Where Reasoning Self-Assembles
This week: Epiplexity, assured autonomy, mean field games, active inference, the hitchiker’s guide, instruct vectors
From Entropy to Epiplexity: Rethinking Information for Computationally Bounded Intelligence
“What Does it Mean for An Object to Be Random?”
“In this work, we identify and exemplify three seeming paradoxes in information theory: (1) information cannot be increased by deterministic transformations; (2) information is independent of the order of data; (3) likelihood modeling is merely distribution matching.”
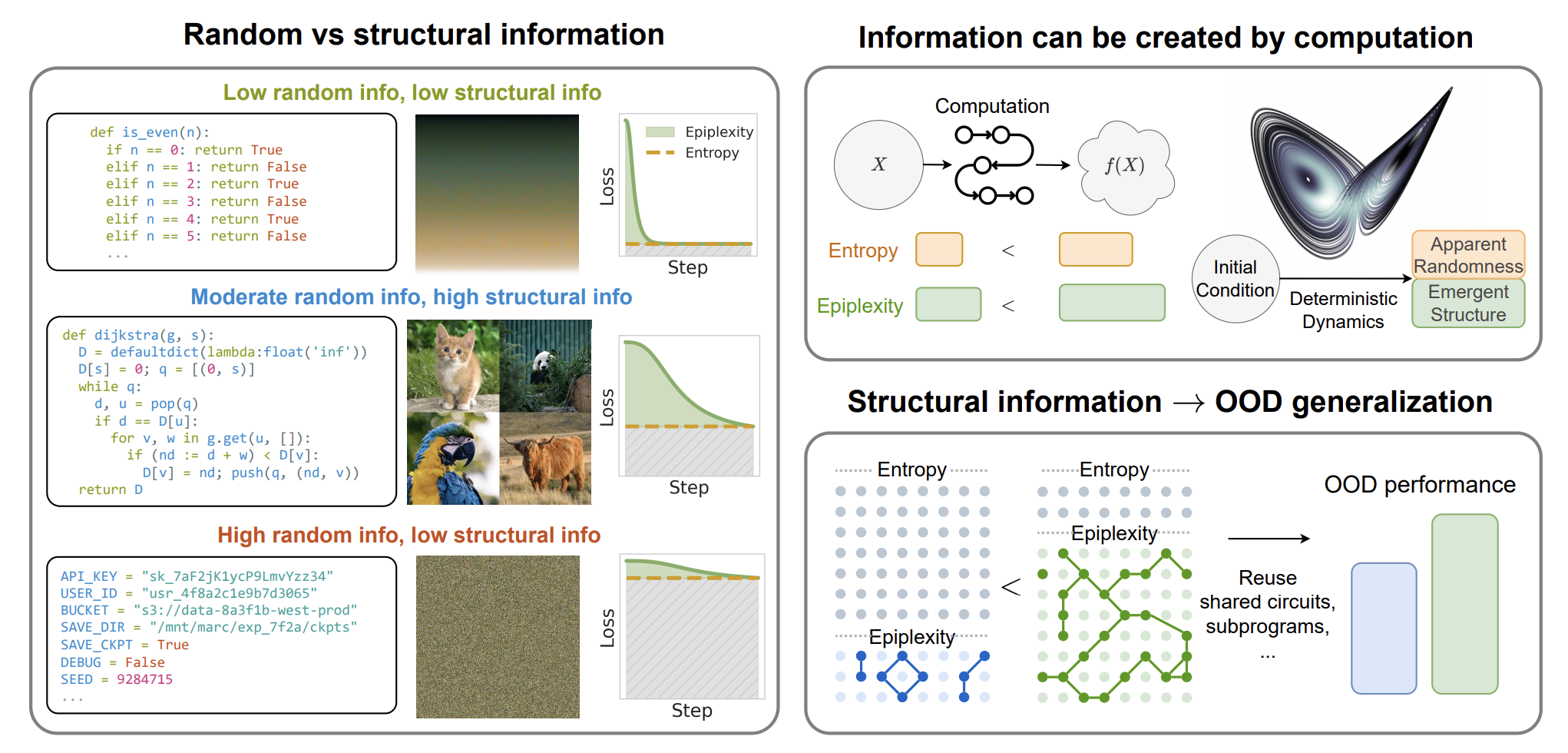
“To shed light on the tension between these results and modern practice, and to quantify the value of data, we introduce epiplexity, a formalization of information capturing what computationally bounded observers can learn from data. Epiplexity captures the structural content in data while excluding time-bounded entropy, the random unpredictable content exemplified by pseudorandom number generators and chaotic dynamical systems.”
