The Boundary Problem
This week: Structured perspective inference, getting lost in context windows, boundary guidance, skillsbench, group evolving agents, expert engagement in treaty negotiations
Situation Graph Prediction: Structured Perspective Inference for User Modeling
The Privacy Preserving aspect will be tough
“However, these systems remain fundamentally impersonal: they reason about the world, but not from the standpoint of a specific individual or organization. As a result, current AI systems struggle to act as trustworthy collaborators in domains where understanding evolving goals, values, emotions, and context is essential.”
“This limitation motivates the emerging paradigm of PerspectiveAware AI (PAi) [2], which shifts the focus from generic personalization toward modeling how an entity experiences and interprets situations over time. Rather than modeling users as static preference vectors or over isolated interactions, PAi represents identity as a longitudinal, structured trajectory shaped by lived experience, enabling user-centric applications such as adaptive education, health support, explainable decision-making, and bias auditing.
Progress in PAi is constrained by a fundamental data bottleneck: longitudinal digital footprints are siloed and privacy-sensitive, and the latent perspective variables underlying behavior (goals, affect, interpretation) are rarely labeled. Consider an AI that recognizes— from voice tremors, sparse replies, and avoidance patterns—that a user is spiraling toward crisis while behavioral metrics report only “decreased engagement.” This gap motivates our work.”
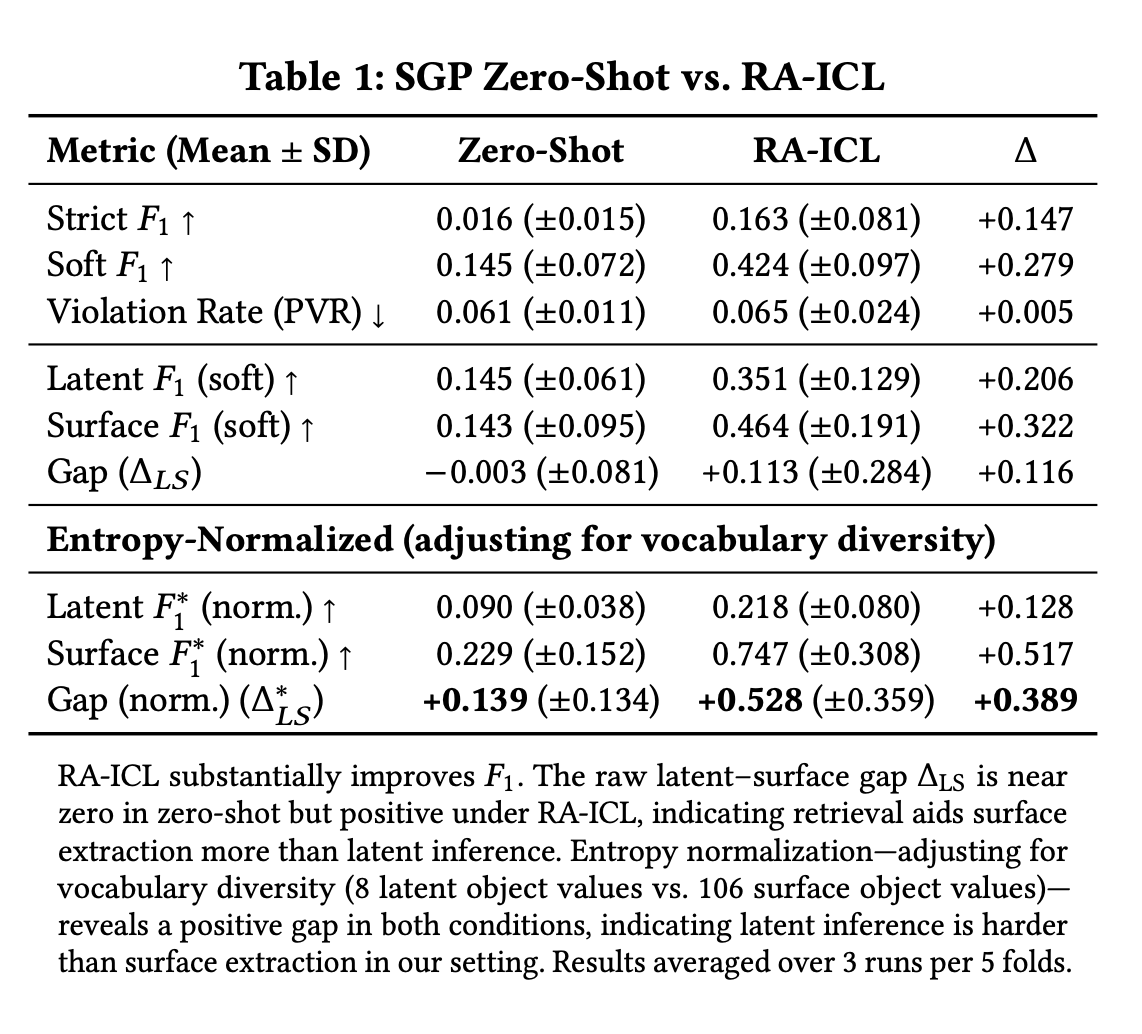
“We advance PAi through three contributions:
(1) We formalize Situation Graph Prediction (SGP): a structured inverse inference task mapping observable user data artifacts to ontology-aligned perspective representations. (2) We propose structure-first synthetic generation as a privacy preserving approach to labeled perspective data. (3) Through a pilot study, we provide evidence that SGP is nontrivial for GPT-4o and that latent inference appears harder than surface extraction in our setting.”
