Simple solutions remain optimal
This week: Strategic reasoning, lottery ticket hypothesis, ProRL V2, positron, black box agent testing, pufferlib, goodreads
Can Large Language Models Develop Strategic Reasoning? Post-training Insights from Learning Chess
LLM alone don’t have world models
“Reinforcement learning with verifiable rewards (RLVR)”
“…strategic reasoning—the ability to plan, anticipate adversary actions, and make decisions in multiagent environments. Beyond logical reasoning in static settings, strategic reasoning aligns more with real-world scenarios such as games, negotiation, and market competitions.”
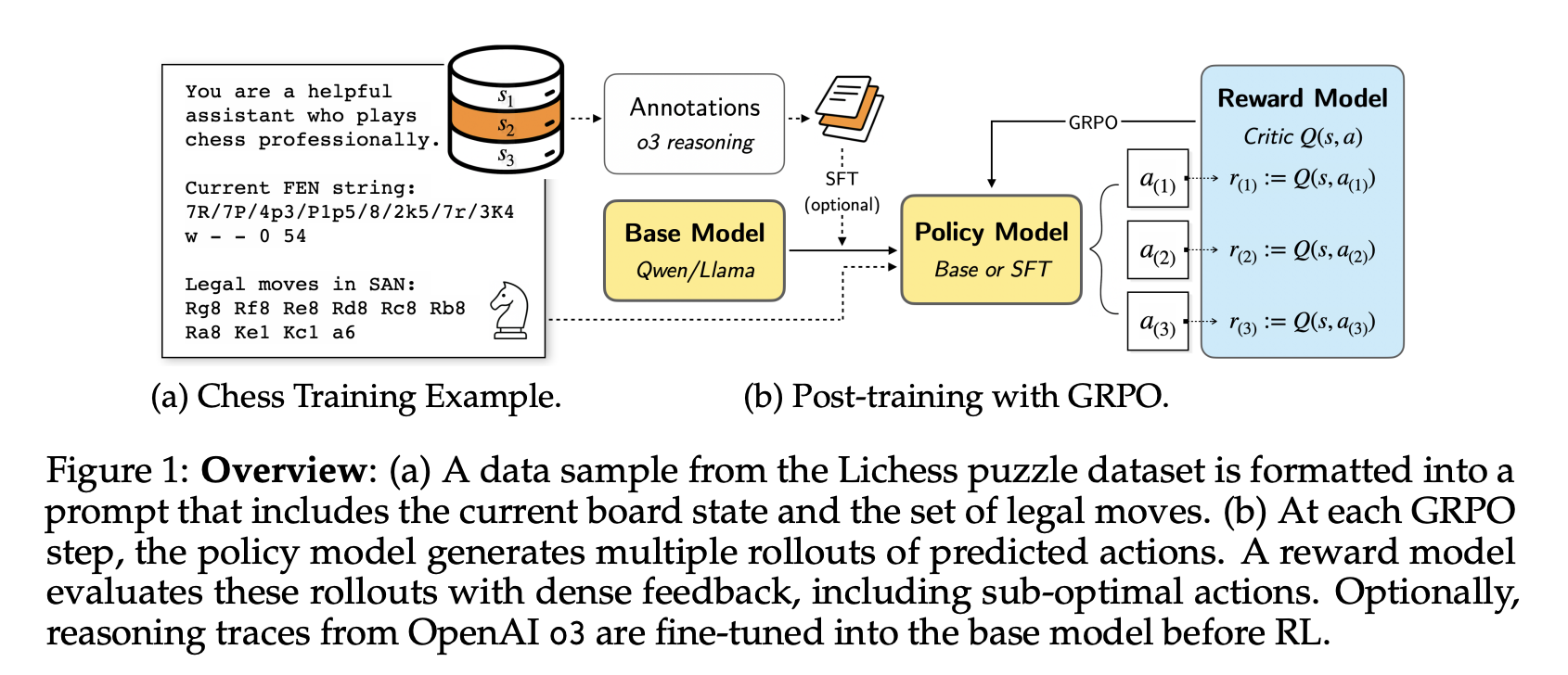
“To investigate this gap, we turn to chess, a strategic game demanding deep strategic reasoning abilities such as positional evaluation, long-term planning, and reasoning about an opponent’s intentions. In addition, chess offers a favorable environment for applying RLVR on LLMs, as it provides abundant publicly available game records and human-annotated reasoning about optimal moves. Given such a testbed for examining strategic reasoning, we raise the following research question:
Can LLMs develop strategic reasoning capabilities through RLVR with chess?”
