Not just a piecemeal compilation of individual transactions
This week: Wider or deeper, talent slap fight, strategy problems, good description, Hilbert’s sixth problem
Wider or deeper? scaling llm inference-time compute with adaptive branching tree search
One…then the other.
“Recent work has shown that inference-time scaling, namely allocating more computation at inference time, can markedly boost the performance of large language models (LLMs) on complex tasks. As outlined in Section 2, existing approaches to inference-time scaling fall into three broad categories: (1) post-training fine-tuning, (2) reward-guided chain-of-thought (CoT) generation, and (3) multiple answer generation. In this paper, we focus on the third category. The multiple answer generation approach repeatedly queries an LLM at non-zero temperature to produce a set of candidate outputs and then selects the most promising one. This approach enhances the LLM’s problem-solving abilities on-the-fly, without further training [1–11]. Because it is orthogonal to the other two families, it can be seamlessly combined with them.”
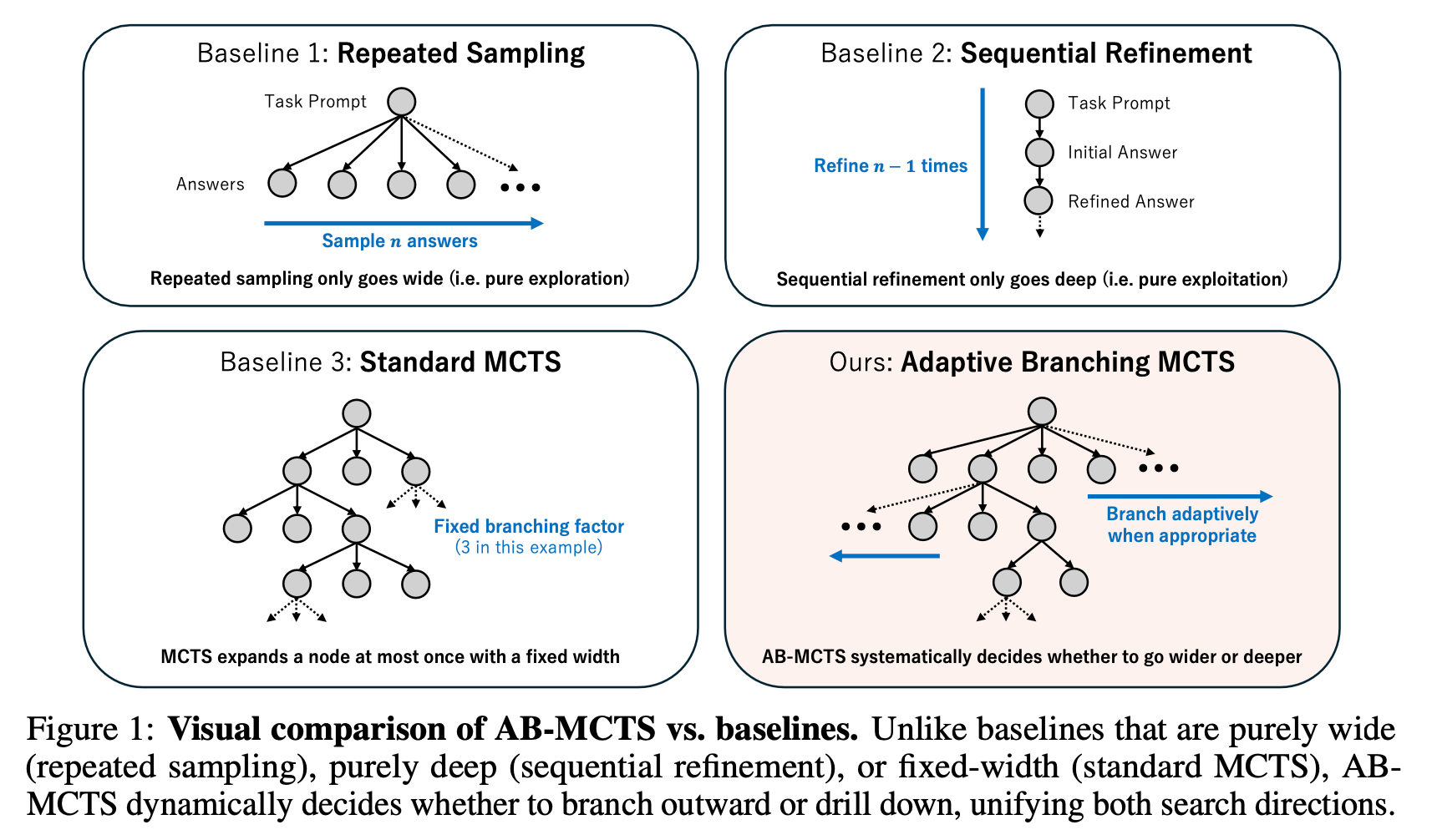
“This paper introduced Adaptive Branching Monte Carlo Tree Search (AB-MCTS), a novel inference- time framework to enhance LLM performance on complex tasks by effectively integrating multi-turn exploration and exploitation. Unlike previous methods, AB-MCTS dynamically decides to “go wider” or “go deeper” based on external feedback, leveraging Bayesian decision-making. Our experimental results show AB-MCTS outperforms repeated sampling and standard MCTS, demonstrating the value of adaptively handling the challenge of unbounded branching for effective inference-time scaling.”

Misaki, K., Inoue, Y., Imajuku, Y., Kuroki, S., Nakamura, T., & Akiba, T. (2025). Wider or deeper? scaling llm inference-time compute with adaptive branching tree search. arXiv preprint arXiv:2503.04412.
https://arxiv.org/pdf/2503.04412
Top Talent
The rhetoric is intriguing and…baffling?
“Andrew Bosworth, chief technology officer at Meta, said that not everyone is getting a $100 million offer during a Q&A with employees last week. “Look, you guys, the market's hot. It's not that hot. Okay? So it's just a lie,” he said. “We have a small number of leadership roles that we're hiring for, and those people do command a premium.” He added that the $100 million is not a sign-on bonus, but “all these different things” and noted OpenAI is countering the offers.”
“As Mark Zuckerberg staffs up Meta’s new superintelligence lab, he’s offered top tier research talent pay packages of up to $300 million over four years, with more than $100 million in total compensation for the first year, WIRED has learned.
