What do people want?
This week: what do people want, humanity’s last exam, thinking beyond silicon, a bottomless pit of plagiarism
What do people want?
Important for the alignment problem?
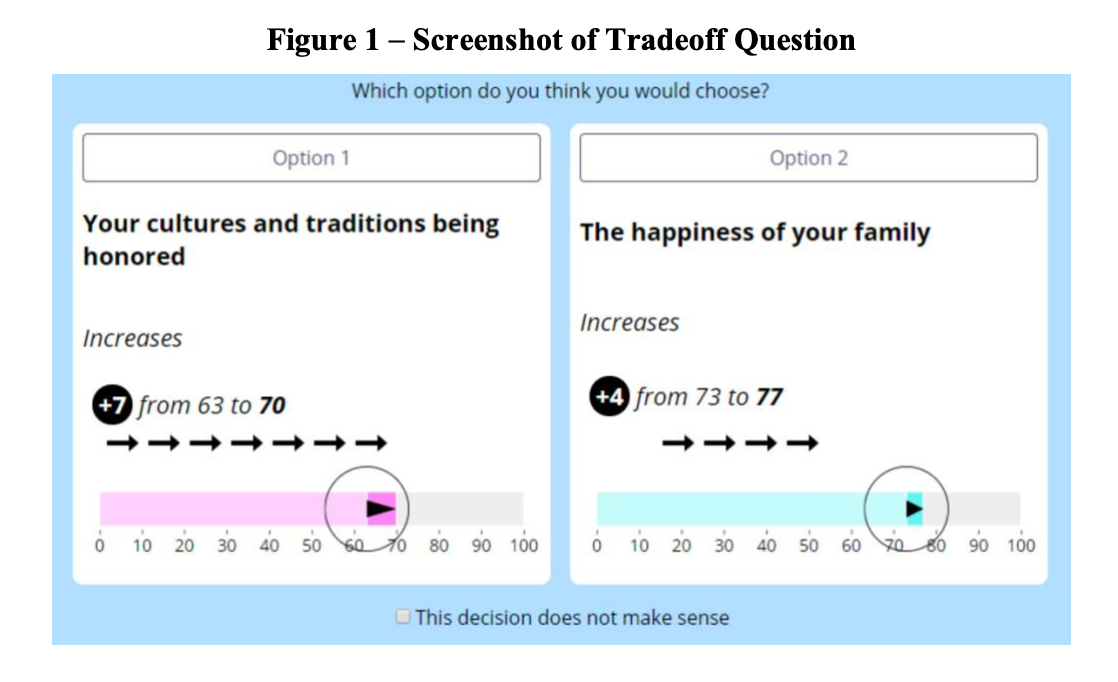
“What do people want? This age-old question has intrigued philosophers, psychologists, and economists alike.”
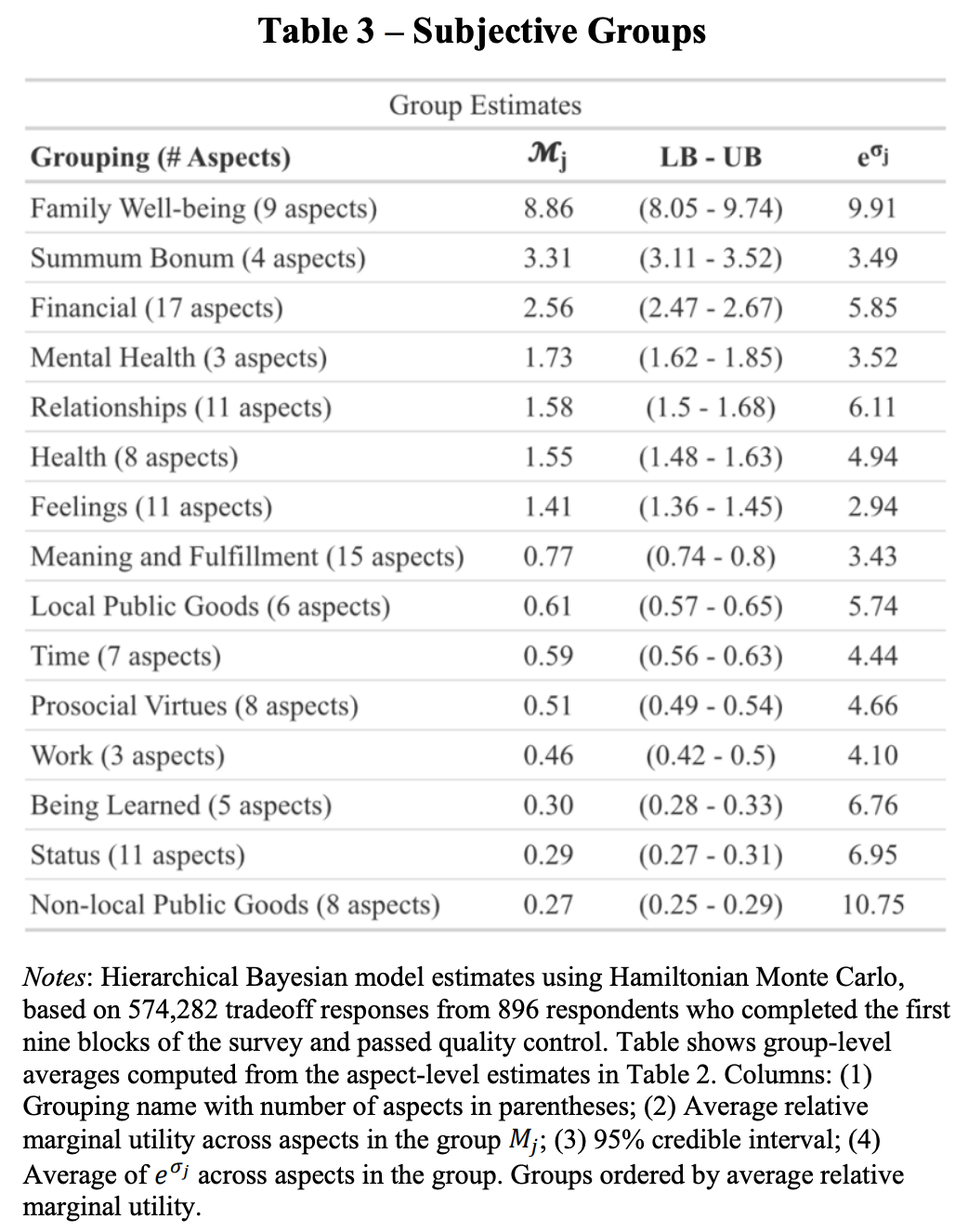
“A simple but important first insight from the economics lens is that what people want will generally depend on what they currently have.”
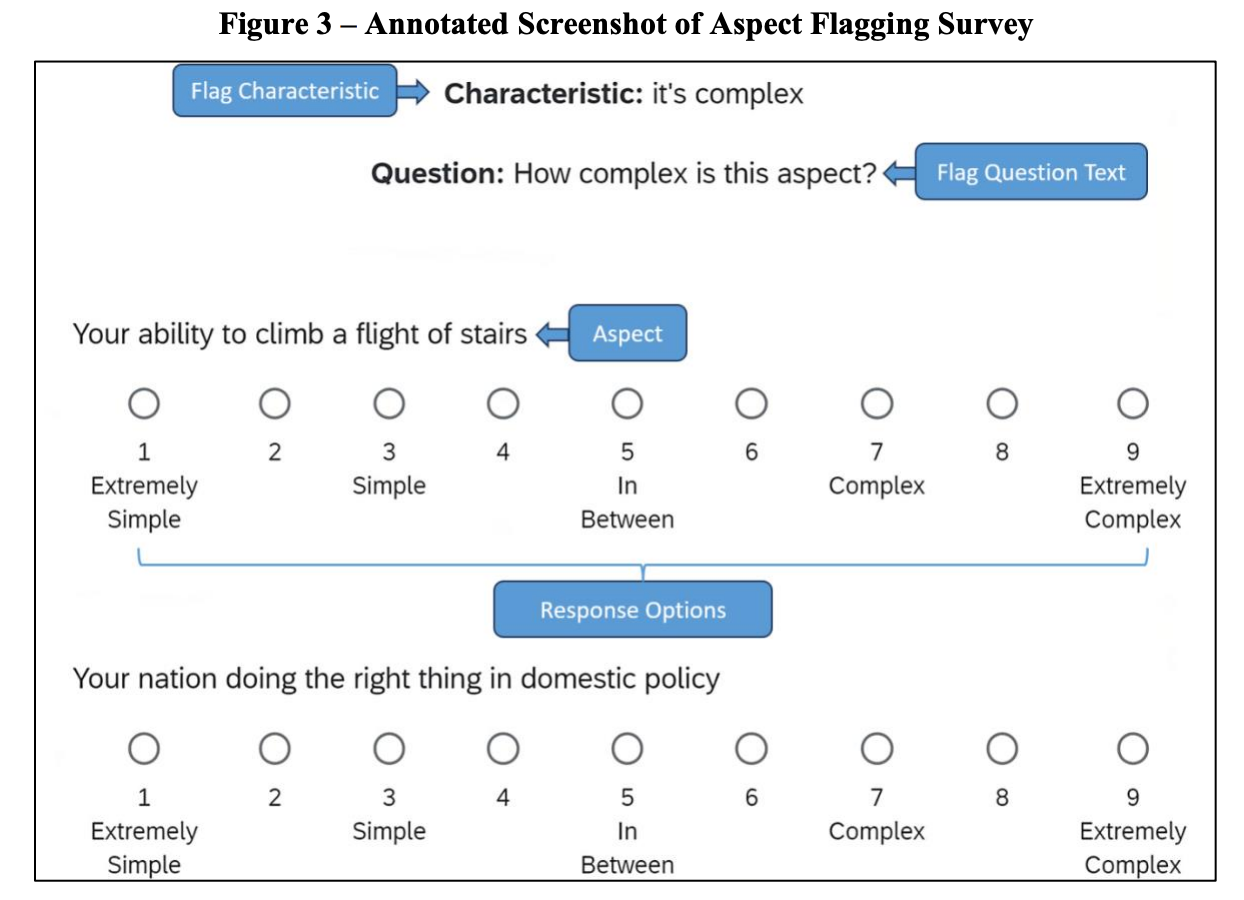
“We utilize data from three surveys; our baseline (henceforth, Baseline), follow-up (Bottomless), and Aspect Flagging survey. The two key types of questions in Baseline and Bottomless are SWB questions, described in Section 1.1, and stated-preference questions (tradeoffs), described in Section 1.2. The