The shadow of the statistician hovers in the background
This week: Why language models hallucinate, RL, REER, confusing code, the actuaries final word
Why Language Models Hallucinate
It’s the incentives!
“We argue that language models hallucinate because the training and evaluation procedures reward guessing over acknowledging uncertainty, and we analyze the statistical causes of hallucinations in the modern training pipeline.”

“If incorrect statements cannot be distinguished from facts, then hallucinations in pretrained language models will arise through natural statistical pressures.”
“Binary evaluations of language models impose a false right-wrong dichotomy, award no credit to answers that express uncertainty, omit dubious details, or request clarification. Such metrics, including accuracy and pass rate, remain the field’s prevailing norm, as argued below.”
“A hallucination is a plausible falsehood, and by considering only plausible strings X, our analysis ignores the possibility of generating nonsensical strings (which state-of-the-art language models rarely generate).”
“In contrast, we argue that the majority of mainstream evaluations reward hallucinatory behavior. Simple modifications of mainstream evaluations can realign incentives, rewarding appropriate expressions of uncertainty rather than penalizing them. This can remove barriers to the suppression of hallucinations, and open the door to future work on nuanced language models, e.g., with richer pragmatic competence (Ma et al., 2025).”
Kalai, A. T., Nachum, O., Vempala, S. S., & Zhang, E. (2025). Why Language Models Hallucinate.
https://arxiv.org/pdf/2402.17847
From f(x) and g(x) to f(g(x)): LLMs Learn New Skills in RL by Composing Old Ones
Reinforcement learning builds from atomic skills
“RL unlocks new capabilities by composing existing ones.”
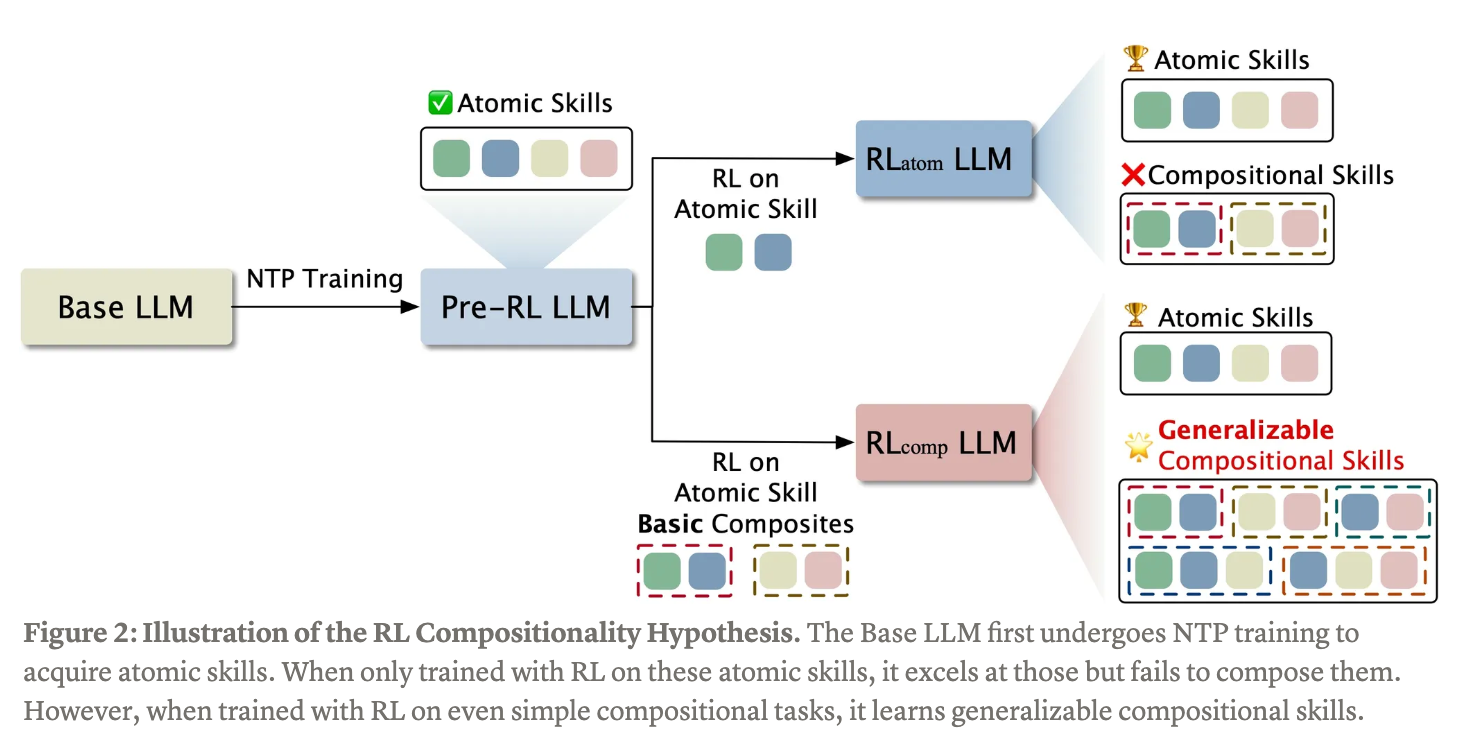
“Practical Guideline: The success of compositional RL fundamentally relies on the breadth of the model’s atomic skills. Therefore, prioritize maximizing the model’s knowledge of atomic skills through extensive next-token prediction training first. With that foundation in place, targeted RL on a curated set of tasks can then effectively teach the crucial meta-skill of combining what the model already knows.”