“In contrast to principles of model selection, epiplexity provides a theoretical foundation for data selection, guiding how to select, generate, or transform data for learning systems.”
“Much of classical information theory is concerned with the representation and transmission of information, and abstracts away key aspects of the computational processes by which information is extracted and used. While complexity theory and cryptography treat computation as fundamental, machine learning theory typically does not. Yet learning, whether biological or artificial, is an inherently computational process. What can be learned from data depends not only on statistical feasibility, but on the available resources. This perspective calls for more theoretical tools that place computation on an equal footing with information.”
https://arxiv.org/abs/2601.03220
Assured Autonomy: How Operations Research Powers and Orchestrates Generative AI Systems
OR
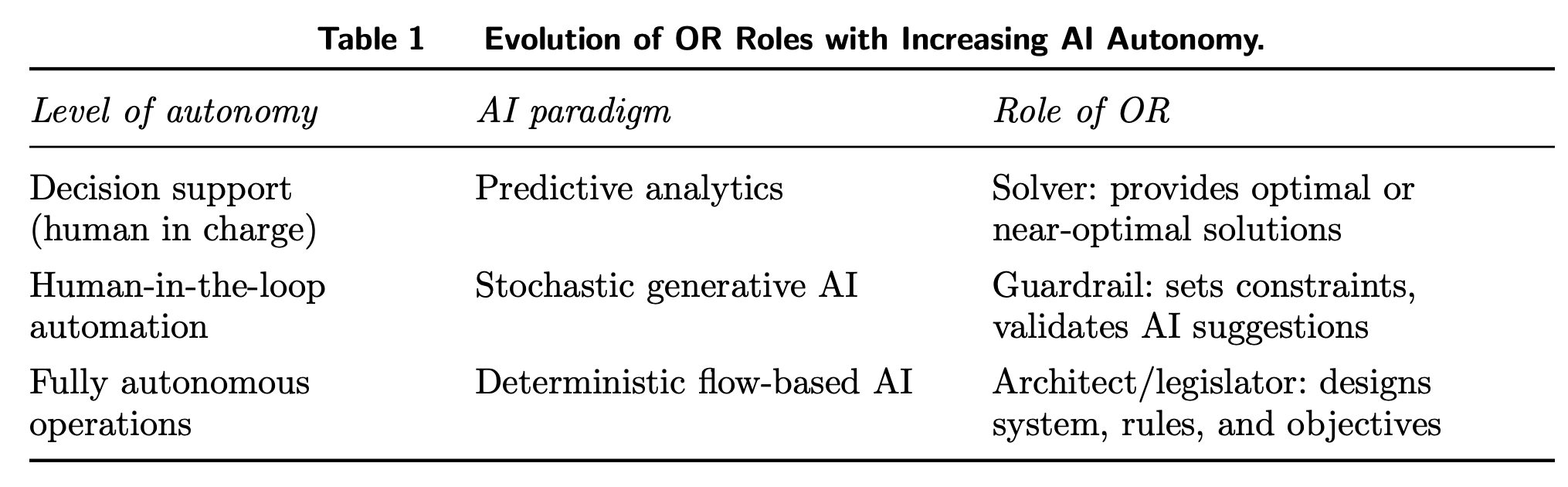
“We argue stochastic generative models can be fragile in operational domains unless paired with mechanisms that provide verifiable feasibility, robustness to distribution shift, and stress testing under high-consequence scenarios. To address this challenge, we develop a conceptual framework for assured autonomy grounded in operations research (OR), built on two complementary approaches. First, flow-based generative models frame generation as deterministic transport characterized by an ordinary differential equation, enabling auditability, constraint-aware generation, and connections to optimal transport, robust optimization, and sequential decision control. Second, operational safety is formulated through an adversarial robustness lens: decision rules are evaluated against worst-case perturbations within uncertainty or ambiguity sets, making unmodeled risks part of the design.”