Meta has made at least 10 staggeringly high offers to OpenAI staffers, sources say. One high ranking researcher was pitched on the role of chief scientist but turned it down, according to multiple sources with direct knowledge of the negotiations. While the pay package includes equity, in the first year the stock vests immediately, sources say.”

Altman:
“We have gone from some nerds in the corner to the most interesting people in the tech industry (at least),” he wrote on Slack. “AI Twitter is toxic; Meta is acting in a way that feels somewhat distasteful; I assume things will get even crazier in the future. After I got fired and came back I said that was not the craziest thing that would happen in OpenAl history; certainly neither is this.”
“Altman struck a different tone about the departures in his note on Monday.
“Meta has gotten a few great people for sure, but on the whole, it is hard to overstate how much they didn't get their top people and had to go quite far down their list; they have been trying to recruit people for a super long time, and I've lost track of how many people from here they've tried to get to be their Chief Scientist,” he wrote. “I am proud of how mission-oriented our industry is as a whole; of course there will always be some mercenaries.”
He added that “Missionaries will beat mercenaries” and noted that OpenAI is assessing compensation for the entire research organization. “I believe there is much, much more upside to OpenAl stock than Meta stock,” he wrote. “But I think it's important that huge upside comes after huge success; what Meta is doing will, in my opinion, lead to very deep cultural problems. We will have more to share about this soon but it's very important to me we do it fairly and not just for people who Meta happened to target.”
https://www.wired.com/story/mark-zuckerberg-meta-offer-top-ai-talent-300-million/
https://www.wired.com/story/sam-altman-meta-ai-talent-poaching-spree-leaked-messages/
Strategy, Problems, and a Theory for the Firm
Organized anarchy is in the eye of the beholder
“Thus firms are not just a piecemeal compilation of individual transactions or even a bundle of problems and solutions governed in a certain manner. Nor is value creation simply the act of scanning for need-solution pairs. Rather, firms represent a perspective and point of view—a theory for the firm—about how value might be orchestrated on the whole, and the set of problems and solutions that need to be solved and governed to create that value.”