“RL can unlock new, generalizable skills.
RL can at least teach a model compositional reasoning, solving problems with a compositional complexity far beyond what the model was trained on.
The prerequisite of learning new skills is incentivizing composition in the training.
Training on the atomic components alone can only improve model performance on atomic skills and is insufficient to solve more difficult compositional problems. The model needs "seed" compositional data (like a Level 2 problem) to unlock the generalizable composition ability.
Atomic skills are necessary, but RL data collection does not need all of them.
During RL, the model indeed learned a generalizable ability that is able to compose atomic functions whose combinations it has never seen. This suggests that, in practice, incentivization does not require an exhaustive RL dataset covering all atomic skills from the pre-training or SFT corpus, at least for the same task.”
“RL fundamentally changes how models approach compositional problems
While RL may appear to simply improve accuracy on compositional tasks, behavioral analysis reveals it actually transforms the model's failure modes towards a promising direction. Instead of a brittle and incomplete grasp of composition, RL with corresponding incentivization teaches models with recognizing, understanding, and tackling compositional problems, rather than just improving performance at a shallow level.”
Reverse-Engineered Reasoning for Open-Ended Generation
It’s working backwards
“The two dominant methods for instilling reasoning—reinforcement learning (RL) and instruction distillation – falter in this area; RL struggles with the absence of clear reward signals and highquality reward models, while distillation is prohibitively expensive and capped by the teacher model’s capabilities. To overcome these limitations, we introduce REverse-Engineered Reasoning (REER), a new paradigm that fundamentally shifts the approach. Instead of building a reasoning process "forwards" through trial-and-error or imitation, REER works "backwards" from known good solutions to computationally discover the latent, step-by-step deep reasoning process that could have produced them.”
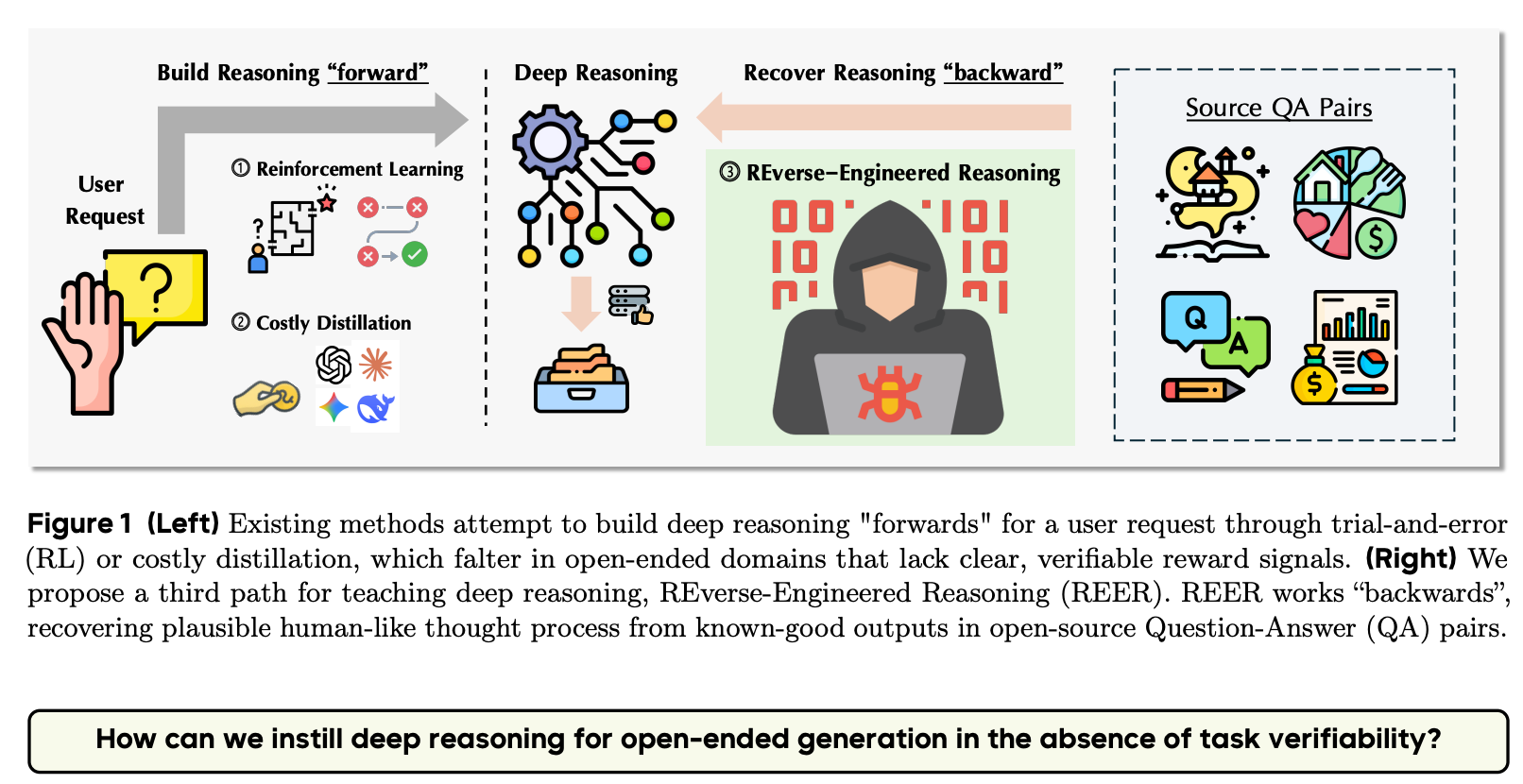
“We pioneer a novel approach that operationalizes the REER paradigm and, for the first time, instill deep reasoning capabilities for open-ended generation entirely from scratch. Our approach involves three key stages. First, we source a diverse dataset of query-solution pairs for open-ended generation from the web, encompassing 16,000 samples spanning across ordinary-life question-answering, academic writing, functional writing and creative writing. From these, we “reverse-engineer" deep reasoning trajectories – structured, human-like thought process tailored for open-ended generation. Eventually, we use this synthetic data to fine-tune a base language model, teaching it to reason and plan deeply before generating a final solution.
The central innovation lies in how we synthesize this data: we formulate the recovery of high quality thinking trajectories as a gradient-free search problem. These trajectories are found by iteratively refining an initial plan, with the search guided by a proxy for thought quality – the perplexity of a known good solution. The gradient-free, self-contained nature of our synthesis process lends us the scalability. By obviating the need for expensive, query-by-query distillation from proprietary models or the sample-inefficiency of reinforcement learning, our approach provides a cost-effective and automatable pathway to generate vast quantities of high-quality, deep-thinking training data. This makes it possible to instill sophisticated reasoning in models at a scale that was previously impractical.”