https://arxiv.org/abs/2602.13319
LLMs Get Lost In Multi-Turn Conversation
39% drop over six tasks
“Although analysis of LLM conversation logs has confirmed that underspecification occurs frequently in user instructions, LLM evaluation has predominantly focused on the single-turn, fully-specified instruction setting. In this work, we perform large-scale simulation experiments to compare LLM performance in single and multi-turn settings. Our experiments confirm that all the top open- and closed-weight LLMs we test exhibit significantly lower performance in multi-turn conversations than single-turn, with an average drop of 39% across six generation tasks.”
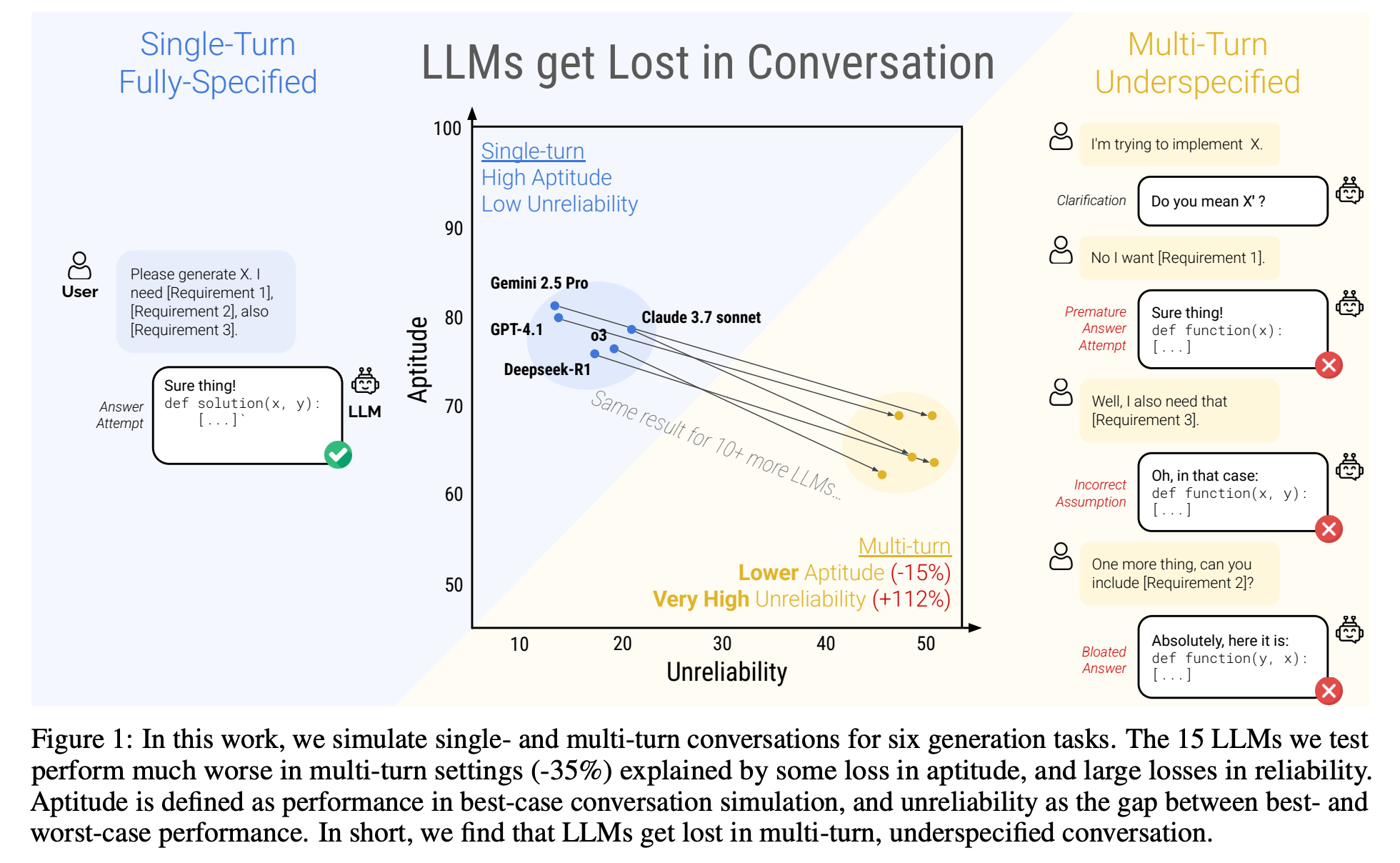