“While LLMs produced markedly more comprehensive reasoning traces after reasoning SFT, Figure 3 shows that they disappointingly exhibited similar puzzle accuracy plateaus when subsequently trained with RL. In fact, Llama3.1-8B’s performance actually declined relative to its non-SFT baseline. These results raise questions about whether the reason behind the chess performance plateau stems not from inadequate reasoning abilities, but from insufficient chess knowledge. Without extensive domain knowledge from pre-training, RL alone may not provide the chess-specific understanding that strategic play demands.”
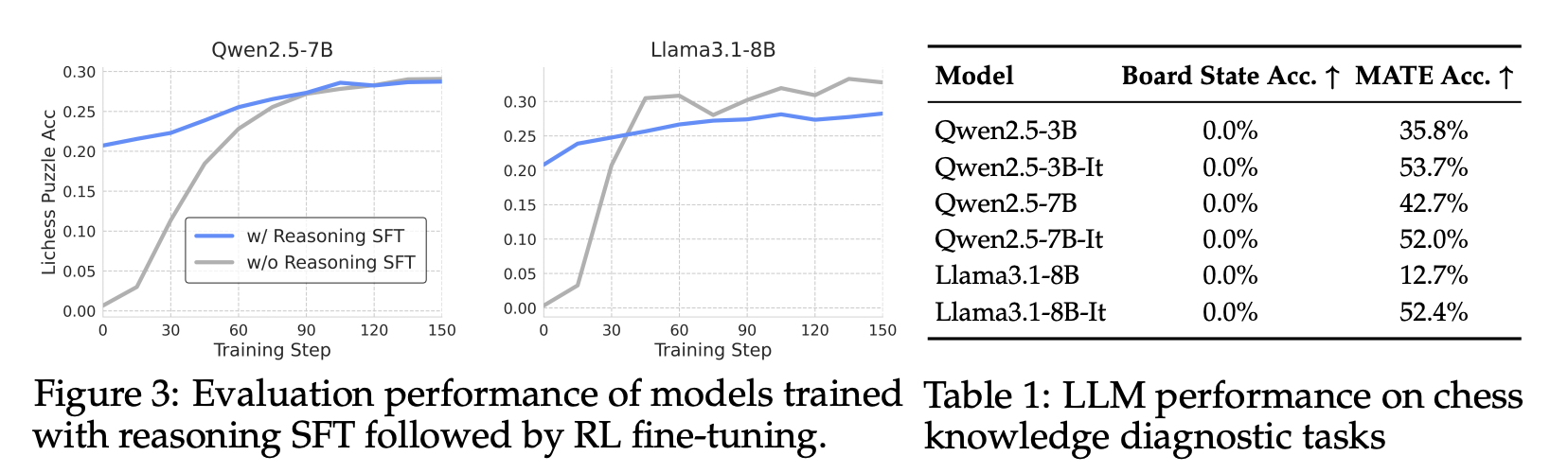
“We investigated whether LLMs can develop strategic reasoning through RLVR on chess, introducing a novel approach of using dense reward signals from pretrained action-value networks. While this dense expert often outperforms sparse rewards, all models plateau at performance levels well below human expert capabilities, revealing fundamental limitations in current post-training approaches. Surprisingly, despite producing more structured reasoning when trained on advanced traces from OpenAI o3, models still yield similar performance plateaus when subsequently trained with RL. Our failure analysis reveals a potential root cause: current LLMs demonstrate inadequate internal chess knowledge. These results raise speculation that RL cannot overcome impoverished domain knowledge. While RL excels at optimizing behavior toward rewards, LLMs cannot learn de novo the foundational knowledge necessary for strategic thinking when absent from pretraining.”