https://arxiv.org/abs/2509.06160
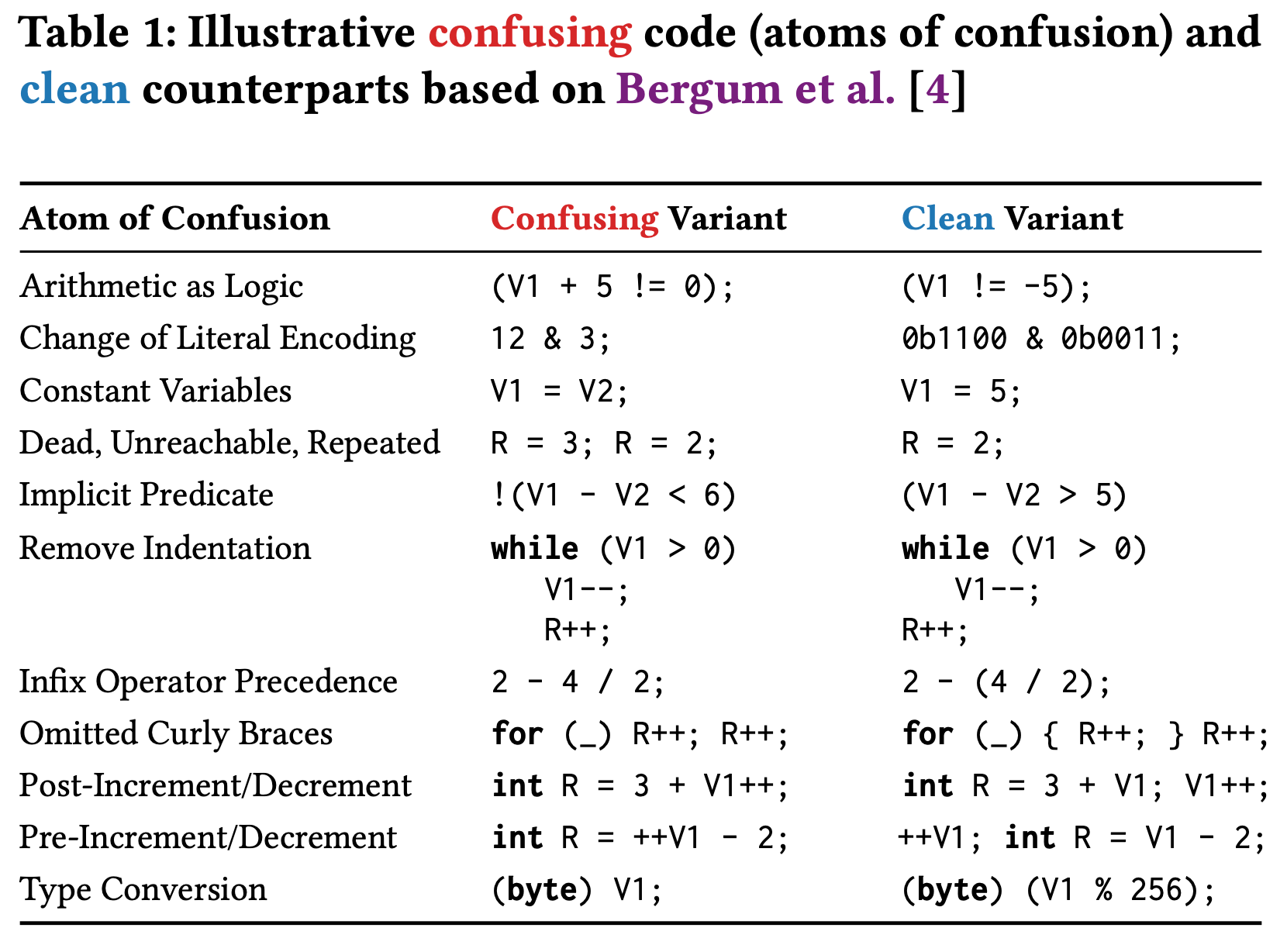
How do Humans and LLMs Process Confusing Code?
LLM’s are just like us!
“…we conducted an empirical study comparing an LLM to human programmers comprehending clean and confusing code. We operationalized comprehension for the LLM by using LLM perplexity, and for human programmers using neurophysiological responses (in particular, EEG-based fixation-related potentials). We found that LLM perplexity spikes correlate both in terms of location and amplitude with human neurophysiological responses that indicate confusion. This result suggests that LLMs and humans are similarly confused about the code.”
“Our study revealed an alignment between LLM perplexity and human neurophysiological responses, which represents an important step toward establishing LLMs as surrogate models of human program comprehension. This opens new avenues for exploring the underlying cognitive processes of human program comprehension and supports the development of LLMs to be more closely aligned with human comprehension patterns, such as other sources of confusion.”
Abdelsalam, Y., Peitek, N., Maurer, A. M., Toneva, M., & Apel, S. (2025). How do Humans and LLMs Process Confusing Code?. arXiv preprint arXiv:2508.18547.
https://arxiv.org/abs/2508.18547
The Actuary's Final Word on Algorithmic Decision Making
“Why should we care whether you think this one is different or whether you are surer?”

