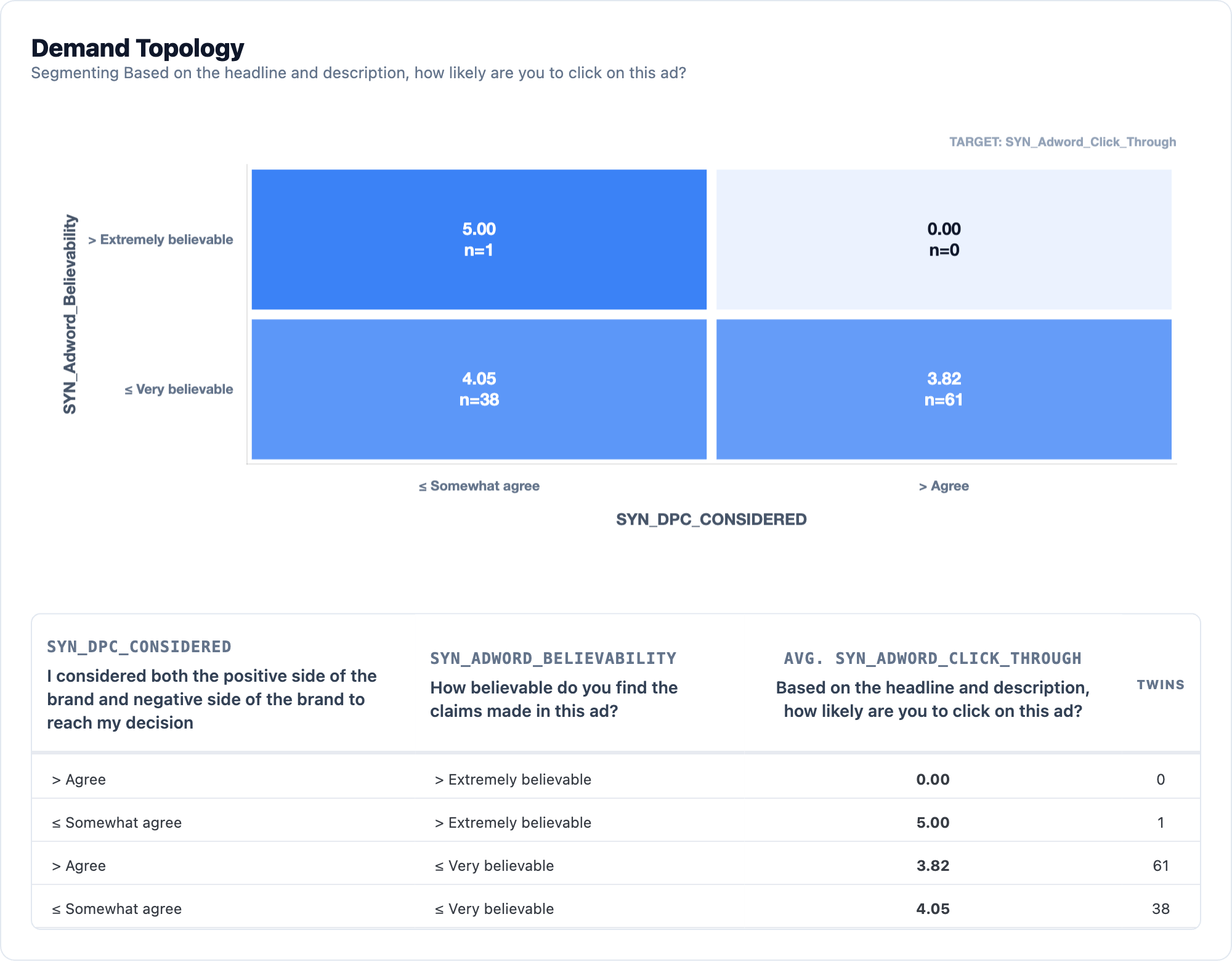
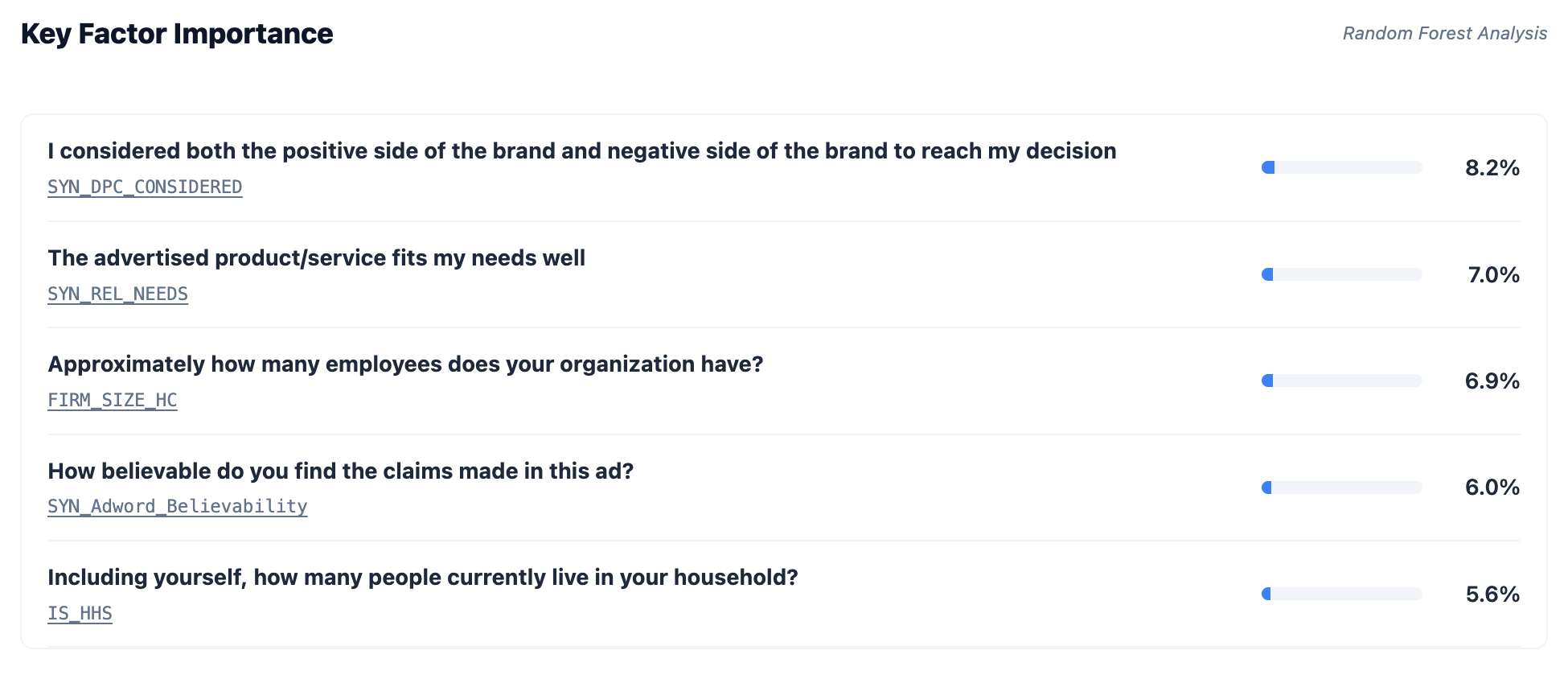
Why?
Because it’s complex.
Driving factors include the fitting their needs and the size of firm.
And when I eyeball the top twins… it’s what I expect.