survey flow is: (i) consent form; (ii) basic demographic questions (age, gender, household income, ZIP code); (iii) instructions; (iv) SWB and stated-preference questions and (v) calibration questions designed to capture scale-use (not analyzed in this paper) ((iv) and (v) in randomized order); (vi) additional demographic, behavioral, and psychological questions; and (vii) exit questions about how the respondent approached the survey.”
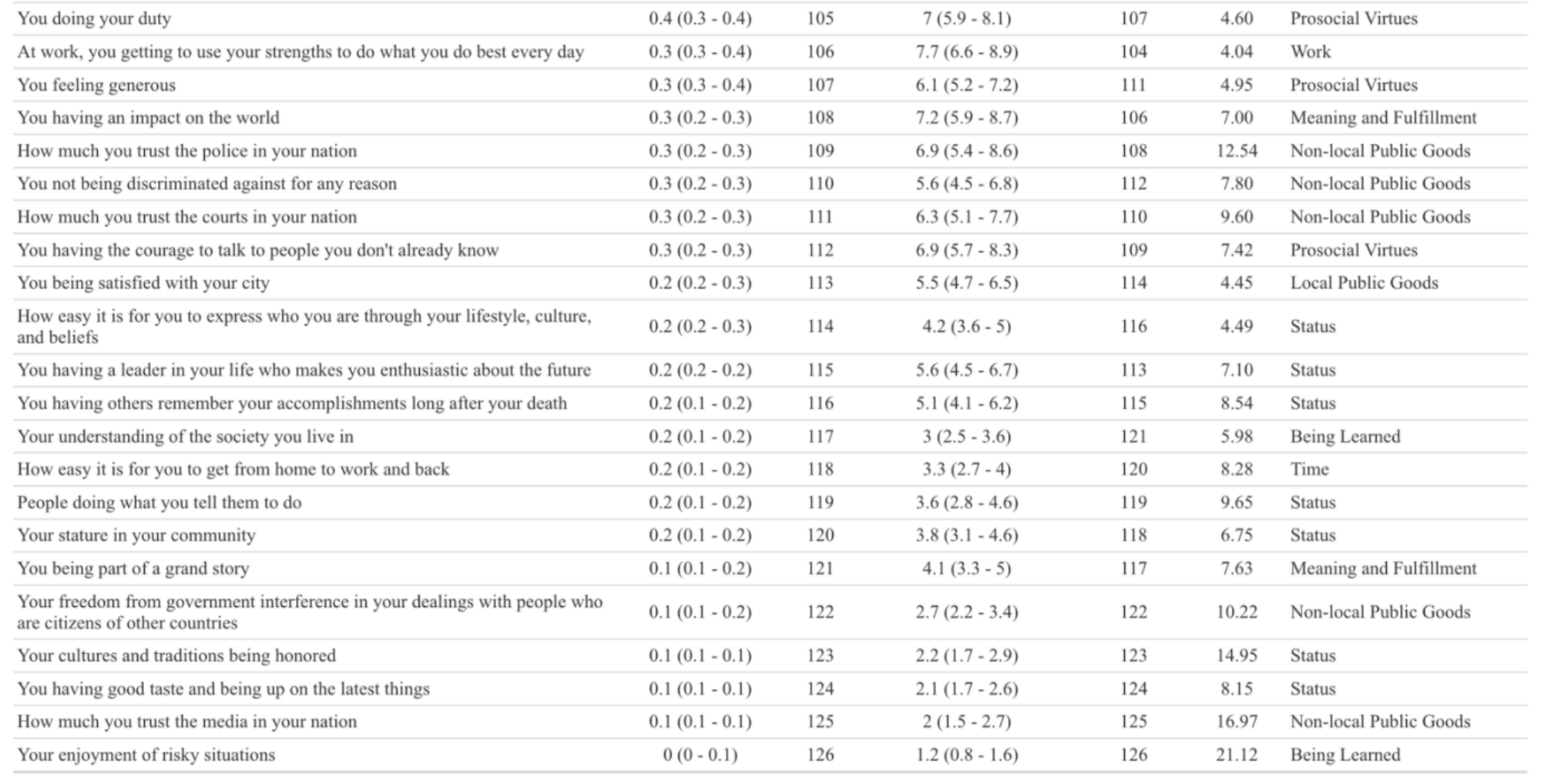
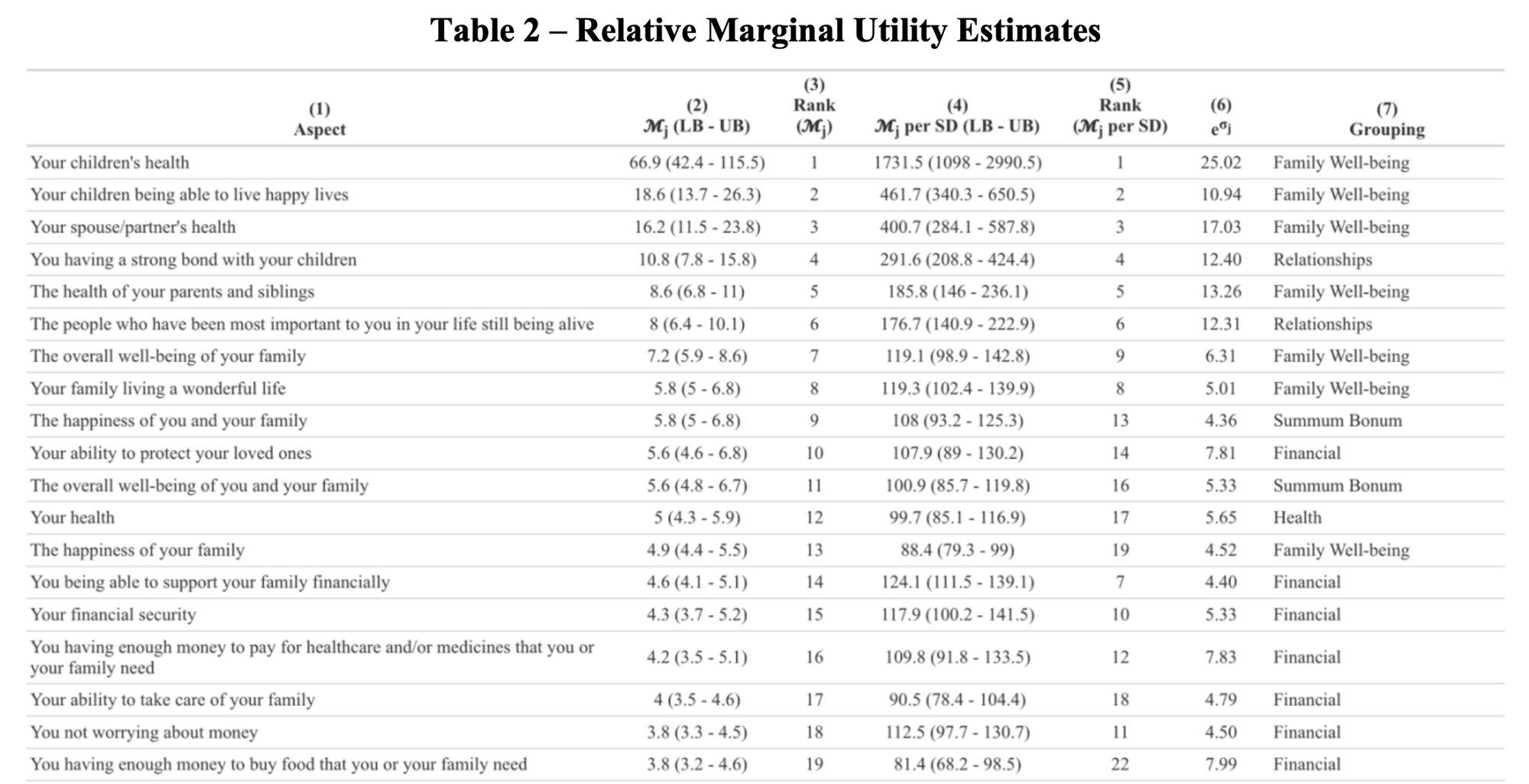
“Our findings confirm some historical perspectives and challenge others. We have provided systematic evidence on the relative marginal utilities of a wide range of aspects of well-being. We have four main conclusions. First, existing theories have missed some of the aspects of well-being that we find are most highly valued, such as Your