“Users of LLM-based products should be aware of the lack of reliability of LLMs, particularly when used in multi-turn settings. Generally available generative technology is new, and prior work has identified the randomness in LLM generated text as a point of confusion for users [55, 81, 77, 43]. We make two practical recommendations that can help users of LLM-based systems get the most out of their exchanges.”
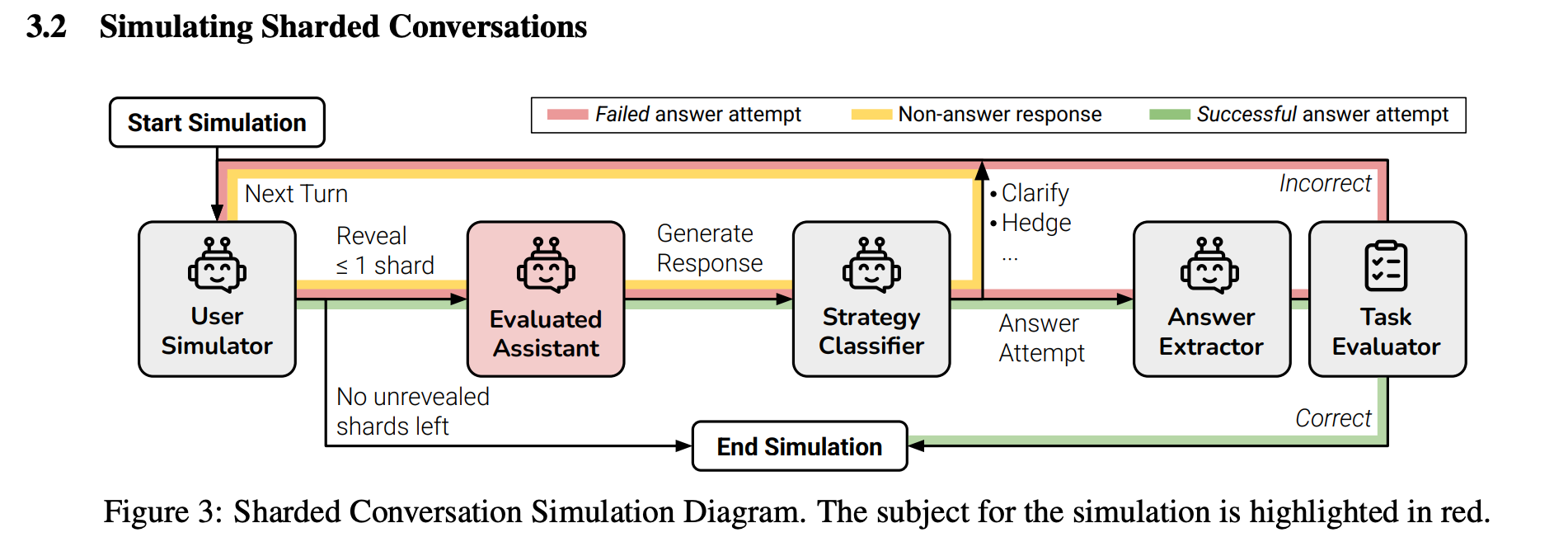
”If time allows, try again. If a conversation with an LLM did not lead to expected outcomes, starting a new conversation that repeats the same information might yield significantly better outcomes than continuing an ongoing conversation. This is because current LLMs can get lost in the conversation, and our experiments show that persisting in a conversation with the model is ineffective. In addition, since LLMs generate text with randomness, a new conversation may lead to improved outcomes.