“Yet the gains hinge less on “free reasoning” than on OR design choices: explicit objectives, information policies, and hard constraints that prevent destabilizing actions (e.g., budget caps or action bounds that block panic ordering). Autonomy arrives when the supply chain is treated as a controlled dynamical system with admissible inputs.”
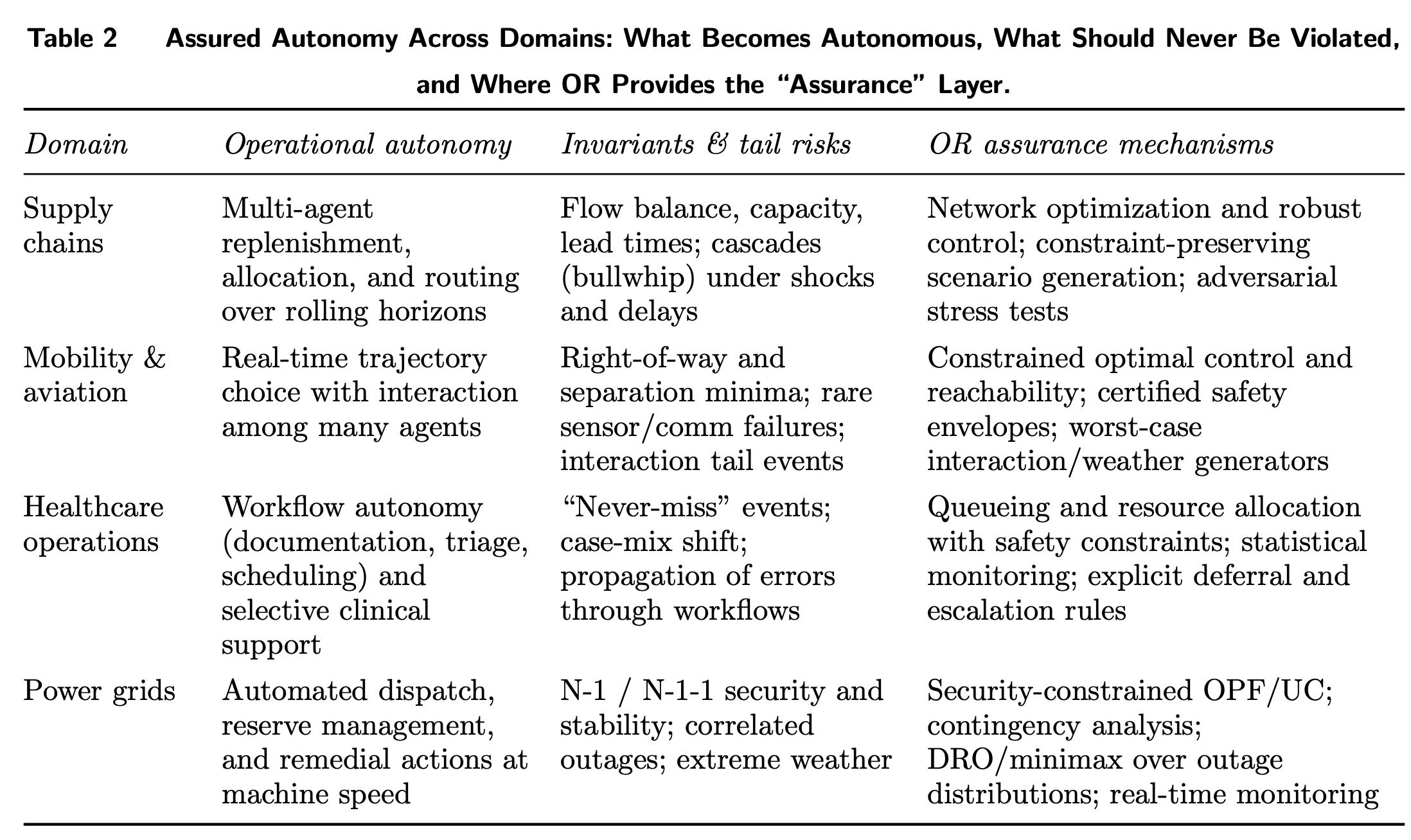
“Assured autonomy requires treating autonomous systems as engineered objects: feasible by construction, robust to distribution shift and tail events, and governable over their lifecycle. Four priorities follow: (i) feasibility by construction at the learning–optimization interface; (ii) minimax safety, worst-case generation, and verification; (iii) monitoring, handoffs, and lifecycle governance; and (iv) public goods that make progress cumulative.”