Hwang, D., Lee, H., Choo, J., Park, D., & Park, J. (2025). Can Large Language Models Develop Strategic Reasoning? Post-training Insights from Learning Chess. arXiv preprint arXiv:2507.00726.
https://arxiv.org/abs/2507.00726
Lottery Ticket Hypothesis
“Simple solutions remain optimal; we've discovered a better way to find them.”

“For over 300 years1, one principle governed every learning system: the bias-variance tradeoff. The mathematics was elegant, the logic unassailable. Build a model too simple, and it misses crucial patterns. Build it too complex, and it memorises noise instead of signals.”
“The field's most respected voices reinforced this orthodoxy. "Bigger models just overfit," became the mantra. Conference papers focused on efficiency, not scale. The idea that simply adding more parameters might solve problems was academic heresy.”
“The answer emerged from an unexpected corner: a study of neural network lottery tickets. In 2018, Jonathan Frankle and Michael Carbin at MIT were investigating pruning—removing unnecessary weights after training. Their discovery would provide the elegant solution to the scaling paradox.
Hidden within every large network, they found "winning tickets"—tiny subnetworks that could match the full network's performance. They could strip away 96% of parameters without losing accuracy. The vast majority of every successful network was essentially dead weight.”
“But here lay the crucial insight: these winning subnetworks only succeeded with their original random starting weights. Change the initial values, and the same sparse architecture failed completely.”
“The lottery ticket hypothesis crystallised: large networks succeed not by learning complex solutions, but by providing more opportunities to find simple ones. Every subset of weights represents a different lottery ticket—a potential elegant solution with random initialisation. Most tickets lose, but with billions of tickets, winning becomes inevitable.”
“The implications transcend artificial intelligence. If learning means finding the simplest model that explains data, and larger search spaces enable simpler solutions, this reframes intelligence itself.”
ProRL V2 - Prolonged Training Validates RL Scaling Laws
No ceiling…
“One of the most compelling questions in AI is whether large language models (LLMs) can continue to improve through sustained reinforcement learning (RL), or if their capabilities will eventually plateau.”

“ProRL fundamentally challenges this paradigm:
- Extended training: Over 3,000 RL steps across five distinct domains, achieving new state‑of‑the‑art performance among 1.5 B reasoning models.
- Stability and robustness: Incorporates KL-regularized trust regions, periodic reference policy resets, and scheduled length regularization.
- Fully verifiable rewards: Every reward signal is determined programmatically and is always checkable.
- Brevity enforced: Scheduled cosine length penalties ensure outputs remain concise and efficient.”
“Boundary breakthroughs: On tasks where base models always failed, ProRL not only achieves strong pass rates, but also demonstrates robust out-of-distribution generalization.”
“Our empirical results indicate that large language models can achieve sustained improvements in math, code, and reasoning tasks through prolonged reinforcement learning, surpassing the performance typically observed with conventional training routines. Our evaluation demonstrates robust gains across a wide array of benchmarks—including challenging and out-of-distribution tasks—suggesting that extended RL training can meaningfully expand a model’s reasoning capabilities.”
https://hijkzzz.notion.site/prorl-v2
Announcing Positron, a new Data Science IDE
It could make R more usable…
“If you are wondering about RStudio, please don’t worry – it’s not going away! RStudio includes 14+ years of R focused optimizations and we are committed to maintaining and updating RStudio.”
https://posit.co/blog/positron-product-announcement-aug-2025/
Black-Box Agent Testing with MCP
“Tl;dr: I propose a method for testing agents by defining tasks and expected outputs via an MCP server.”
“Notably, the only shared information between systems is the address where the MCP server is running. The test MCP server doesn't know any details about the agent; it doesn't even know whether the agent is running locally or remotely, it simply expects that the agent will communicate via that address. Likewise, the agent doesn't know any details about the test server other than the MCP address.”
https://gracekind.net/blog/mcpblackbox/
https://github.com/kindgracekind/mcp_harness
PufferLib
Getting smaller!