“Our central point is that the firm’s theory represents its unique, forward-looking projection of how to meet a particular customer demand, one that currently is not being filled. While the theory of the firm establishes boundaries, our broad effort with the theory for the firm is to establish how the firm makes decisions about the full bundle of problems and solutions that it needs to engage with in the first place as it seeks to create value.”
Felin, T., & Zenger, T. R. (2016). CROSSROADS—Strategy, Problems, and a Theory for the Firm. Organization Science, 27(1), 222-231.
Good Description
Because it’s a good description
“Good descriptive questions seek to uncover facts in need of explanation, build theory, or help to evaluate and revise theory. Second, we articulate three ideal characteristics of descriptive analyses. Good descriptive analyses are clear, comparable, and complete. Such analyses should be tightly and transparently linked to specific research questions (and thus theory), well contextualized, and as comprehensive – in their measurement and specification – as possible.”
“The distinguishing feature of causal and descriptive questions is manipulability: if at least one concept or variable in a given research question is required to be manipulable for the question to be answerable, then that question is causal. If manipulability is not necessary to answer the question, then that question is descriptive. For example, if we ask whether A and B correlate we do not require manipulability of either A or B – we are not engaged in counterfactual reasoning and so the question is descriptive.”
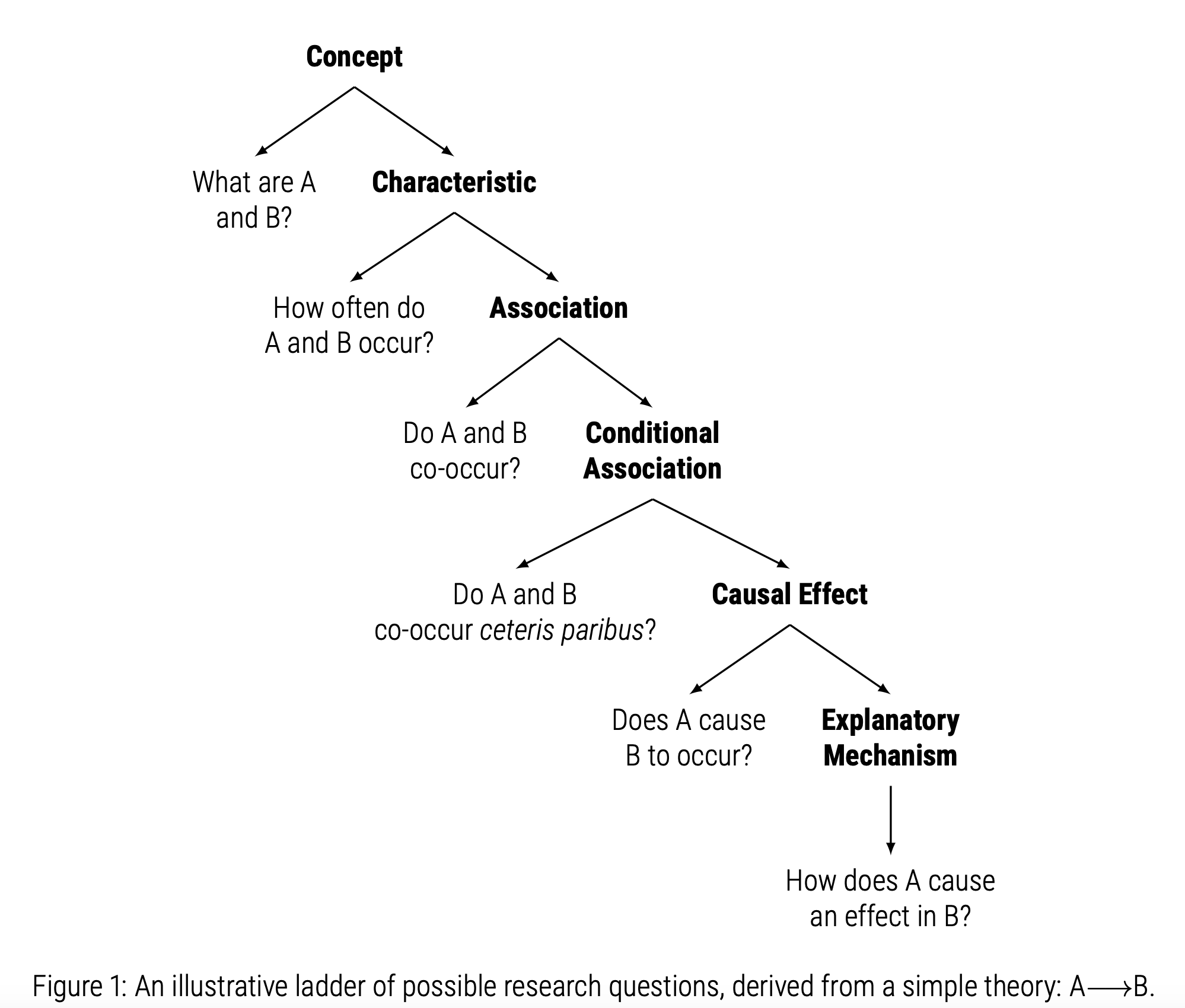
de Kadt, D., & Grzymala-Busse, A. (2025). Good Description.
https://github.com/ddekadt/good_description/blob/main/good_description_ddk_agb.pdf
Hilbert's sixth problem: derivation of fluid equations via Boltzmann's kinetic theory
If they’re using (random) forests (?) to keep track of atoms, from the basement, up…then that would be cool and extremely useful!
“Hilbert’s sixth problem. In his address to the International Congress of Mathematics in 1900, David Hilbert proposed a list of problems as challenges for the mathematics of the new century. Of those problems, the sixth problem asked for an axiomatic derivation of the laws of physics. In his description of the problem, Hilbert says:
"The investigations on the foundations of geometry suggest the problem: To treat in the