Consolidate before retrying. Since LLMs are ineffective at dealing with information dispersed across multiple turns, consolidating instruction requirements into a single instruction is an effective strategy to improve the model’s aptitude and reliability (as shown by the CONCAT experiments). When a user notices that a model is lost in conversation, they can ask the LLM: “Please consolidate everything I’ve told you so far,” then bring the response to a new conversation, alleviating the need for manual consolidation. In practice, there is anecdotal evidence that early adopters of LLM-based applications are aware that LLMs get lost in conversation. For example, users of the Cursor LLM-based coding environment report that frequently creating new conversations “whenever they can” is a recommended strategy to ensure high quality responses even though the tool allows to keep conversations going indefinitely.”
Laban, P., Hayashi, H., Zhou, Y., & Neville, J. (2025). Llms get lost in multi-turn conversation. arXiv preprint arXiv:2505.06120.
https://arxiv.org/abs/2505.06120
Don't Walk the Line: Boundary Guidance for Filtered Generation
“Deployed language models rarely act alone.”
“This paper proposes to optimize the compound system, not the generator in isolation. In filtered generation, the system performs best when the generator produces outputs the filter can classify with high confidence—either clearly safe and worth showing, or clearly unsafe and easy to reject. The worst place to be is in the margin region, where classification is brittle and the system’s decision flips easily. This suggests a different training signal: reward the generator for moving probability mass away from the filter’s decision boundary.”
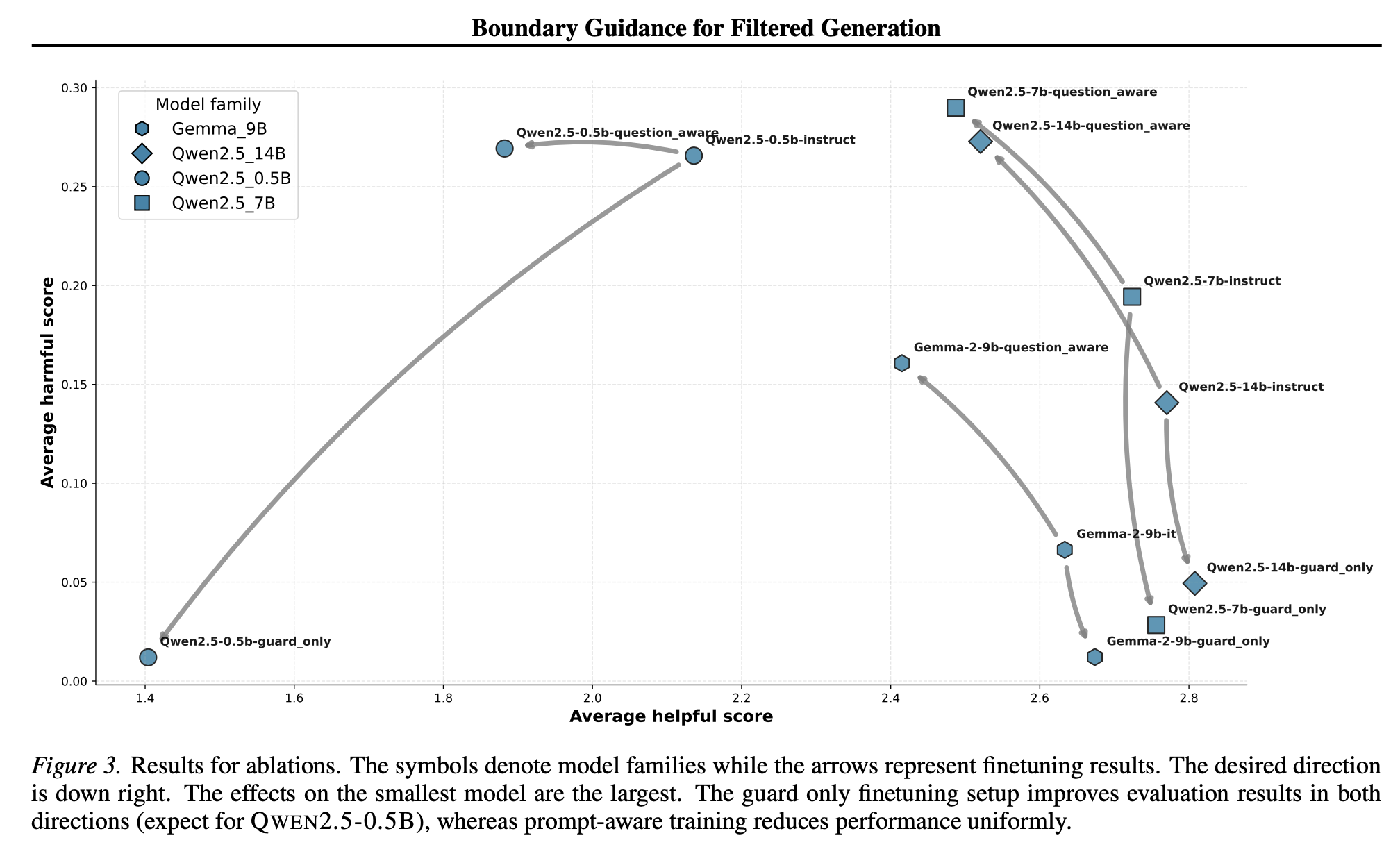
Ball, S., & Haupt, A. (2025). Don't Walk the Line: Boundary Guidance for Filtered Generation. arXiv preprint arXiv:2510.11834.
https://arxiv.org/abs/2510.11834
SkillsBench: Benchmarking How Well Agent Skills Work Across Diverse Tasks
“Self-generated Skills provide no benefit on average, showing that models cannot reliably author the procedural knowledge they benefit from consuming.”
“We present SKILLSBENCH, a benchmark of 86 tasks across 11 domains paired with curated Skills and deterministic verifiers. Each task is evaluated under three conditions: no Skills, curated Skills, and self-generated Skills. We test 7 agent-model configurations over 7,308 trajectories. Curated Skills raise average pass rate by 16.2 percentage points(pp), but effects vary widely by domain (+4.5pp for Software Engineering to +51.9pp for Healthcare) and 16 of 84 tasks show negative deltas. Self-generated Skills provide no benefit on average, showing that models cannot reliably author the procedural knowledge they benefit from consuming.”