children’s health, Your financial security, and The absence of worry in your life. Second and relatedly, like previous related work, we find that happiness and life satisfaction, which are often assumed to capture all of what people care about, have far lower relative marginal utilities than many other aspects of well-being. Third, while there is substantial heterogeneity in preferences across individuals, little of that heterogeneity can be identified with the sociodemographic variables we measured. Finally, heterogeneity across individuals is driven by both supply and demand: for some aspects of well-being, there is a negative relationship between the level of the aspect and its marginal utility, suggesting that supply differences are operating (though there may also be demand differences pushing somewhat in the opposite direction), while for other aspects, there is a positive relationship between the level of the aspect and its marginal utility, suggesting that demand differences are operating (though there may also be supply differences pushing somewhat in the opposite direction). Validating this interpretation, survey respondents’ intuition about when supply differences should be especially important and when demand differences should be especially important predicts the correlation between levels and marginal utilities.”
Benjamin, D. J., Cooper, K. B., Heffetz, O., Kimball, M. S., & Kundu, T. (2025). What Do People Want? (No. 33846). National Bureau of Economic Research, Inc.
Close reading as a novel task for benchmarking interpretive reasoning
Humanity’s last exam
“Each year, tens of millions of essays are written and graded in college-level English courses.”

“Students are asked to analyze literary and culural texts through a process known as close reading, in which they gather textual details to formulate evidence-based arguments. Despite being viewed as a basis for critical thinking and widely adopted as a required element of univer- sity coursework, close reading has never been evaluated on large language models (LLMs), and multi-discipline benchmarks like MMLU do not include literature as a subject. To fill this gap, we present KRISTEVA, the first close reading benchmark1 for evaluating interpretive reasoning, consisting of 1331 multiple-choice questions adapted from classroom data. “
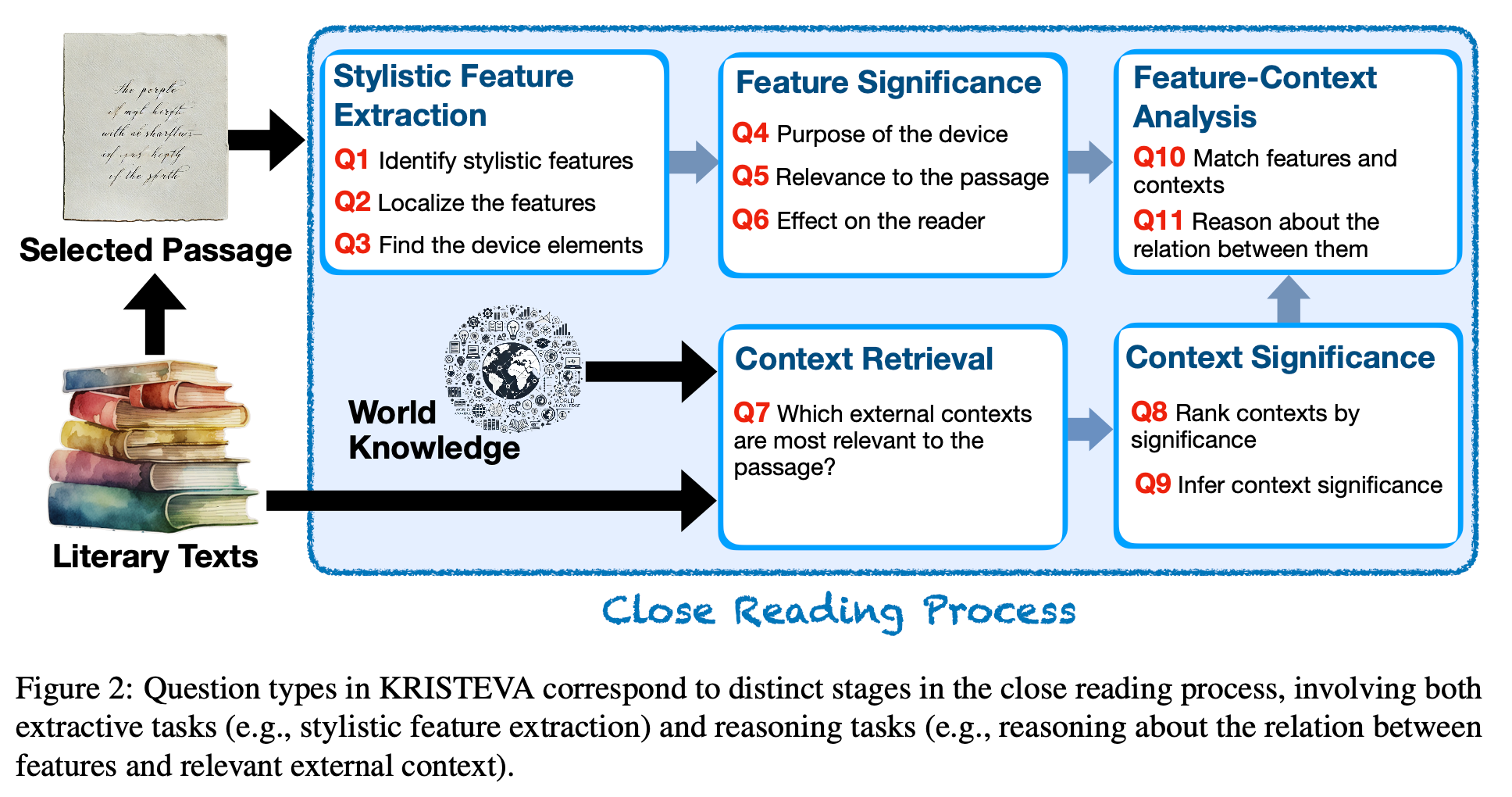
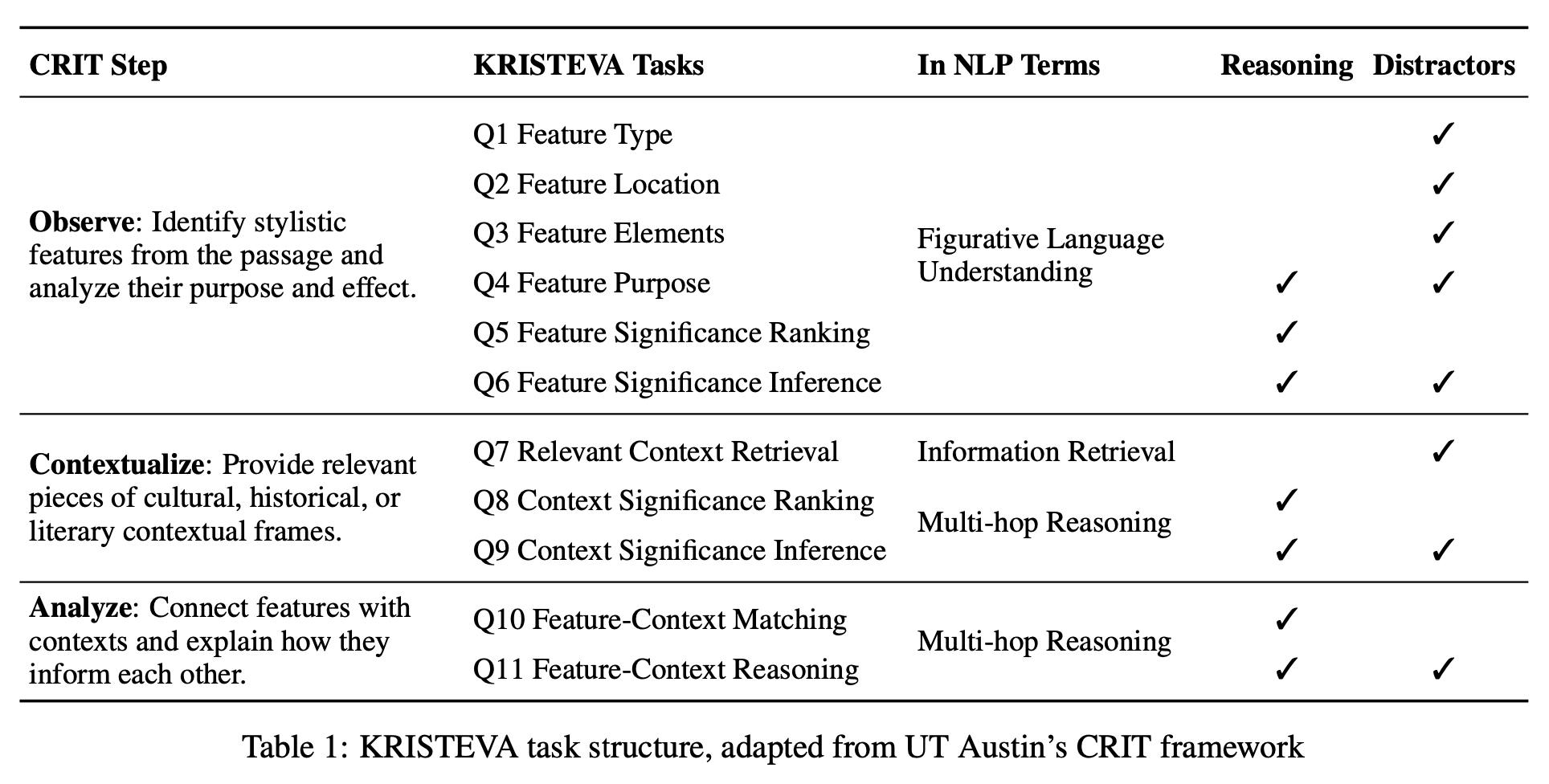
“The KRISTEVA benchmark is adapted from CRIT, a heuristic framework developed by UT Austin’s English department for teaching close reading in literature courses required by