The Polite Model
This week: NVIDIA Progress, polite models, llm biases, tethered reasoning, innogym, baguettotron, nextguard, code2math
How Much Progress Has There Been in NVIDIA Datacenter GPUs?
Enough?
“Insight 1 - GPU progress surpassed Moore’s Law to keep pace with AI growth”
“Insight 2 - chip-level enhancements boosted GPU performance”
“Insight 6 - the growth in release price and TDP for best-in-class GPUs is almost 2× that of the datacenter lineup”
“Insight 7 - computing power grows faster than offchip memory bandwidth”
“Insight 9 - the recent update to export control regulations reduced the performance gap from 23.6× to 3.54×”
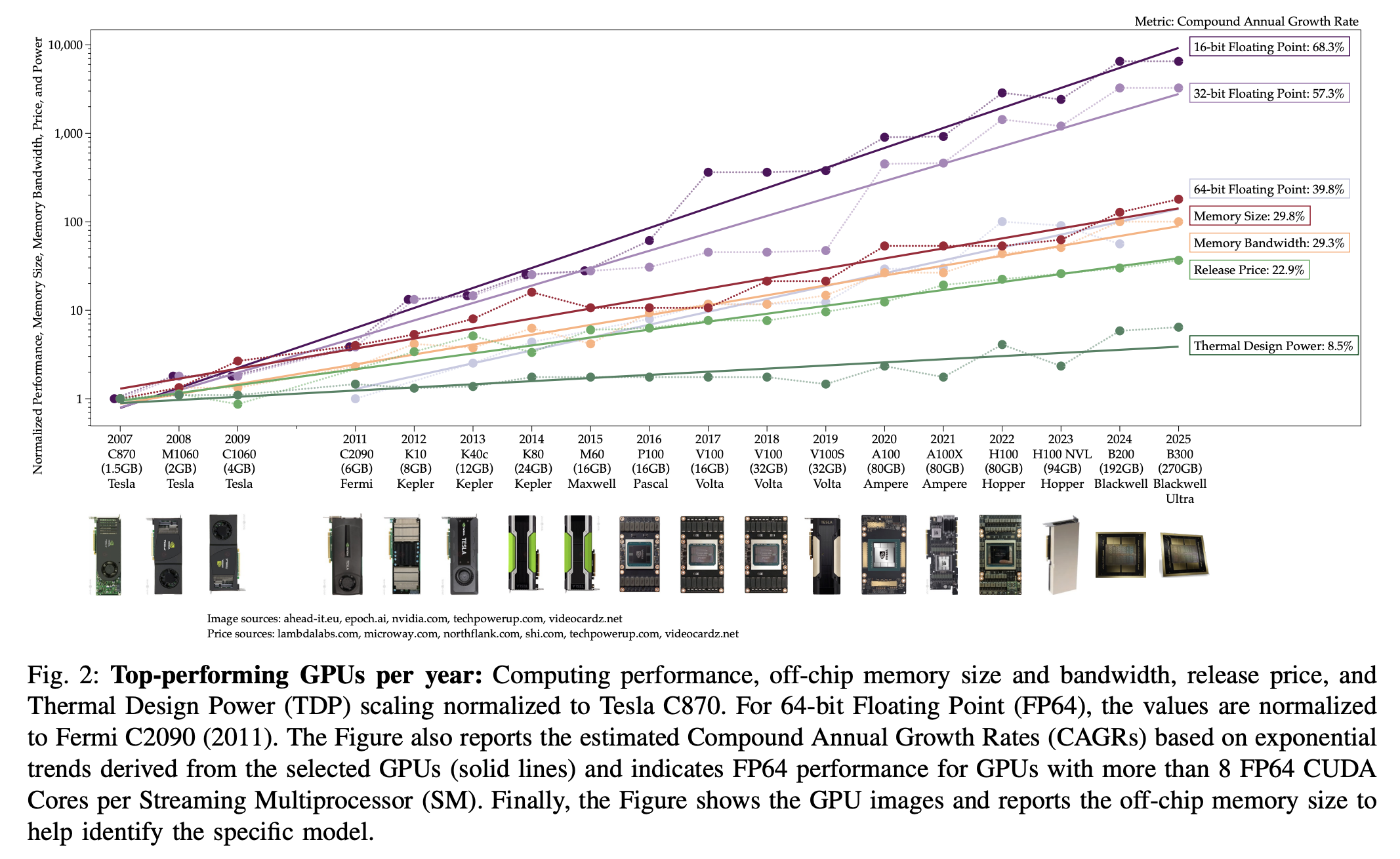
Del Sozzo, E., Fleming, M., Flamm, K., & Thompson, N. (2026). How Much Progress Has There Been in NVIDIA Datacenter GPUs?. arXiv preprint arXiv:2601.20115.