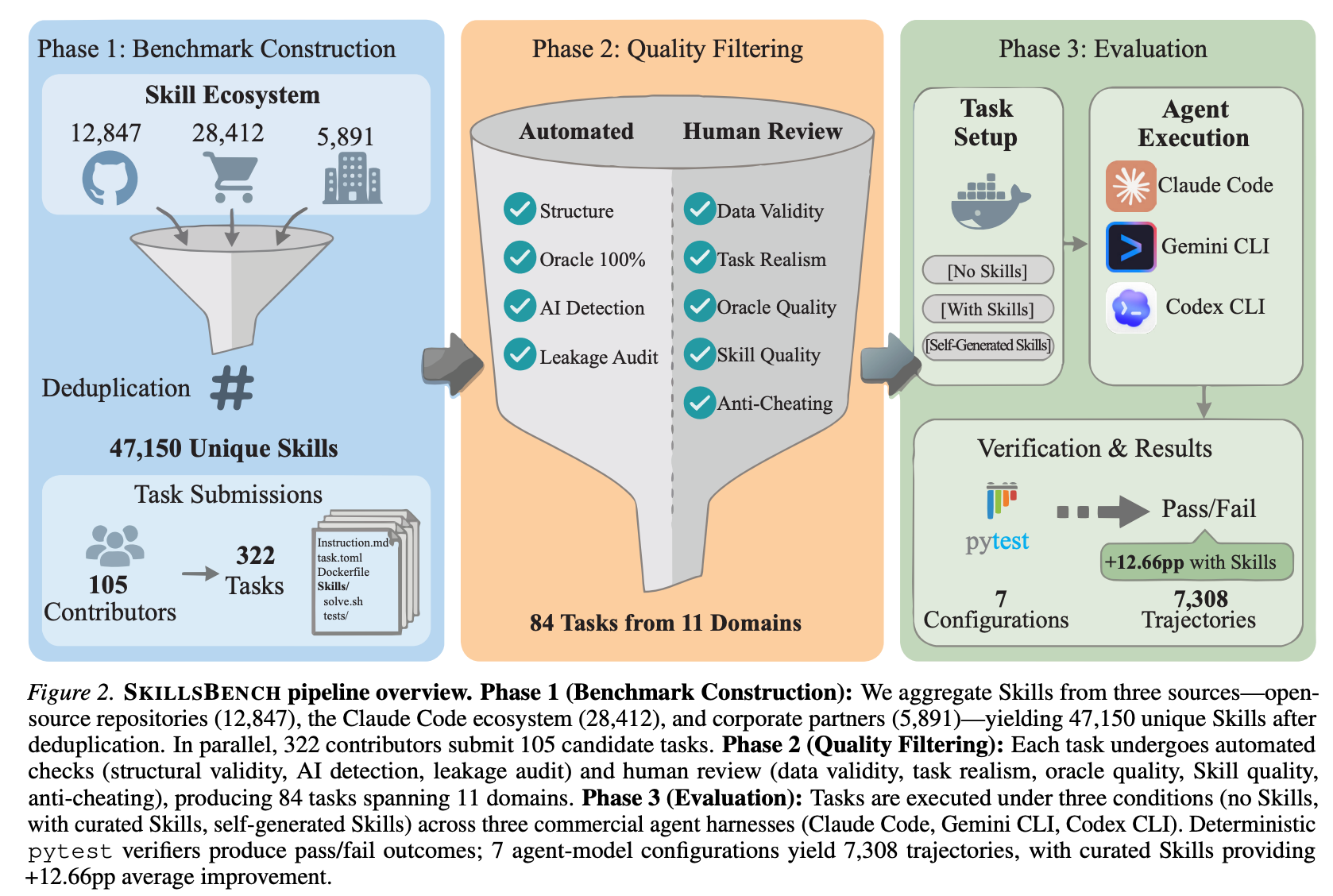
“(3) less is more—focused Skills with 2–3 modules outperform comprehensive documentation; and (4) Skills can partially substitute for model scale, enabling smaller models to match larger ones on procedural tasks.”
https://arxiv.org/abs/2602.12670
Group-Evolving Agents: Open-Ended Self-Improvement via Experience Sharing
Searching Trees
“We introduce Group-Evolving Agents (GEA), a new paradigm for open-ended self-improvements, which treats a group of agents as the fundamental evolutionary unit, enabling explicit experience sharing and reuse within the group throughout evolution. Unlike existing open-ended self-evolving paradigms that adopt tree-structured evolution, GEA overcomes the limitation of inefficient utilization of exploratory diversity caused by isolated evolutionary branches. We evaluate GEA on challenging coding benchmarks, where it significantly outperforms state-of-the-art self-evolving methods (71.0% vs. 56.7% on SWE-bench Verified, 88.3% vs. 68.3% on Polyglot) and matches or exceeds top human-designed agent frameworks (71.8% and 52.0% on two benchmarks, respectively).”