“Meehl’s prediction problems require a small set of possible outcomes and machine-readable data. Second, individual predictions and decisions are evaluated only on average. This formulation leads to a natural analysis from statistical decision theory, which shows that statistical rules are more accurate than clinical intuition almost by definition. Meehl’s prediction paradox is an example of metrical determinism, where the rules of evaluation implicitly determine the best procedure. The decision-theoretic analysis of Meehl’s problem elucidates the utility of algorithmic systems as decision-support tools, but also reveals their natural shortcomings, inducing expertise erosion, decision fatigue, and the usurpation of discretionary judgment.”
“Then, we could use optimal statistical decision rules to weigh the costs and benefits and select an action we believed would be most effective. This is statistical prediction. We convert past performance into future confidence. As discussed in detail by Dawid [2017], the translation of past frequencies into future, individualized risk is so common that we seldom notice when this rhetorical turn is made in our faces.”
“But if a doctor is operating on a patient with an extremely uncommon condition, is that statistics too? In a sense, we can only define the term ’uncommon’ in statistical terms. It refers to a relative frequency of occurrence. However, in these cases where experiences do seem wholly new, how can we map past rates onto how to act? There is clearly a spectrum between when pure statistics can guide action (e.g., betting on blackjack) and where perhaps there is something else that must be applied (e.g., surgery on a novel condition).”
““If a clinician says, ‘This one is different’ or ‘It’s not like the ones in your table,’ ‘This time I’m surer,’ the obvious question is, ‘Why should we care whether you think this one is different or whether you are surer?’ Again, there is only one rational reply to such a question. We have now to study the success frequency of the clinician’s guesses when he asserts that he feels this way. If we have already done so and found him still behind the hit frequency of the table, we would be well advised to ignore him. Always, we might as well face it, the shadow of the statistician hovers in the background; always the actuary will have the final word.”
“Most worrisomely, the predictions trained on statistical counts have limited temporal validity, as the population of people changes faster than the statistical prediction rules can be updated. Statistical prediction relies on past counts being reasonable predictions of the future. We have plenty of experience that tells us this is often not a safe assumption.”
“Nonetheless, one of the primary impulses of the modern state is to translate human experience into data readable by machines. Bureaucracies render humanity in a simplified state in order to make decisions about it.”
“Those of us who aren’t bureaucrats should be careful about which discretion we remove from decisions that affect people’s lives. We should tell the actuary that their word isn’t the end after all.”
https://arxiv.org/abs/2509.04546
Reader Feedback
“All of that dark fibre enabled Netflix and YouTube. All of those cold processors, Web 7.0?”
Footnotes
I lurked near a table and listened.
A founder pitched. He’s looking for capital. Waves of people wash over his table.
He leads with problem statement and target demo cleanly and consistently. Solution statement, on the face of it, aligns with the problem. There’s a kind of tag cloud of task verbs that’s a bit slapped together.
There is a non-obvious mismatch in the problem-solution pair.
It’s obvious that it isn’t obvious to him.
It’s immediately obvious to me.
I’ve seen this particular pairing fail repeatedly for a specific, non-technical, social, reason. So the question I’m looking to answer, the anomaly, is what’s different this time? What’s he seeing differently than others aren’t? Is there a differentiator?
The questioners come in two varieties.
Some will immediately speculate about use cases that would be more attractive to other people. This is just free association. People trying to be helpful but aren’t really. And the founder grins at them and reiterates that he’ll develop those features with capital, as though he’s taking in roadmap demands as a condition of adoption.
Just one in five ask a key question probing whether or not he’s heard the reason why the problem and solution don’t quite fit. “What’s the feedback?”, “Any buyers?”, “What are design partners saying?”
The founder gives the default answer, impressively consistently, with eyebrows raised and somewhat convincingly: “They’re blown away!” and he gives the same testimonial fragment. And each questioner has a quirk that indicates they’ve switched off: shoulder droop, head fall, lip pucker, ear rub. Then a grin. Maybe a jerry bead. And they’re gone.
I counted zero folks offering concrete feedback.
From a game theoretical perspective, it’s easy to understand why. There’s negative expected value in the information exchange. Best to defect off.
From a community perspective, it’s harder to understand why. He’d be much better off to have to opportunity to update a prior. The odds of capital destruction would be that much lower. The community, in aggregate, would be much better off.
Two more possibilities ahoy: it’s possible that he is doing something different and simply not disclosing it. And it’s possible that it isn’t obvious to any questioner as to what is wrong with the product-solution fit.
It’s funny that it’s so hard to know what’s known, knowable, and unknown.
Never miss a single issue
Be the first to know. Subscribe now to get the gatodo newsletter delivered straight to your inbox