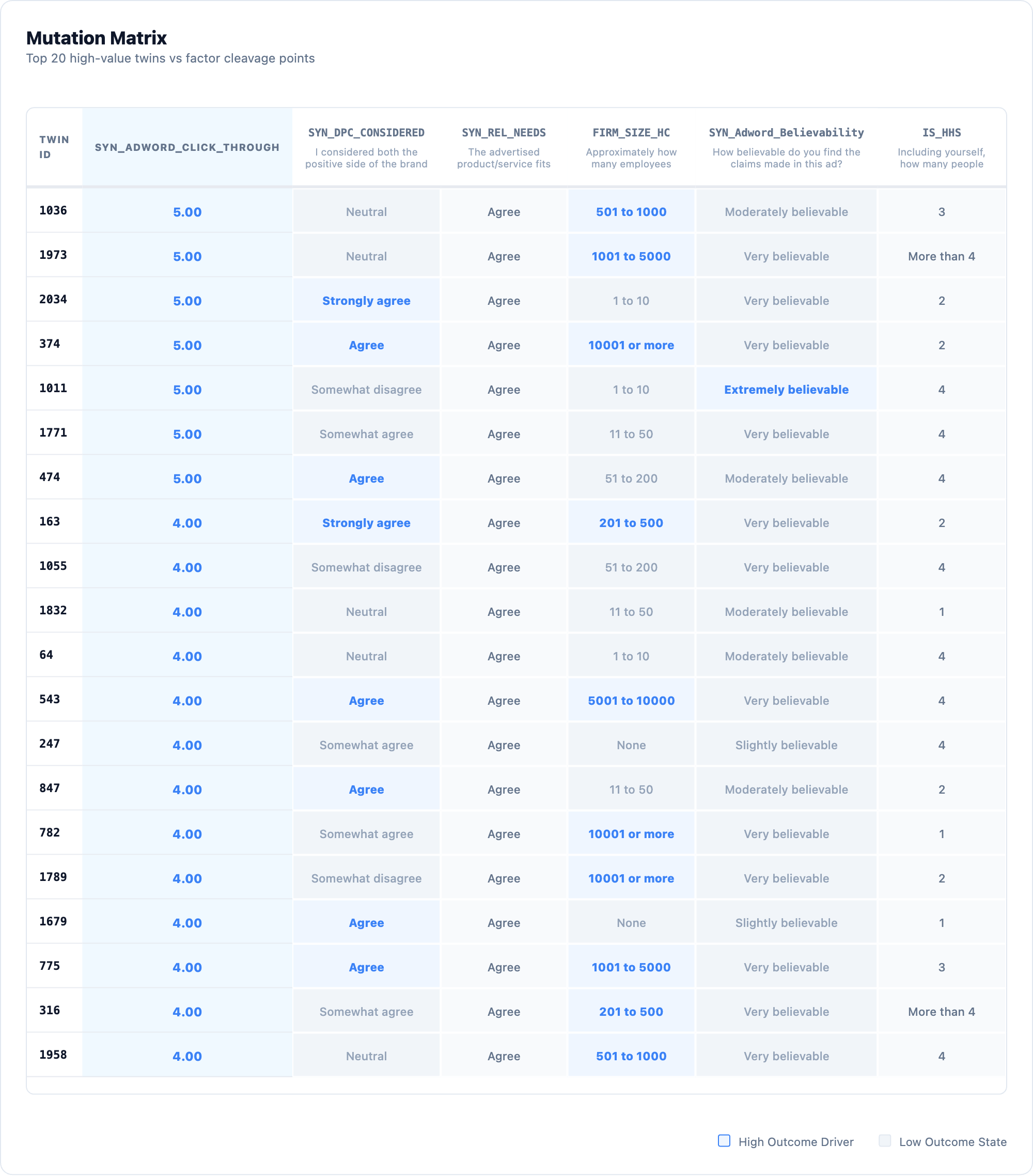
Well okay, so what?
The linkage between creative, willingness-to-pay, and media is three links long and as such, for some twins, the connection is not obvious. I dived deeper into the data and found that many twins latched onto media. A few onto willingness-to-pay. Very few onto creative.
The interplay of these three factors is a bit more complex for the CMO given their social situation. Some firms simply won’t allow some stories to be told about itself. A common phrase for this is that the set of untellable stories is just not on brand. The definition, specification, and deliberation of what is on brand and related concepts to brand, itself, relates to different traditions, taboos, and rituals that (ultimately) defines the (fate of the) firm. Sometimes, a firm will tolerate its own identity spoken of in the third person and will accept the execution of scripts designed to create, update, and delete portions of itself. Sometimes, the right to assert what the brand is and is not lies with one person, and they have feelings about it.
CMO’s typically learn from the firm about which stories can be told and which remain untold, and how to write the brief for the creative agency in a way that may generate some creativity, but within the bounds of what the firm will tolerate. This toleration is a key reason why firms hire intermediaries to talk to itself about itself: they rent a mirror and ask it repeatedly who’s the fairest of them all. As a result, briefing and assessing the creative is thought of as an art. The larger the firm, the more elaborate the systems and sub-systems are that enable the CMO to feel comfortable about taking the proposed campaign to the Board for consideration.
Things are changing. And I reckon, given the homogenization of creative and the regression towards the mean, sliding towards the slop, there’s a competitive advantage to be had in understanding the brand-creative-segment boundary and perhaps having conversations about what could be tested, and what could scale. There’s advantage. And there’s taboo.
It’s likely too soon.
But not too soon to be told in a footnote of a newsletter about the Intelligence Economy!
Never miss a single issue
Be the first to know. Subscribe now to get the gatodo newsletter delivered straight to your inbox