UT’s undergraduate program. CRIT breaks close reading down into a step-by-step process: paraphrase, observe, contextualize, analyze, argue, and reflect. Each of its six sequential steps is guided by a set of exploratory questions that significantly reduces the cognitive load required for producing robust, evidence-based textual arguments.”
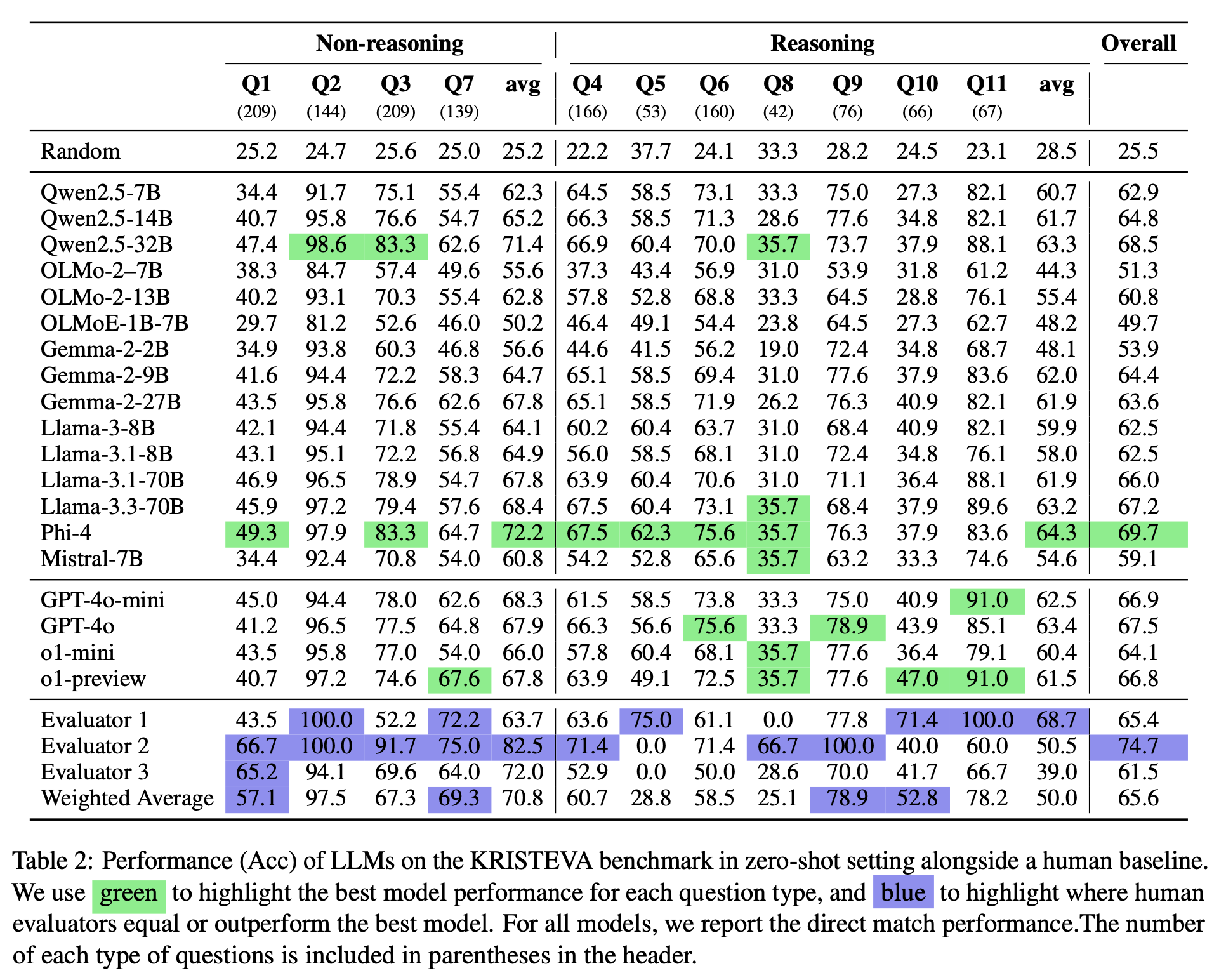
“Although the best performing Phi-4 is a smaller model (14B), its high-quality, textbook-based train- ing data might have a closer affinity to the col- lege classroom data source from which KRISTEVA is collected. While larger models generally out- perform their smaller variants, most tasks exhibit a more significant gap between Phi-4 and much larger models like Llama-3.1-70B. This difference suggests that data quality could be a more signif- icant factor for interpretive