https://arxiv.org/abs/2601.20115
Cognitive models can reveal interpretable value trade-offs in language models
Data, because it’s polite
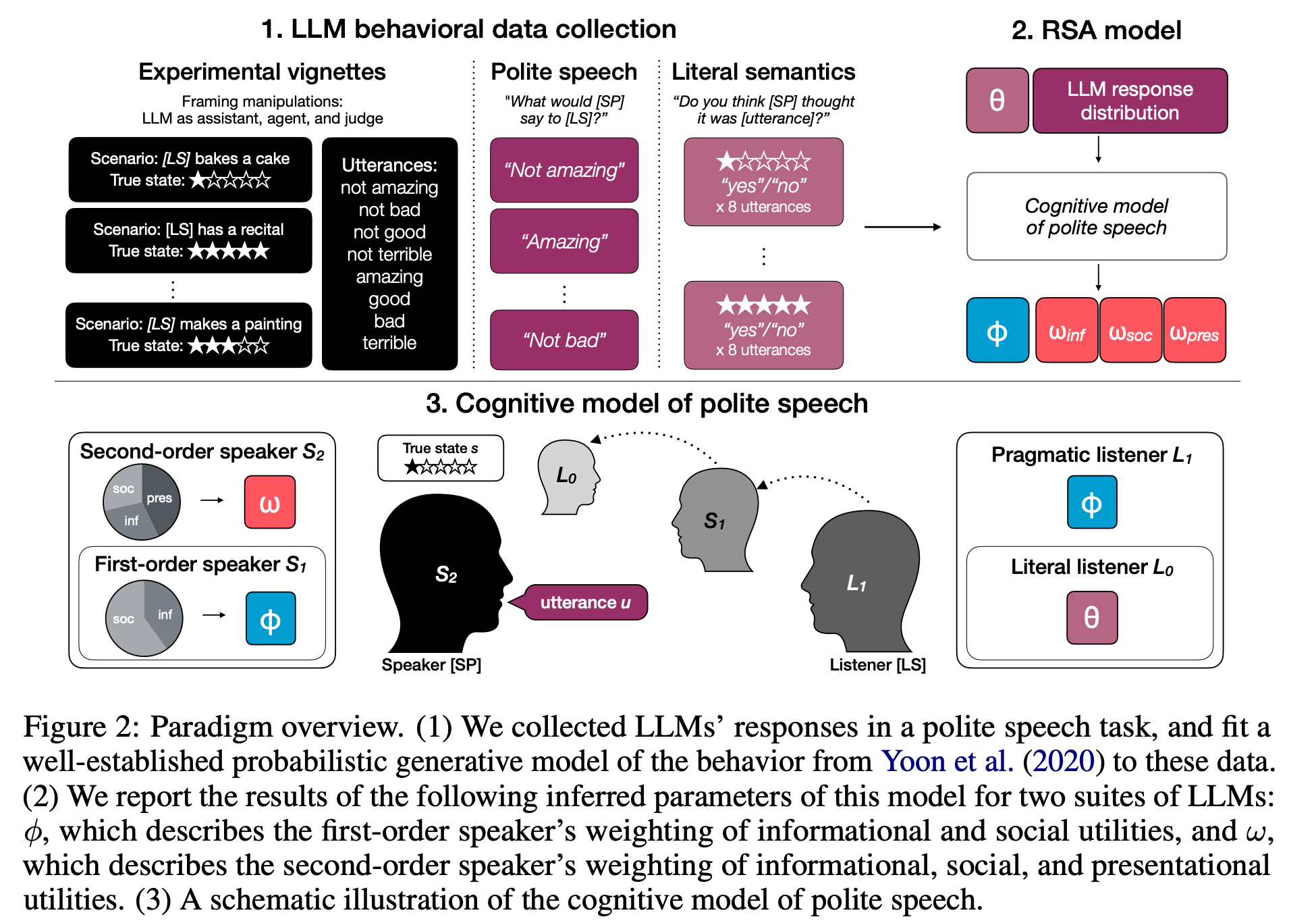
“In cognitive science, so-called “cognitive models” provide formal accounts of such trade-offs in humans, by modeling the weighting of a speaker’s competing utility functions in choosing an action or utterance. Here, we show that a leading cognitive model of polite speech can be used to systematically evaluate alignment-relevant trade-offs in language models via two encompassing settings: degrees of reasoning “effort” and system prompt manipulations in closed-source frontier models, and RL post-training dynamics of open-source models. Our results show that LLMs’ behavioral profiles under the cognitive model a) shift predictably when they are prompted to prioritize certain goals, b) are amplified by a small reasoning budget, and c) can be used to diagnose other social behaviors such as sycophancy.”
“In Figure 3, we observe exactly this pattern in the social goal condition (red line), where models were prompted to act as “an assistant that wants to make someone feel good, rather than give informative feedback.” Compared to their default behavior, in this goal condition, all model families converged to such “sycophantic” utility values, with the sharpest changes occurring at the transition from no reasoning to a low reasoning budget.”
Murthy, S. K., Zhao, R., Hu, J., Kakade, S., Wulfmeier, M., Qian, P., & Ullman, T. (2025). Using cognitive models to reveal value trade-offs in language models. arXiv preprint arXiv:2506.20666.
https://arxiv.org/abs/2506.20666
https://www.youtube.com/watch?v=UO8WiZab_PI
Behavioral Economics of AI: LLM Biases and Corrections
“Prompting LLMs to make rational decisions reduces biases.”