PufferLib is a fast and sane reinforcement learning library that can train tiny, super-human models in seconds. The included learning algorithm, hyperparameter tuning, and simulation methods are the product of our own research. All our tools are free and open source, but you can purchase priority service to get our eyes on your problem from $10k/month. We also offer fixed-deliverables terms for larger problems. Contact jsuarez🐡puffer🐡ai.
The demo below is running live 100% client side in your browser. Hold shift to take control!
Who decides what is read on Goodreads?
The powerful powered by the power law
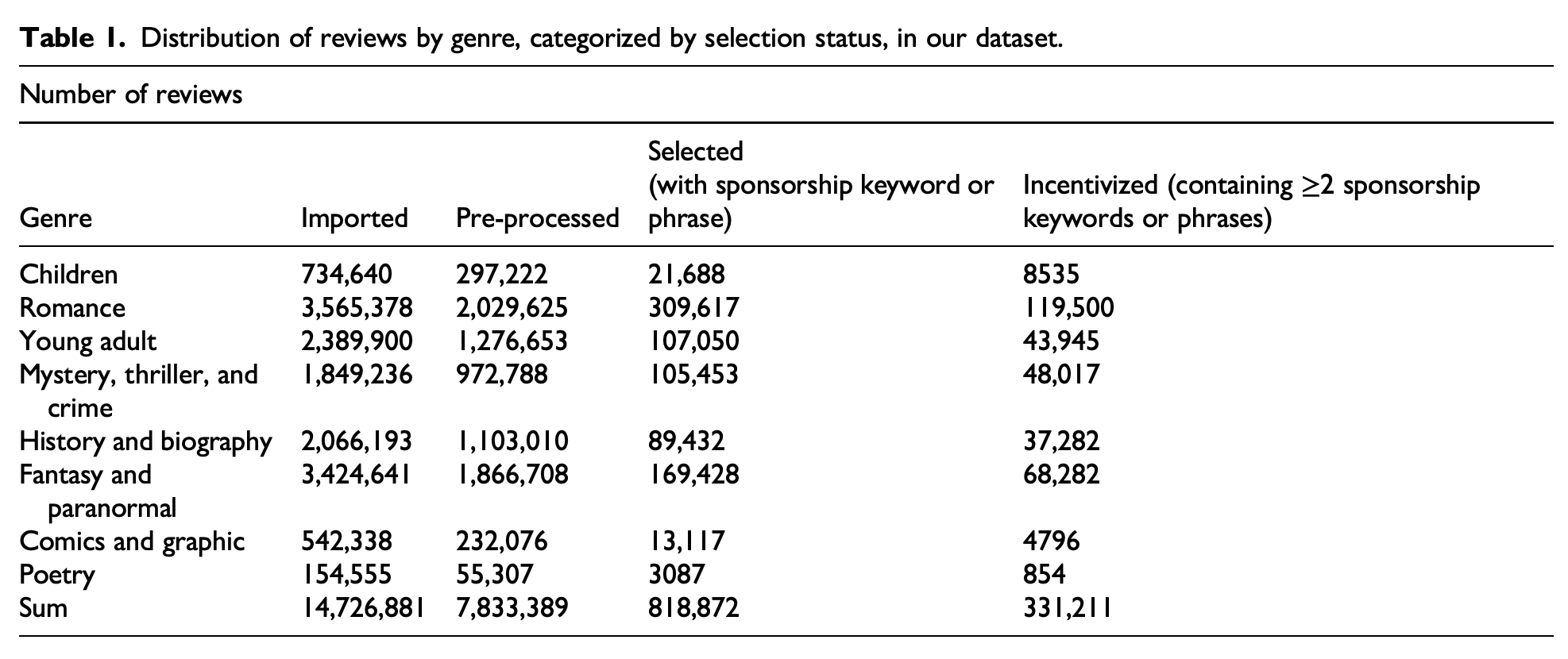
“Our research set out primarily to consider who gets to decide what is reviewed on Goodreads. This is a complex question, but we believe that examining incentivized book reviews is crucial to any assessment. We limited our analysis to the most clearly identifiable examples: reviews that explicitly self-disclose having received an incentive. While this likely underestimates the full extent of sponsored content, it provides a conservative and reliable basis for our study. From 2007 to 2016, percentages of self-identified incentivized reviews on Goodreads increased 100 times from approximately 0.06% to 6%, with particularly higher percentages among reviews of the most lucrative genre fiction.”