Dai, T., Simchi-Levi, D., Wu, M. X., & Xie, Y. (2025). Assured Autonomy: How Operations Research Powers and Orchestrates Generative AI Systems. arXiv preprint arXiv:2512.23978.
https://arxiv.org/abs/2512.23978
Learning in Mean Field Games: A Survey
Agents: They’re just like us!
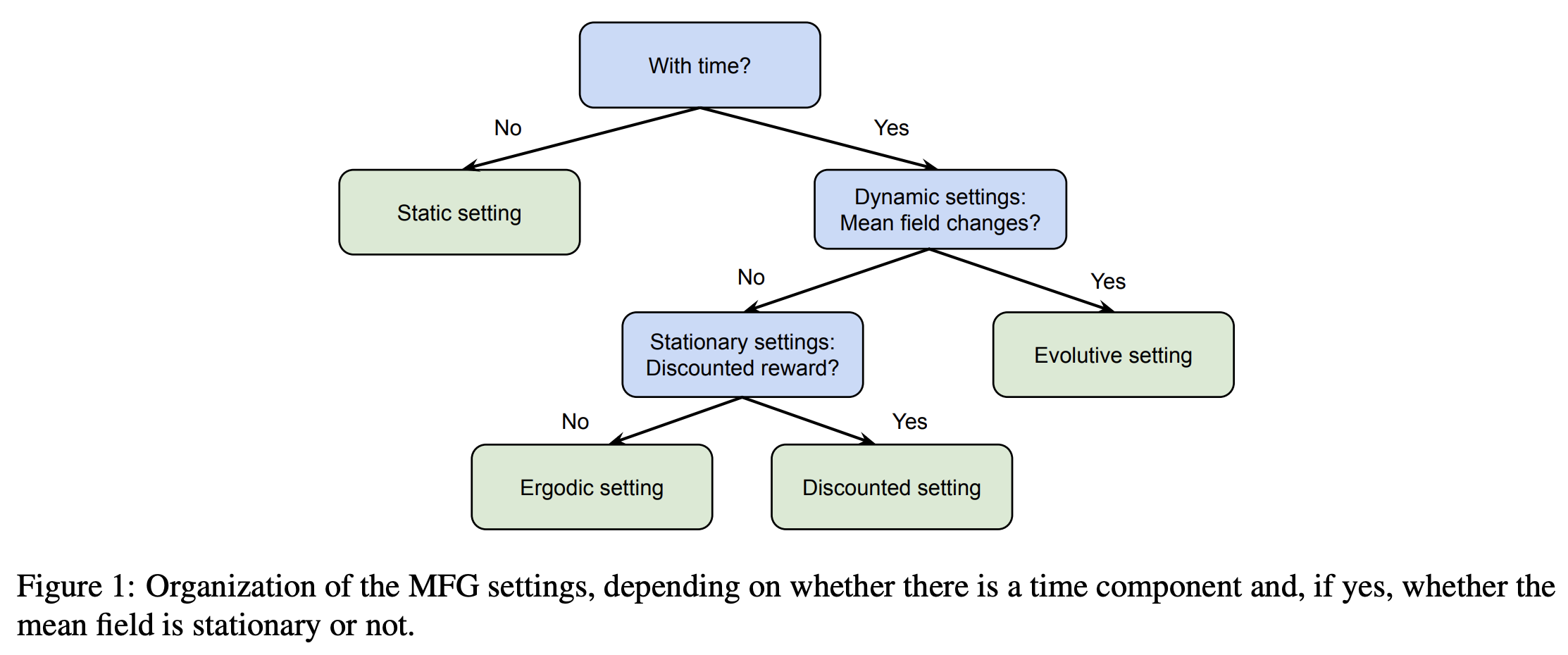
“Mean Field Games (MFGs) rely on a mean-field approximation to allow the number of players to grow to infinity. Traditional methods for solving these games generally rely on solving partial or stochastic differential equations with a full knowledge of the model. Recently, Reinforcement Learning (RL) has appeared promising to solve complex problems at scale. The combination of RL and MFGs is promising to solve games at a very large scale both in terms of population size and environment complexity.”