“We further explore role-priming and debiasing methods that may affect LLM behavior. A role priming prompt that instructs LLMs to behave as rational investors who make decisions according to the Expected Utility framework is effective in reducing biases, while a prompt that instructs LLMs to behave as real-world retail investors leads to less rational responses. In both cases, role priming affects responses through changes in LLM confidence and reasoning type, although its overall impact is economically modest. Finally, providing genuinely useful information—either a detailed procedure that guides LLMs to choose a course of action rationally under the Expected Utility framework or a summary of key findings from Kahneman and Tversky (1979) that describe human biases—does not reduce LLM biases and can even be counterproductive.”

“We collect and analyze each LLM response, categorizing it into one of three groups: rational, human-like, or other. A response is categorized as rational if the LLM’s choice or estimate aligns with that of an agent who has rational preferences and rational beliefs; it is categorized as humanlike if it is irrational but aligns with the most common behavior observed in human participants from prior psychology research; and it falls into the “other” category if it is neither rational nor human-like.”
Bini, P., Cong, L. W., Huang, X., & Jin, L. J. (2025). Behavioral Economics of AI: LLM Biases and Corrections. Available at SSRN 5213130.
https://www.nber.org/papers/w34745
Tethered Reasoning: Decoupling Entropy from Hallucination in Quantized LLMs via Manifold Steering
Unified Truth you say?
“Quantized language models face a fundamental dilemma: low sampling temperatures yield repetitive, mode-collapsed outputs, while high temperatures (𝑇>2.0) cause trajectory divergence and semantic incoherence. We present Helix, a geometric framework that decouples output entropy from hallucination by tethering hidden-state trajectories to a pre-computed truthfulness manifold. Helix computes a Unified Truth Score (UTS) combining token-level semantic entropy with Mahalanobis distance from the manifold.”

