repetitive, redundant and grammatically disastrous
This week: Visual privacy management, multi-token prediction potential, ecommerce search, inequality
Visual Privacy Management with Generative AI for Blind and Low-Vision People
It would make the product better for everyone
“Our findings reveal a range of current practices with GenAI that balance privacy, efficiency, and emotional agency, with users accounting for privacy risks across six key scenarios: self- presentation, indoor/outdoor spatial privacy, social sharing, and handling professional content. Our findings reveal design preferences, including on-device processing, zero-retention guarantees, sensitive content redaction, privacy-aware appearance indicators, and multimodal tactile mirrored interaction methods.”

“Our participants expressed mixed feelings about relying on GenAI, similar to prior research on crowd-powered accessibility tools like VizWiz [24]. While our findings indicate the convenience of the GenAI tool in addressing long-standing challenges in manag- ing one’s privacy independently, the impersonal nature and lack of contextual awareness of GenAI could potentially amplify privacy concerns.”

“Federated Compliance-Aware GenAI: Secure Toolkit for BLV Professional. Our findings revealed a distinct concern around protecting others’ privacy when BLV professionals use GenAI in institutional contexts like banking, education, or social services, where users often process sensitive data on behalf of others. In response, we propose a secure GenAI toolkit that integrates with compliance-aware platforms (e.g., SharePoint, OneDrive, Google Workspace) to handle documents locally or in secure federated and decentralized environments [63, 78]”
Sharma, T., Tseng, Y. Y., Zhang, L., Ide, A., Mack, K. A., Findlater, L., ... & Wang, Y. (2025). Visual Privacy Management with Generative AI for Blind and Low-Vision People. arXiv preprint arXiv:2507.00286.
https://arxiv.org/pdf/2507.00286
Your LLM Knows the Future: Uncovering Its Multi-Token Prediction Potential
Skipping ahead and windowing
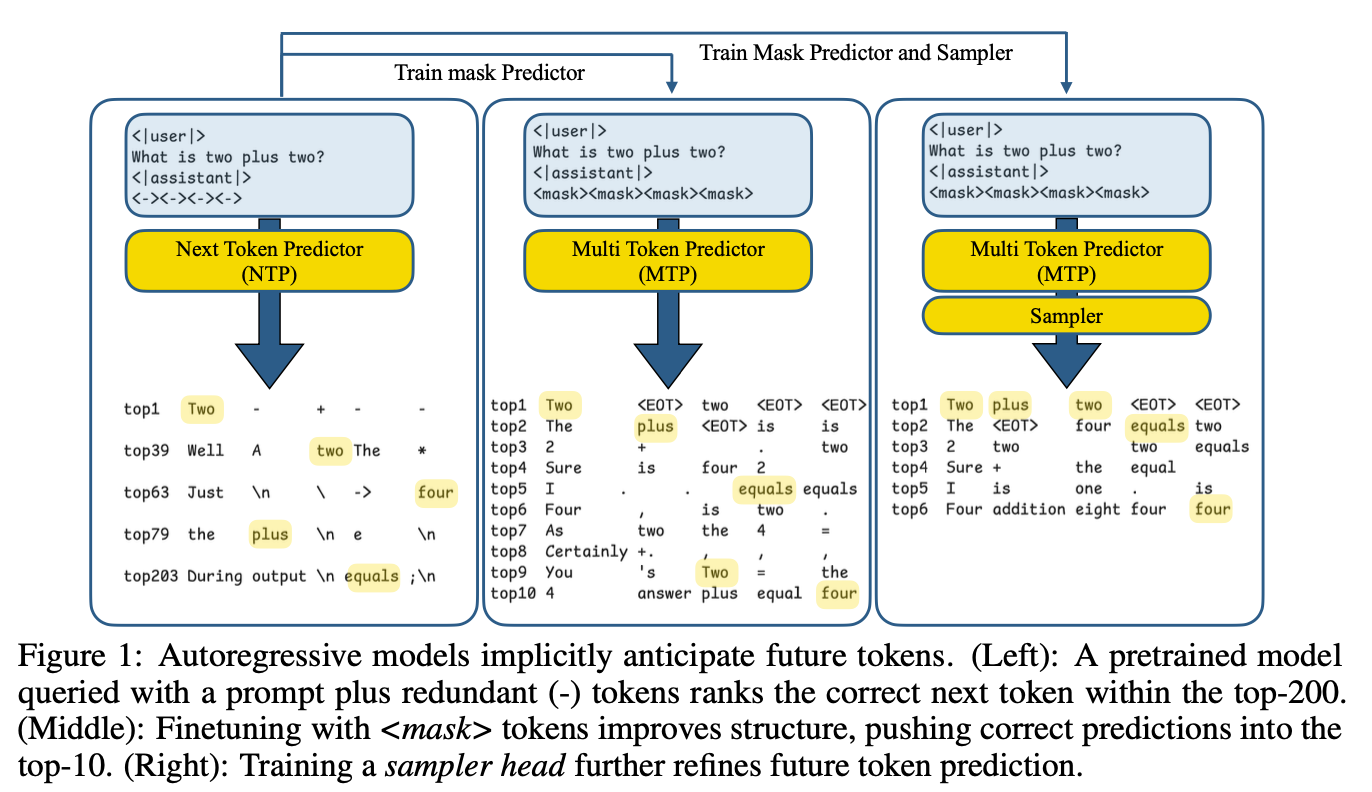
“We start from the observation that vanilla, autoregressive, language models contain large amounts of information about future tokens beyond the immediate next token.”