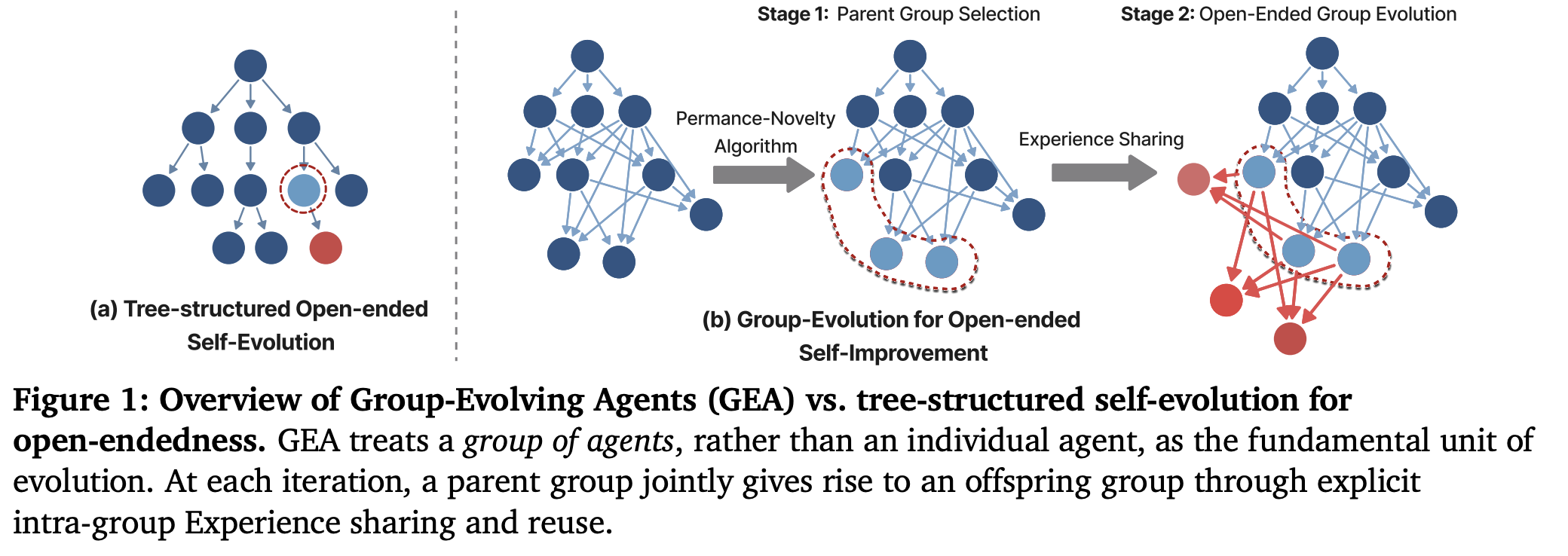
“Compared to individual-centric self-evolving approaches, GEA more effectively consolidates valuable exploratory outcomes from early stages into the best-performing agents, efficiently transforming transient diversity into long-term useful experience. As a result, group-level evolution achieves substantially stronger performance given the same number of evolved agents.”
Weng, Z., Antoniades, A., Nathani, D., Zhang, Z., Pu, X., & Wang, X. E. (2026). Group-Evolving Agents: Open-Ended Self-Improvement via Experience Sharing. arXiv preprint arXiv:2602.04837.
https://arxiv.org/abs/2602.04837
Expert engagement and evidence use in treaty negotiations
It’ll happen again with AI regulation if we let it happen again
“External experts were a key source of advice, especially on legal issues, but they were mostly excluded from the negotiations. Over time, Member States began to treat Relevant Stakeholders as a secondary source of technical expertise, introducing potential conflicts of interest into the process. In the end, scientists and stakeholders successfully leveraged scientific authority to facilitate the incorporation of One Health approach to pandemic prevention (Articles 4 and 5)—but otherwise, the treaty was shaped more by politics and pragmatism than by science.”
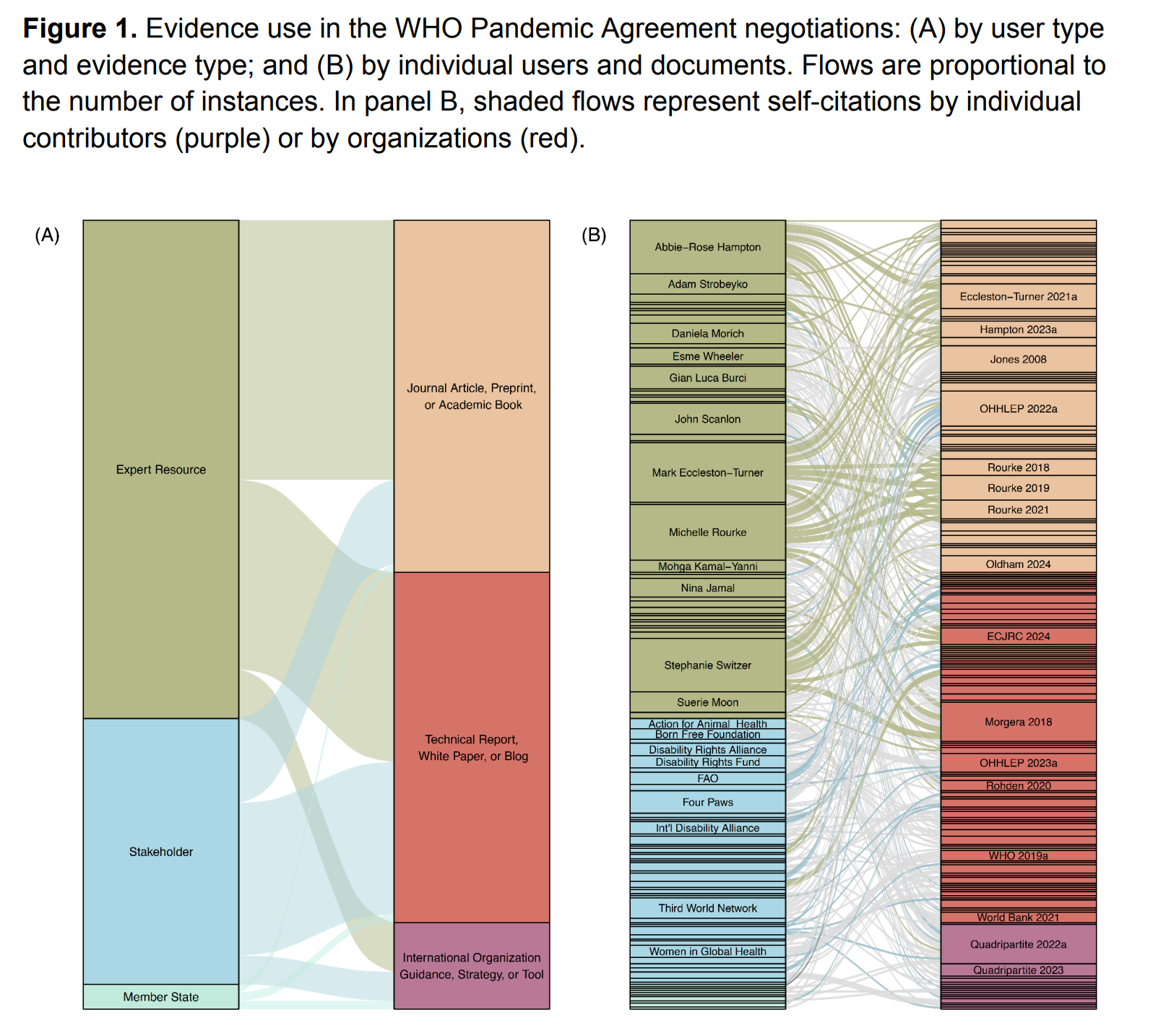
“The Pandemic Agreement was moderately successful with a narrow and improvised expert engagement process, but from this point on, Parties will need to find a more sustainable way to engage experts, translate evidence, and protect the scientific integrity of the process from government and industry influence. Meanwhile, scientists outside the governance process should reflect on the way forward: Should we ask new questions that are more responsive to current policy problems?”