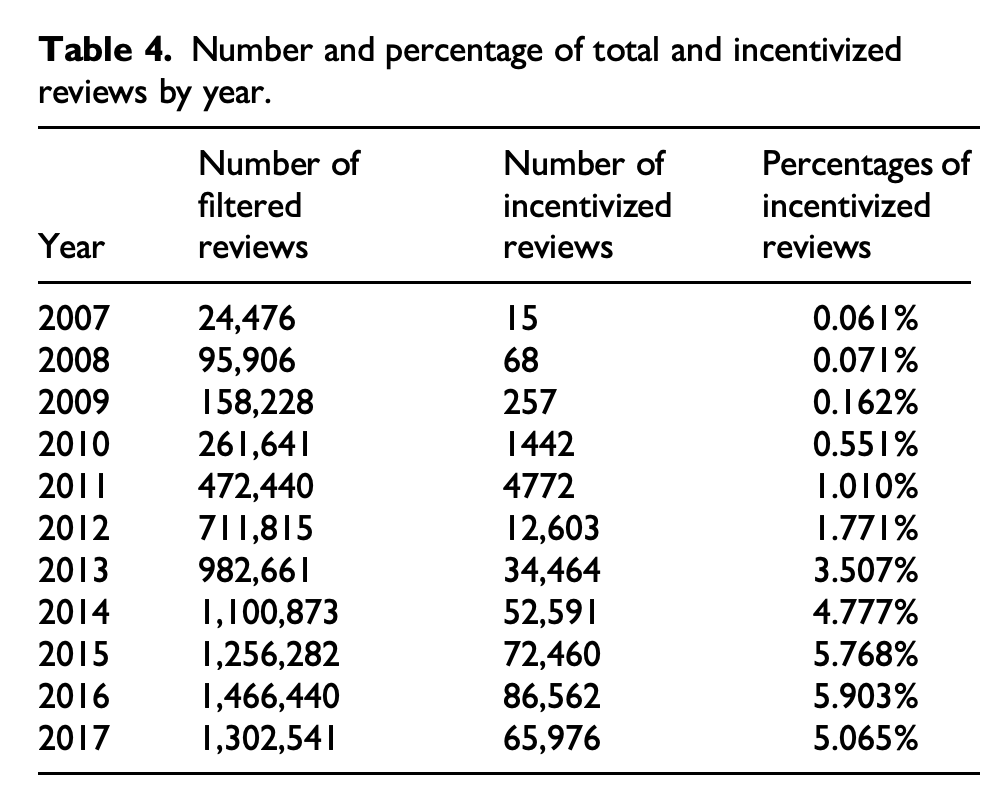
“Despite this increase, 80% of the incentivized reviews were attributable to only 13.66% of users who posted incentivized reviews; around 3.7% of these users overwhelmingly or exclusively posted incentivized reviews. This distribution indicates that even among the subset of users posting sponsored reviews, there remain differences in who gets access to these incentives. When looking at what books get reviewed, the results are as stark. A similar 80% of incentivized reviews––though to be clear not the same 80% of reviews produced by 13.66% of users––focus on books written by 27% of all authors on Goodreads, which are produced by an even smaller 10% of publishers.”
Hu, Y., Diesner, J., Underwood, T., LeBlanc, Z., Layne-Worthey, G., & Downie, J. S. (2025). Who decides what is read on Goodreads? Uncovering sponsorship and its implications for scholarly Research. Big Data & Society, 12(3).
Reader Feedback
“The org resists the tech because it doesn’t trust…it’s always been adversarial.”
Footnotes
While bulk of the public is discovering LLM’s and a whole new generation is introduced to the wonders of microservices, what’s happening in the labs to build world models?
Fix that bit and we get a lot.