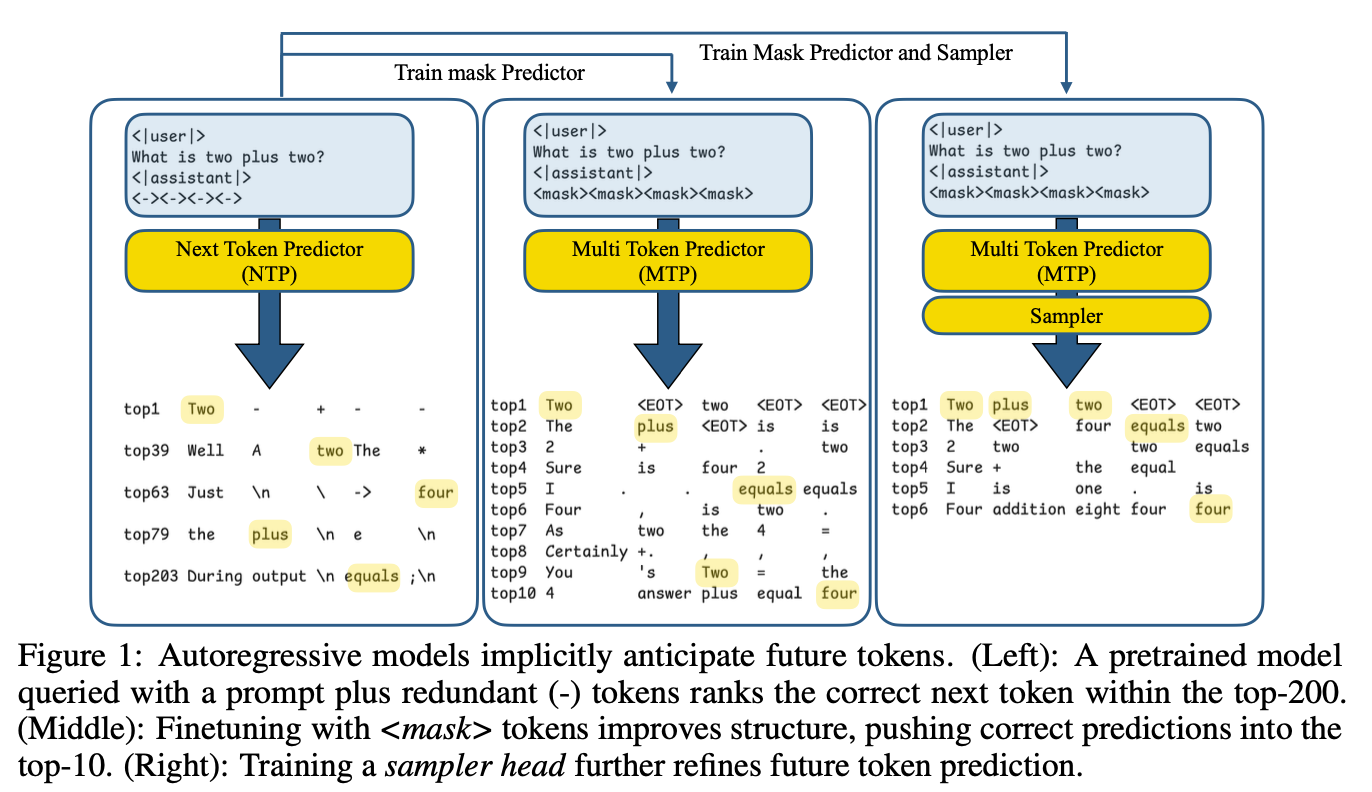
“We then explored and combined various techniques to materialize the potential of autoregressive models to generate multiple tokens. We craft a training recipe with mask tokens which can better the prediction accuracy for future tokens, while maintaining the performance of the immediate next token generation. Using speculative decoding, we provide an important measure by which we can evaluate the amount of usable information (beyond simple, token-wise independent metrics, perplexity, etc.).”
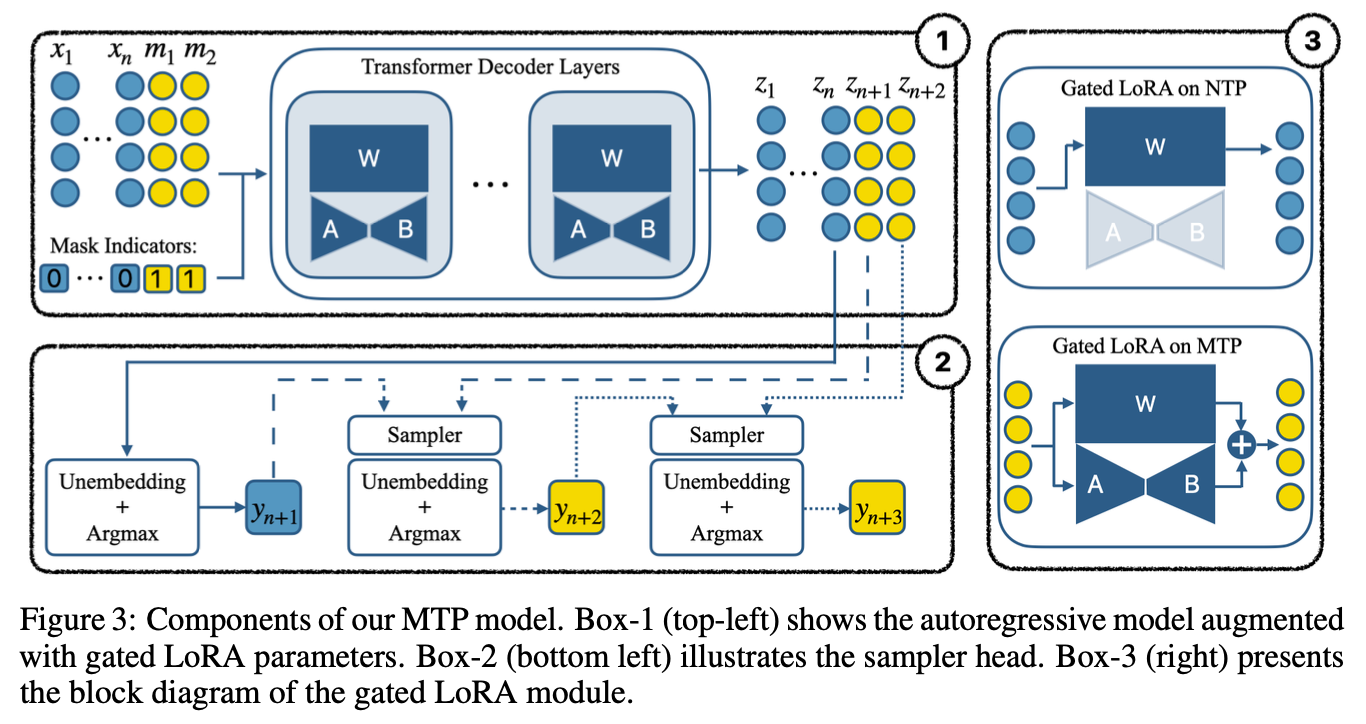
“Using this metric, we show that additional improvements to the modeling of future tokens can be made with lightweight additions to the base model that do not compromise its autoregressive generation performance.”