same manner, by means of axioms, those physical sciences in which already today
mathematics plays an important part; in the first rank are the theory of probabilities
and mechanics."

Deng, Y., Hani, Z., & Ma, X. (2025). Hilbert's sixth problem: derivation of fluid equations via Boltzmann's kinetic theory. arXiv preprint arXiv:2503.01800.
https://arxiv.org/abs/2503.01800
https://www.youtube.com/watch?v=mxWJJl44UEQ
Reader Feedback
“How do you know when to stop? Some guys say they’re doing 125 startups before they land on a good one.”
Footnotes
Suspend disbelief and imagine training an LLM on all the tokens that existed up to say, 300 CE. There’d be quite a bit of wisdom there. Very agricultural.
Suspend disbelief and imagine training an LLM on all the tokens that will have existed up to say, 3300 CE. Lots of wisdom there. And who knows. Maybe it would also be very agricultural.
Arguably, there’s just a lot more training data available today than in the past. And perhaps it would be upsetting to talk about the relative quality of the tokens as well. There’s just a lot more to explore. There’s just a larger search space — because each token in the set — and every parameter in the model, represents a crystallization of the collective.
It would seem that we’re running low on novel tokens, eh?
I like to rummage through the abiogenesis literature — how the collection of functions we call life got started. It’s fun to think of molecules as the original tokens. How did metabolism get started and how was the chemical knowledge for metabolism encoded in the first place? I vaguely remember a calculation, that if the planet was a certain temperature for a period of time after the Great Impact and enough water had condensed, how much time did the molecules on the planet have to combine to discover metabolism at least once? And I remember that it was something like…60 million years was enough time for some countably suitable number, something with a double digit exponent in it, of experiments to happen. A lot of runway for all the biopotential mass to figure out the discovery of information.
I wonder about giving a program a few molecules, like those in Ithkuil, give it an environment, and how much time it would take to figure itself out?
Never miss a single issue
Be the first to know. Subscribe now to get the gatodo newsletter delivered straight to your inbox