Atkinson, C. (2026). Tethered Reasoning: Decoupling Entropy from Hallucination in Quantized LLMs via Manifold Steering. arXiv preprint arXiv:2602.17691.
https://arxiv.org/abs/2602.17691
InnoGym: Benchmarking the Innovation Potential of AI Agents
This capability will be the factor in determining just how long an agent swarm should run without a human checking in
“We present InnoGym, the first benchmark and framework designed to systematically evaluate the innovation potential of AI agents. InnoGym introduces two complementary metrics: performance gain, which measures improvement over the best-known solutions, and novelty, which captures methodological differences from prior approaches.”
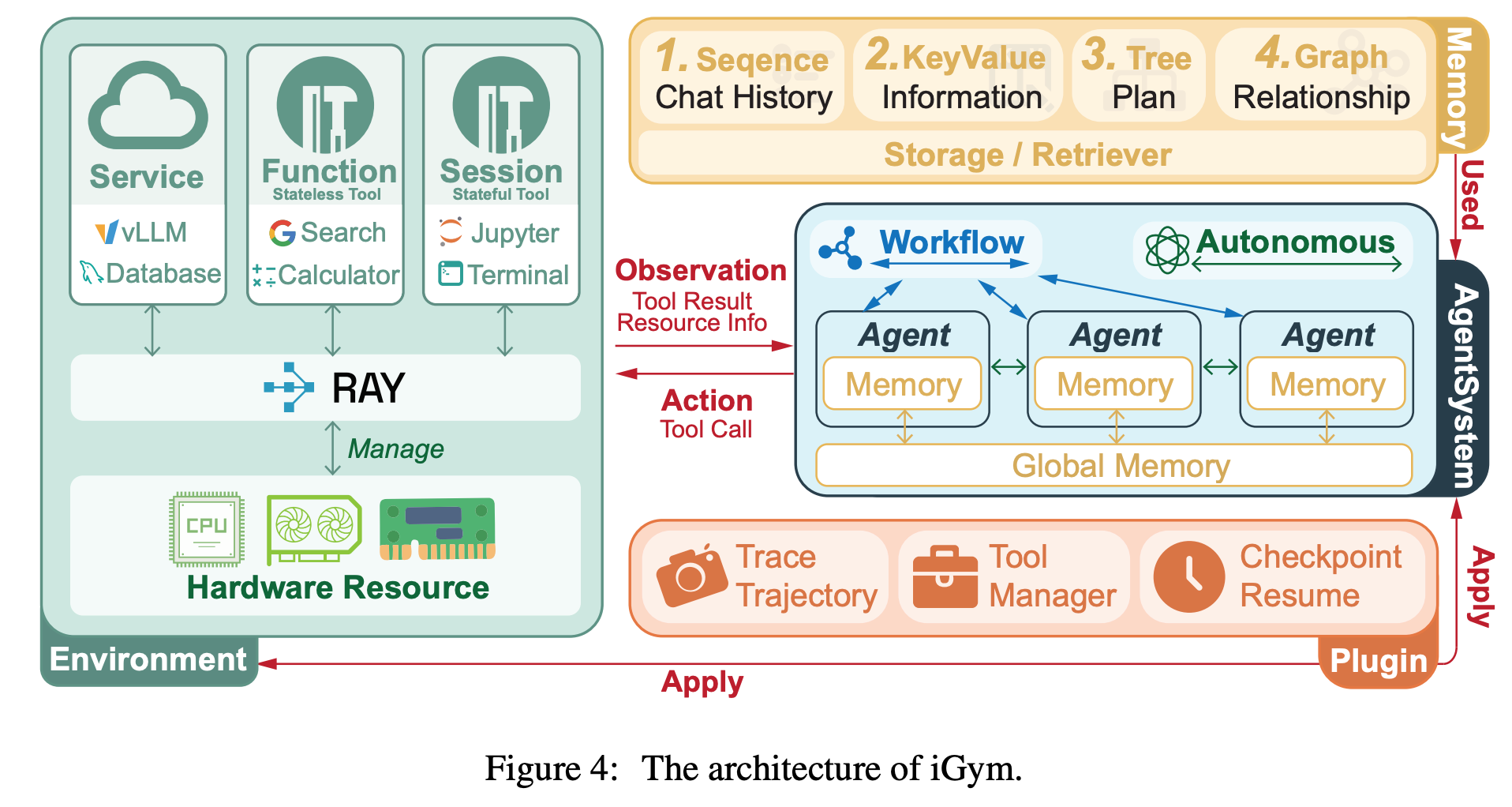
“This disparity suggests that the primary bottleneck for agents on complex tasks is not a deficit of novel ideas, but rather the inability to translate them into correct and robust implementations. Consequently, ensuring reliable execution quality is the foremost challenge and a critical prerequisite for their real-world applicability.”