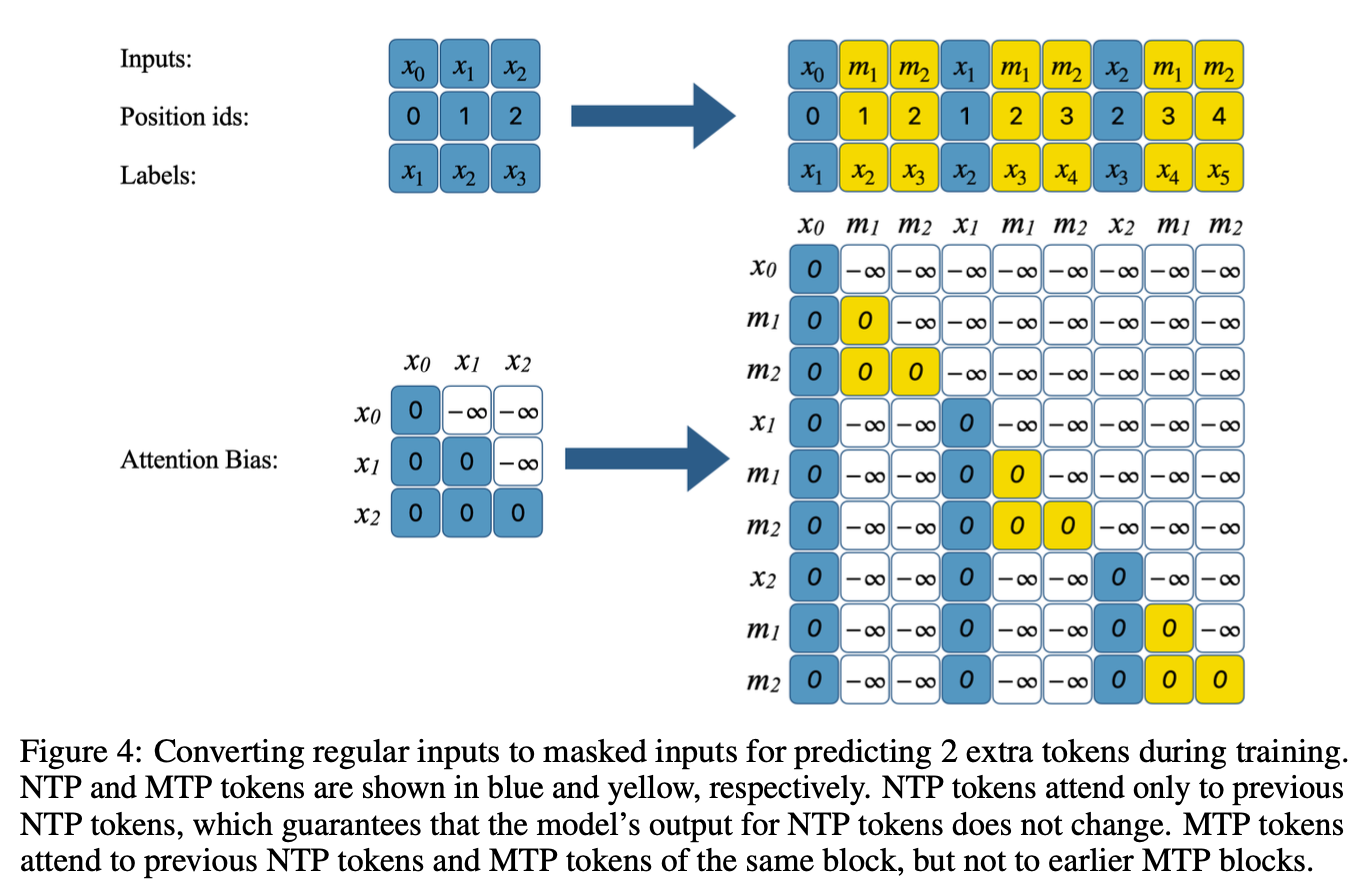
”We have evaluated how well autoregressive models can adapt to multi-token prediction during the supervised fine-tuning stage of language model training. A promising direction for future work is to explore the impact of this approach during pretraining or downstream task adaptation. Another compelling avenue is to investigate diffusion-based generation for multi-token prediction. We believe that multi-token prediction lies between fully autoregressive and fully diffusion-based generation methods, offering a balanced combination of advantages from both ends of the spectrum.”