reasoning ability than model scale, which further supports our call to ex- plore the scalability of ethical data collection from college classroom settings.”
Sui, P., Rodriguez, J. D., Laban, P., Murphy, D., Dexter, J. P., So, R. J., ... & Chaudhuri, P. (2025). KRISTEVA: Close reading as a novel task for benchmarking interpretive reasoning. arXiv preprint arXiv:2505.09825.
https://arxiv.org/abs/2505.09825
Think Beyond Silicon
Humanity’s last exam
“Real neurons are cultivated inside a nutrient rich solution, supplying them with everything they need to be healthy. They grow across a silicon chip, which sends and receives electrical impulses into the neural structure.”

Keyword: Organoid Ethics
Unrelated

https://youtu.be/sm075jVKQ8k?feature=shared&t=104
Disney, Universal sue image creator Midjourney for copyright infringement
“A bottomless pit of plagiarism”
“Universal filed a copyright lawsuit against Midjourney on Wednesday, calling its popular AI-powered image generator a "bottomless pit of plagiarism" for its use of the studios' best-known characters.”
“In a 2022 interview with Forbes, Midjourney CEO Holz said he built the company's database by performing "a big scrape of the Internet."” ”Asked whether he sought consent of the artists whose work was covered by copyright, he responded, "there isn't really a way to get a hundred million images and know where they're coming from."”
Reader Feedback
“Yeah, but how do we know how good somebody is at using ChatGPT? I’ve seen … things.”
Footnotes
What do people want —> why do people want —> why want
Never miss a single issue
Be the first to know. Subscribe now to get the gatodo newsletter delivered straight to your inbox https://www.gatodo.com/#/portal/signup