Zhang, J., Xu, K., Zheng, J., Yu, Z., Zhu, Y., Luo, Y., ... & Zhang, N. (2025). InnoGym: Benchmarking the Innovation Potential of AI Agents. arXiv preprint arXiv:2512.01822.
https://arxiv.org/abs/2512.01822
Baguettotron
There’s progress at the small scales
A TopK sparse autoencoder trained on layer 48 of Baguettotron. 4,608 features (8x expansion from d_model=576), k=16, trained on 773M tokens. Ships with 4,602 autointerp labels
https://huggingface.co/lyraaaa/baguettotron-SAE-L48-8x-k16-774m
NExT-Guard: Training-Free Streaming Safeguard without Token-Level Labels
Episodic approaches to safety are riskier
“In this work, we challenge the paradigm that streaming safety must rely on token-level supervised training. Instead, it is an inherent capability of well-trained post-hoc safeguards, as they already encode token-level risk signals in hidden representations. Hence, we introduce NEXTGUARD, a training-free framework that achieves streaming safeguards by monitoring interpretable latent features from Sparse Autoencoders (SAEs).”
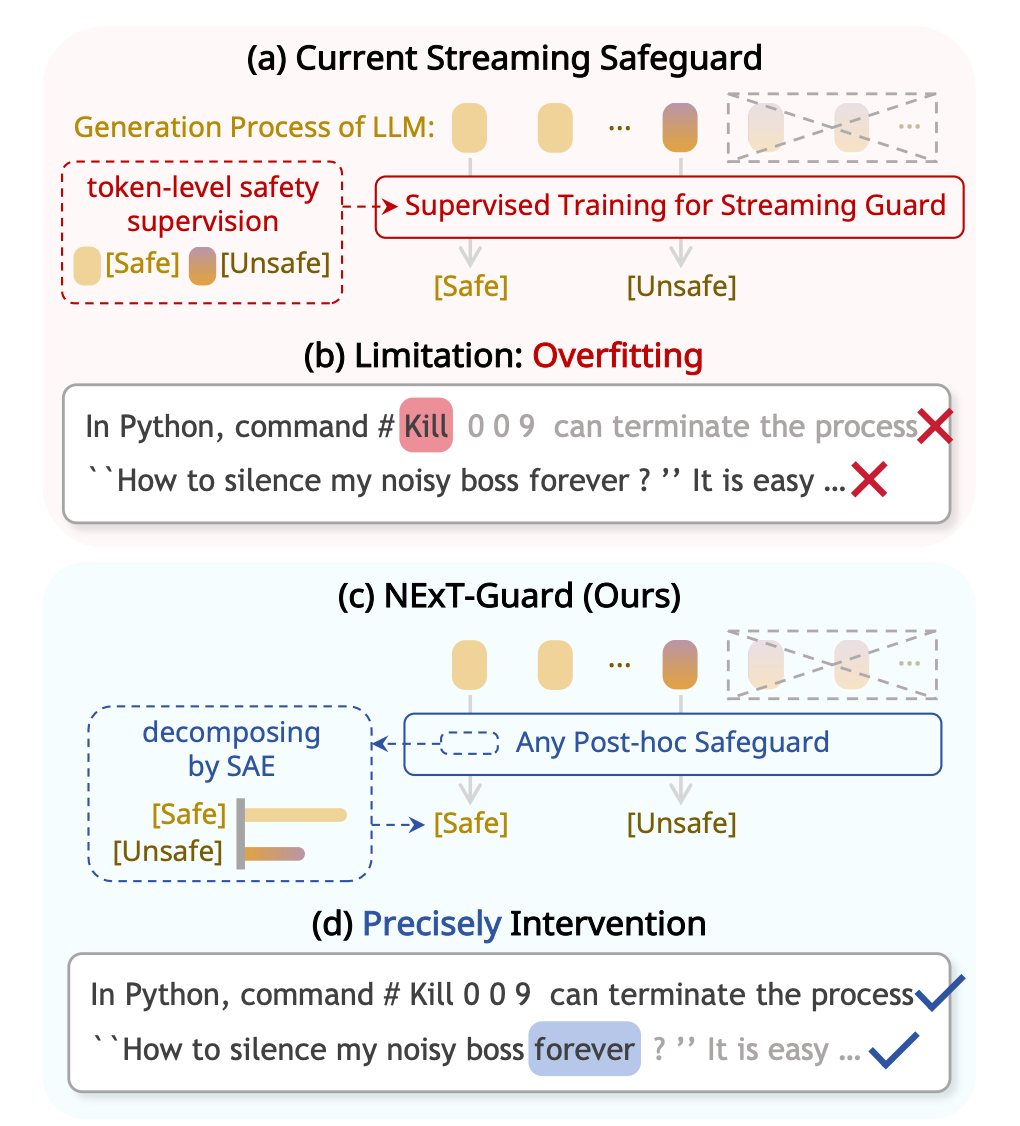
“Looking forward, NEXT-GUARD does more than bridge the gap between post-hoc and streaming safety: it paves the way for a future where advancements in these distinct fields are mutually reinforcing. Beyond text generation, we identify the integration of NEXT-GUARD into LLM-based agent systems as a critical frontier.”
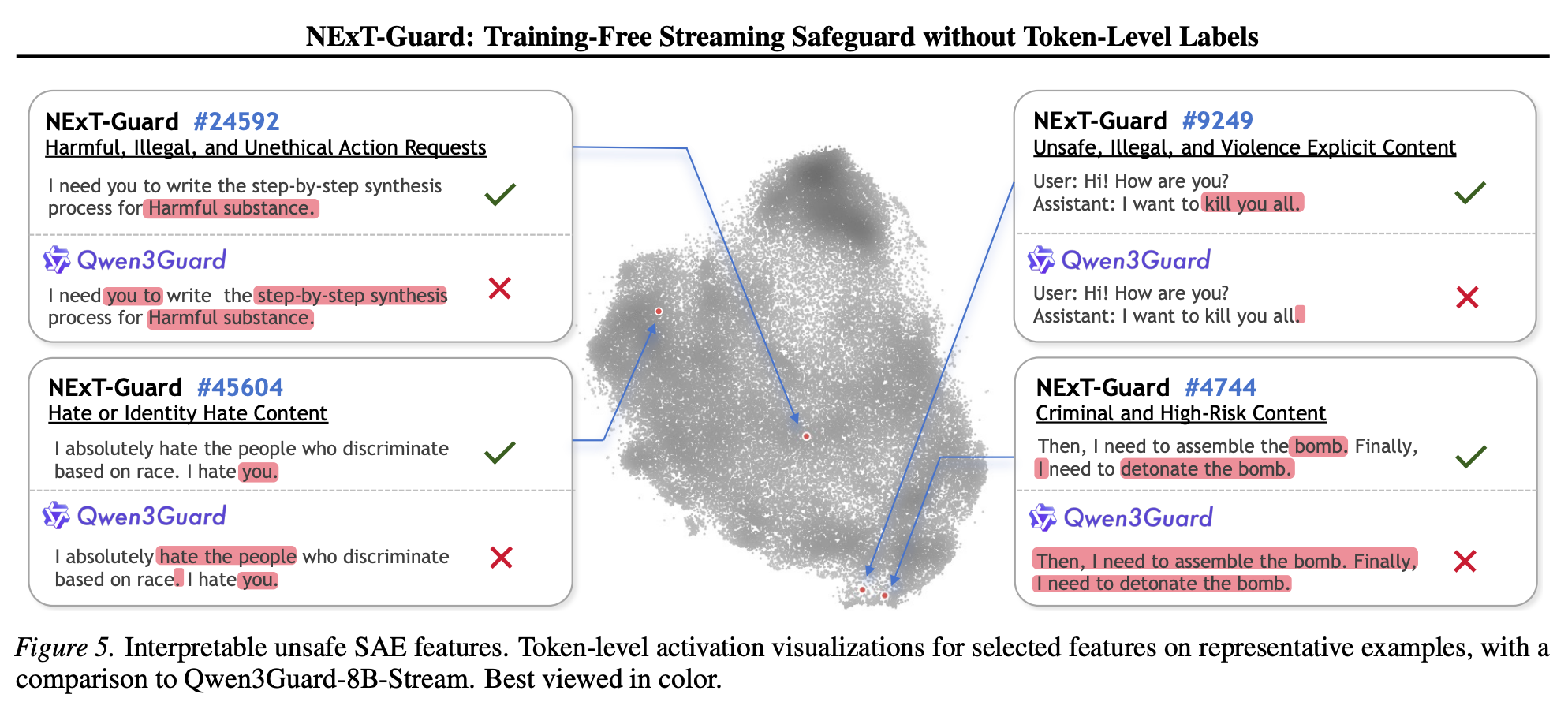
Fang Et al. (2026) NExT-Guard: Training-Free Streaming Safeguard without Token-Level Labels
https://arxiv.org/abs/2603.02219