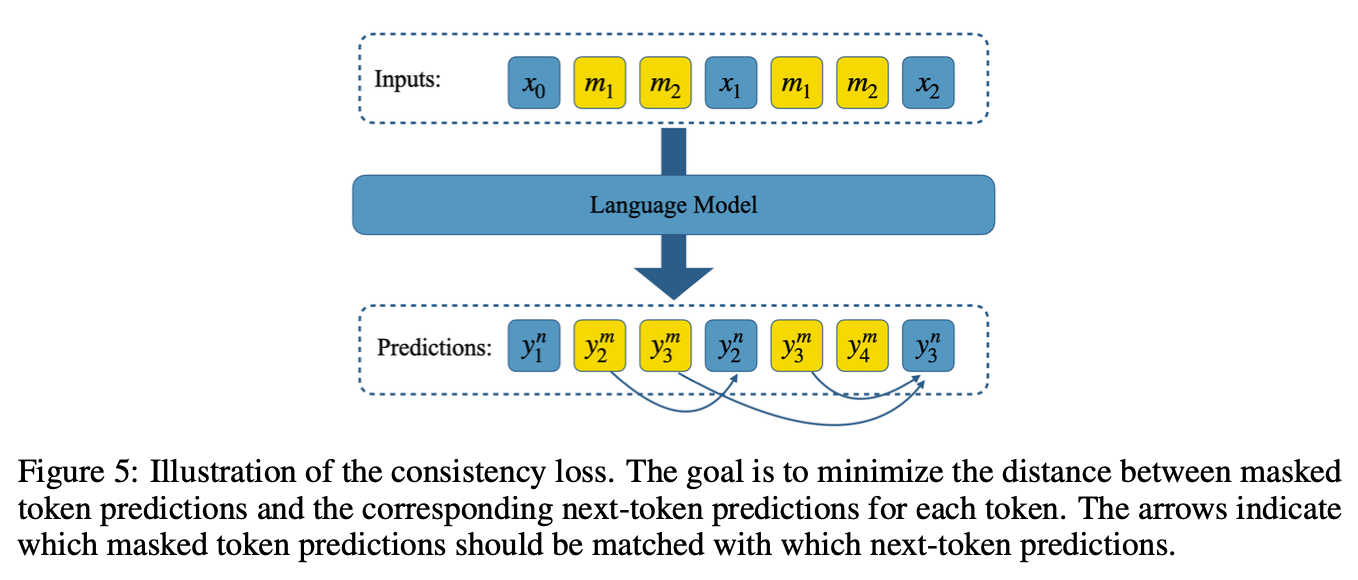
“Our method achieves significant speedups through supervised fine-tuning on pretrained models. For example, it generates code and math nearly 5× faster, and improves general chat and knowledge tasks by almost 2.5×. These gains come without any loss in quality.”
Samragh, M., Kundu, A., Harrison, D., Nishu, K., Naik, D., Cho, M., & Farajtabar, M. (2025). Your LLM Knows the Future: Uncovering Its Multi-Token Prediction Potential. arXiv preprint arXiv:2507.11851.
https://arxiv.org/pdf/2507.11851
Pre-training tasks for user intent detection and embedding retrieval in e-commerce search
“Typical e-commerce text examples that are repetitive, redundant and grammatically disastrous”
“In this paper, we have proposed carefully designed, customized pre- training tasks for two critical modules, user intent detection and embedding retrieval in a leading e-commerce search system, since the e-commerce text data are very different from general corpus such as Wikipedia where the official BERT is trained from. As a result, our customized pre-trained models significantly improve no pre-trained models and outperform the official pre-trained BERT models, on both offline evaluation and online A/B test.”

“Motivated by achieving real world impact from the very beginning, we conduct A/B test on a leading e-commerce search system, using 20% of the entire site traffic during a period of 30 days. Due to the confidential business information protection, we only report the relative improvements in Table 6, where the online baseline models are BiGRU [11] for user intent detection and DSPR [28] for embed- ding retrieval. The gross merchandise value (GMV), the number of unique order items per user (UCVR), and the click-through rate (CTR) are significantly improved.”
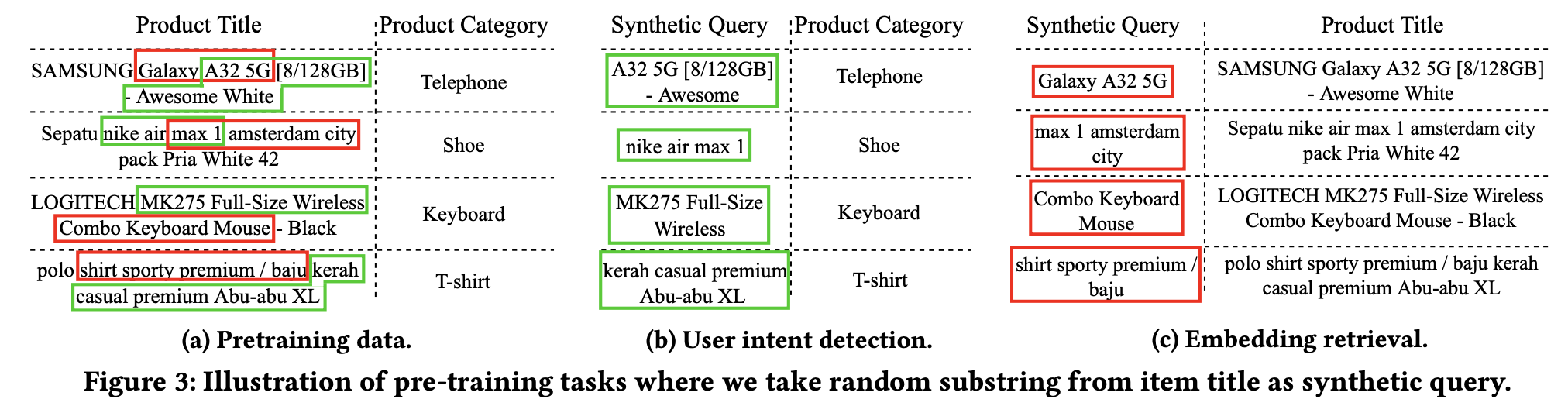
Qiu, Y., Zhao, C., Zhang, H., Zhuo, J., Li, T., Zhang, X., ... & Yang, W. Y. (2022, October). Pre-training tasks for user intent detection and embedding retrieval in e-commerce search. In Proceedings of the 31st ACM International Conference on Information & Knowledge Management (pp. 4424-4428).