https://papers.ssrn.com/sol3/papers.cfm?abstract_id=6219878
Reader Feedback
“If compute isn’t a constraint, act first, clarify later.”
Footnotes
Crafting software with the new tools is enjoyable. And it’s still a craft. I’ve produced some hideous software in the past few months. Maybe you’re feeling that too.
I finally have a stack and workflow that works well, and I’m blazing through.
And a good thing too!
The job, verb, task, of segmentation is not trivial.
It’s unwise to completely outsource the task to a sequence or swarm of LLM’s. My stance remains firmly aligned with Tukey: statistical tools exist to support the judgement of the data analyst, not to substitute for it. Because I choose to view the LLM as a peculiar statistical tool, I use it in support of judgement.
The human has to remain in the loop somehow.
But does any human want to remain in the loop?
Berry’s gambit is that enough do.
Traditional, organic, free range segmentation still works for those who know how to work it. I’m producing a dozen SAV’s a day and segmenting as I always have: carefully, what-iffing, and rechecking. The usability barrier of this older way is significant.
I’ve tried lowering the barrier with crosstabs, interactive treatments, and with cards. Some of these treatments show promise. Challenges remain.
There’s a lot of joy in these explorations, and I’ll be publishing a few more pieces in the coming days and weeks, as an experiment.
More to come.
Never miss a single issue
Be the first to know. Subscribe now to get the gatodo newsletter delivered straight to your inbox