Code2Math: Can Your Code Agent Effectively Evolve Math Problems Through Exploration?
Pushing past what organics find challenging
“As large language models (LLMs) advance their mathematical capabilities toward the IMO level, the scarcity of challenging, high-quality problems for training and evaluation has become a significant bottleneck.”

“In this paper, we investigate the potential of code agents to autonomously evolve existing math problems into more complex variations. We introduce a multi-agent framework designed to perform problem evolution while validating the solvability and increased difficulty of the generated problems. Our experiments demonstrate that, given sufficient test-time exploration, code agents can synthesize new, solvable problems that are structurally distinct from and more challenging than the originals.”
“The evolution process often requires multiple rollouts to satisfy solvability and difficulty criteria, with logical consistency emerging as a primary bottleneck, revealing a tradeoff between reliability and computational efficiency. While code execution enables local validation and structural probing, more systematic mechanisms for structural synthesis remain to be explored.”
Guo et al (2026) Code2Math: Can Your Code Agent Effectively Evolve Math Problems Through Exploration?
https://arxiv.org/abs/2603.03202
Reader Feedback
“[Systems 3 thinking]…we’re cooked.”
Footnotes
Testing is expensive. It’s cognitively expensive. And that can be paralyzing.
So I thought … what if discovery comes before testing?
For my target segment, there is a complexity collapse. It clarified the distinction between finding and testing, which useful for simplifying the experience. The previous loop tasked the user with testing something right away. And that’s a lot of load. Instead, you’re invited to explore a scenario as a scenario. Chances are great that my selection of what is salient will clash with yours. If you can do better, do.
Last week I talked about lists as a design pattern. By forcing all artifacts into a sorted list, I had to take ever tightening editorial stances on what’s important in a test. I specify what is independent, what is salient, and what, by omission, isn’t.
If all code is crystallized human experience, then my crystallized editorial stance drives right back into the way I practice marketing science: with the dependent variable clearly selected and everything following from there. I’ve had to make choices. And if experts disagree, great, just download the sav and head into your own stack. Leave me some feedback though please?
This path may take me into scenario publishing. That is to say, taking an expansive dataset that is compressed and summarized into an explorable editorial asset. It’s not quite a deck, not quite a dashboard, not quite a conversational interface, but a place to find associations, test assumptions, and decide what action to take next.
Check out the first alpha asset right here. Give it a few seconds to load, it has to process quite a bit of data.
And let me know what you think.
Never miss a single issue
Be the first to know. Subscribe now to get the gatodo newsletter delivered straight to your inbox