https://arxiv.org/pdf/2208.06150
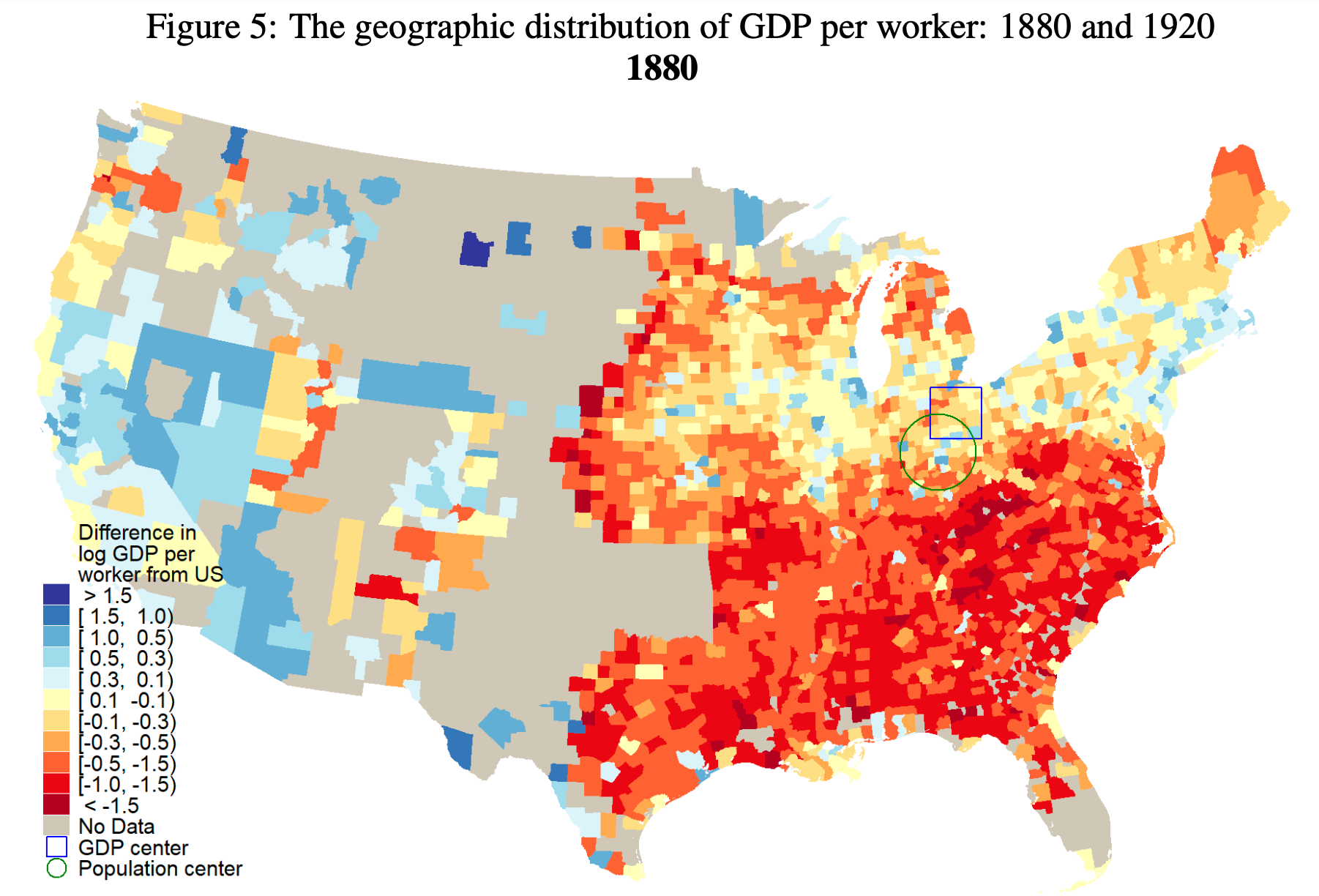
Still Growing Together?: The Spatial Distribution and Industrial Composition of US County GDP Since 1870
The context we’re pouring AI into
“We construct the first estimates of U.S. county nominal and real GDP by broadly defined industrial sectors from 1870 to 2018. Counties tended to converge from 1870 until 1970, but subsequently grew apart. Falling GDP per worker inequality between states explains most of the fall in nationwide county inequality from 1870 to 1970. After 1970, increasing inequality within states explains most of the overall inequality increase. Before 1970, more productive states were more equal, after 1970 more productive states were more unequal. U.S. geographic inequality is no longer primarily about differences between regions or states, but instead about differences within them. We show how the changing industrial composition affects inequality. The path to riches has changed from manufacturing to tradable services. From 1870 to 1950, manufacturing became increasingly geographically concentrated in the richest counties. The manufacturing share is now the highest in middle income counties, while the richest coun- ties increasingly produce tradable services. Manufacturing’s contribution to GDP per worker inequality is the largest before 1960 and its decline is the main explanation for inequality’s fall from 1930 to 1970, while the growth of tradable services and their concentration in top metropolitan areas contribute to the nominal inequality increase after 1970. Agriculture used to be the primary activity of the poorest counties. Now, the poorer the county, the larger the share in government, education, and health. Government services decrease county inequal- ity. We show that population growth and education used to be strongly pro-convergence, but after 1970 became neutral or anti-convergence. At the same time, agglomeration effects in manufacturing and tradable services appear to have increased.”
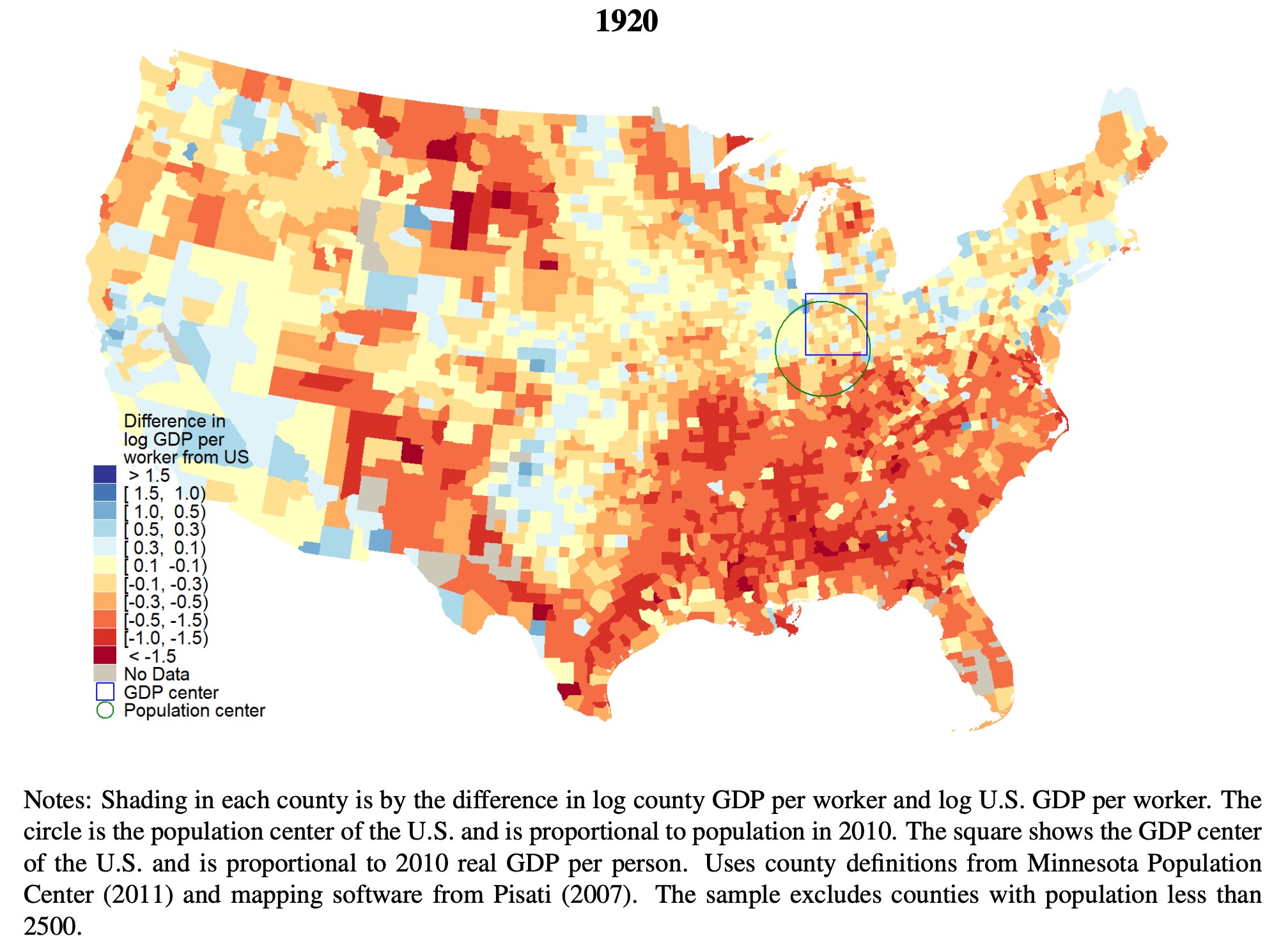
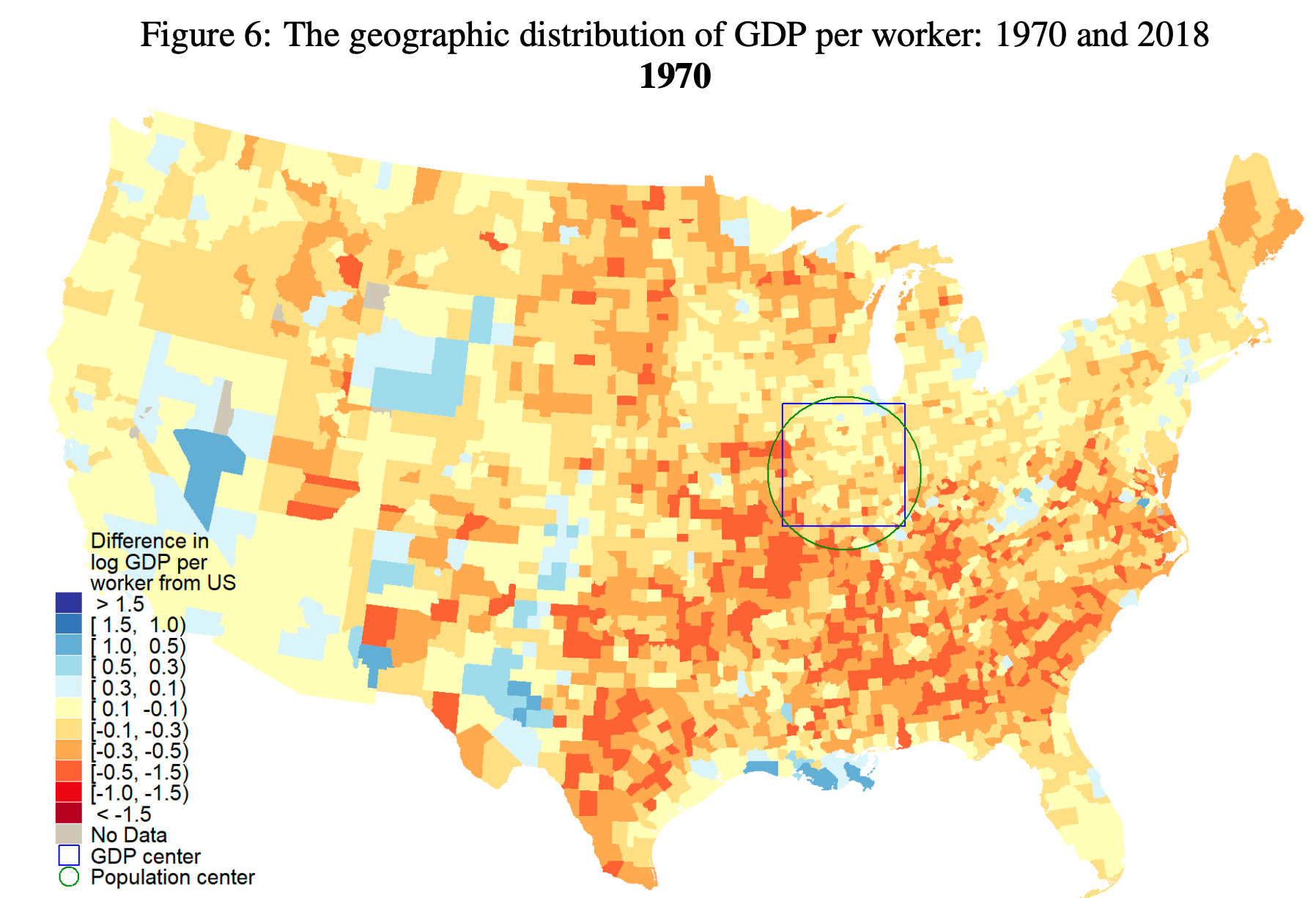
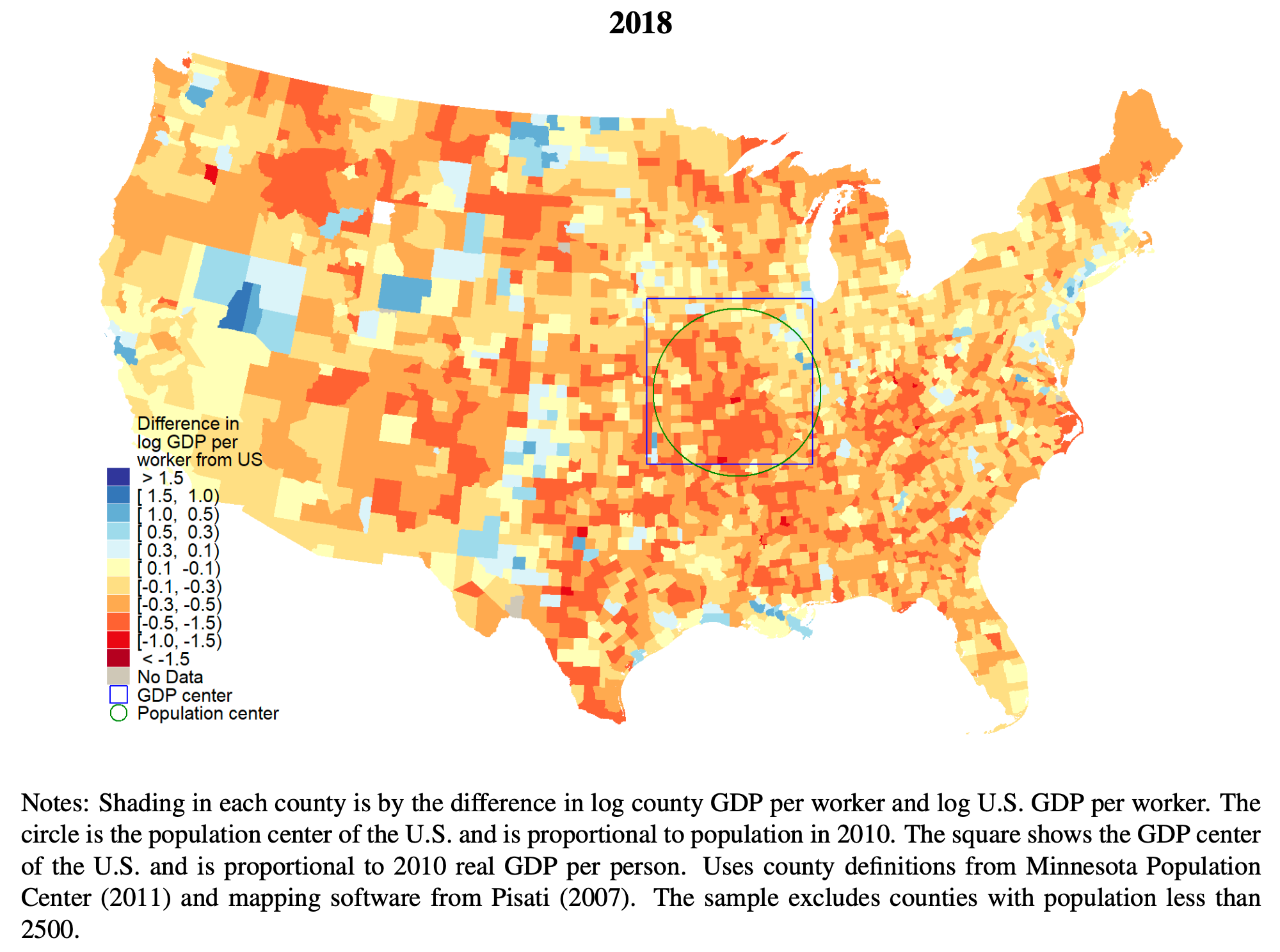
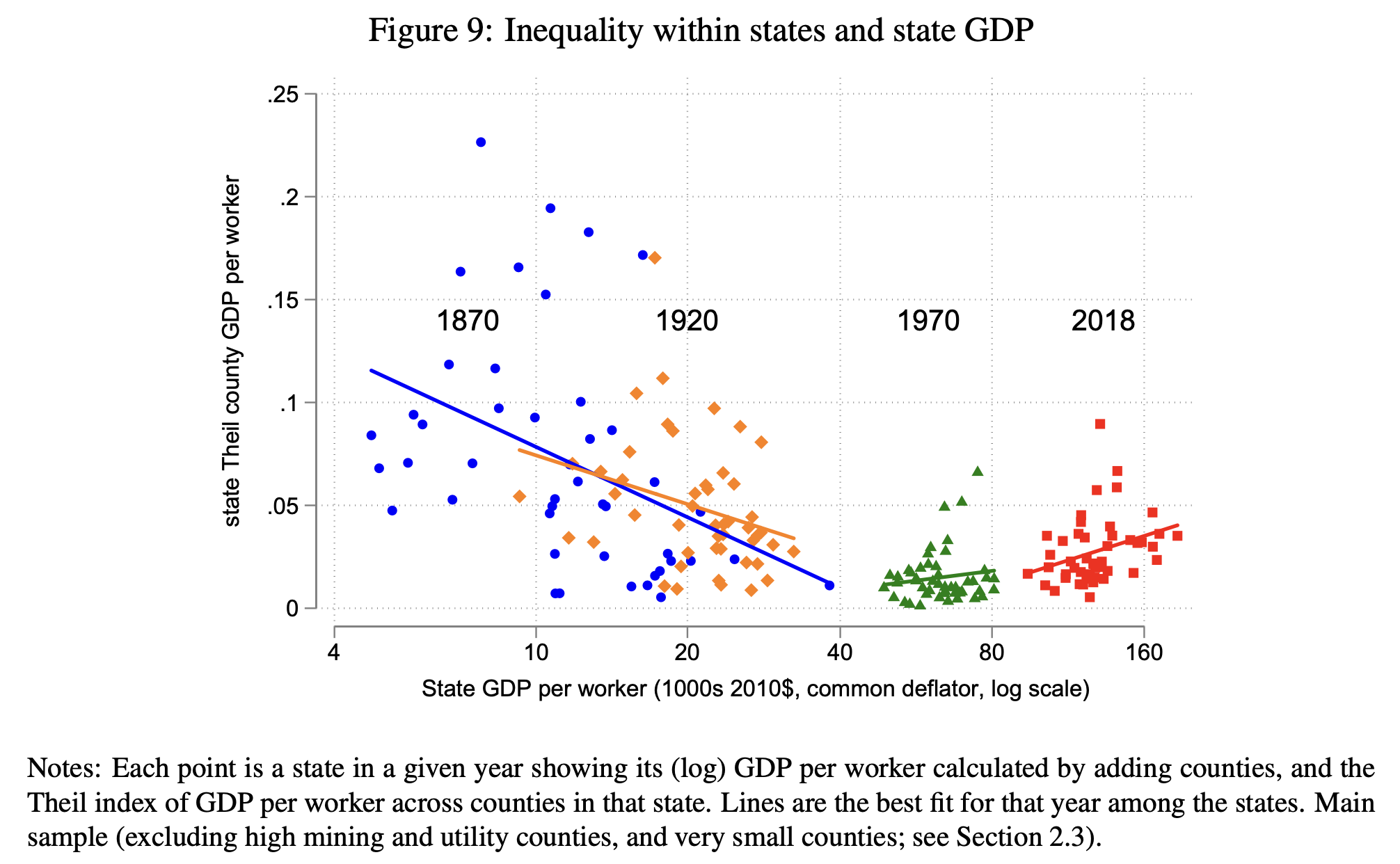
Fulford, S. L., & Schiantarelli, F. (2024). Still Growing Together?: The Spatial Distribution and Industrial Composition of US County GDP Since 1870. Boston College.
http://fmwww.bc.edu/EC-P/wp1081.pdf
Reader Feedback
“Maybe the illusion of reasoning is enough?”
Footnotes
Toronto has a tradition of ML/AI paper reads. Usually about a dozen people get together in a board room after hours, when the sun has long set, and they go over a paper. Sometimes these papers already been peer reviewed. Sometimes they’re pretty fresh. Sometimes the authors attend. Usually they don’t. Sometimes there’s a facilitator who has gone through the paper in advance and sometimes the group will read the paper together for the first time. Small groups are conducive to questions and we learn more through dialogue. The ubiquity of LLMs has led to people simply dumping the paper in and asking questions about it in real time.
The series that Anthony Susevski and Alvin Li have been hosting in Trinity Bellwoods park this summer are seriously great. We’ve enjoyed 8 consecutive dry weekends at 11, 12 or 1 with nice humidity and sometimes room temperatures. The papers and discussions are always interesting and informative.
It’s such a nice thing.
Check it out if you’re in Toronto.
Never miss a single issue
Be the first to know. Subscribe now to get the gatodo newsletter delivered straight to your inbox