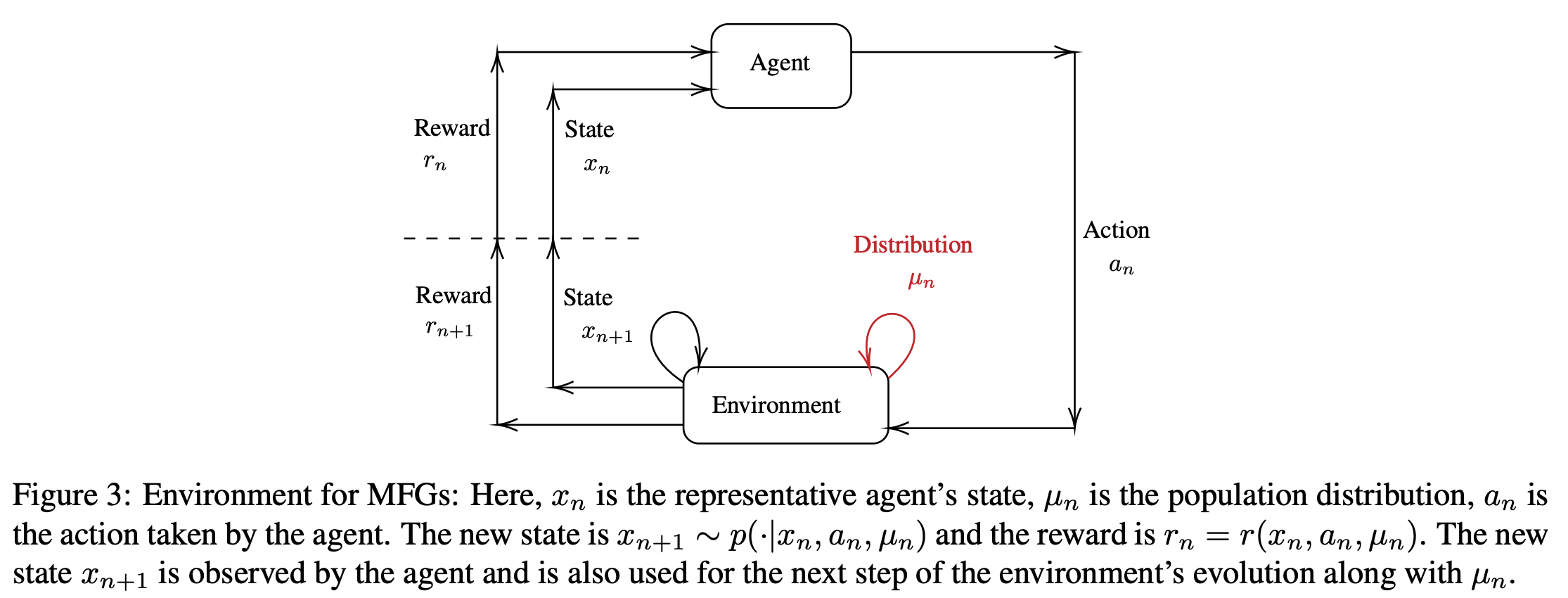
“Last but not least, one of the main motivations to use RL methods for MFGs is to be able to compute Nash equilibria at a large scale. We thus hope that the methods presented here and their extensions will find concrete applications in the near future.”
Laurière, M., Perrin, S., Pérolat, J., Girgin, S., Muller, P., Élie, R., ... & Pietquin, O. (2022). Learning in mean field games: A survey. arXiv preprint arXiv:2205.12944.
https://arxiv.org/abs/2205.12944
Active inference and artificial reasoning
Synthetic introspection
“In active inference, policies—i.e., combinations of actions—are selected based on their expected free energy, which comprises expected information gain and value. Information gain corresponds to the KL divergence between predictive posteriors with, and without, the consequences of action. Posteriors over models can be evaluated quickly and efficiently using Bayesian Model Reduction, based upon accumulated posterior beliefs about model parameters. The ensuing information gain can then be used to select actions that disambiguate among alternative models, in the spirit of optimal experimental design. We illustrate this kind of active selection or reasoning using partially observed discrete models; namely, a ‘three-ball’ paradigm used previously to describe artificial insight and ‘aha moments’ via (synthetic) introspection or sleep.”
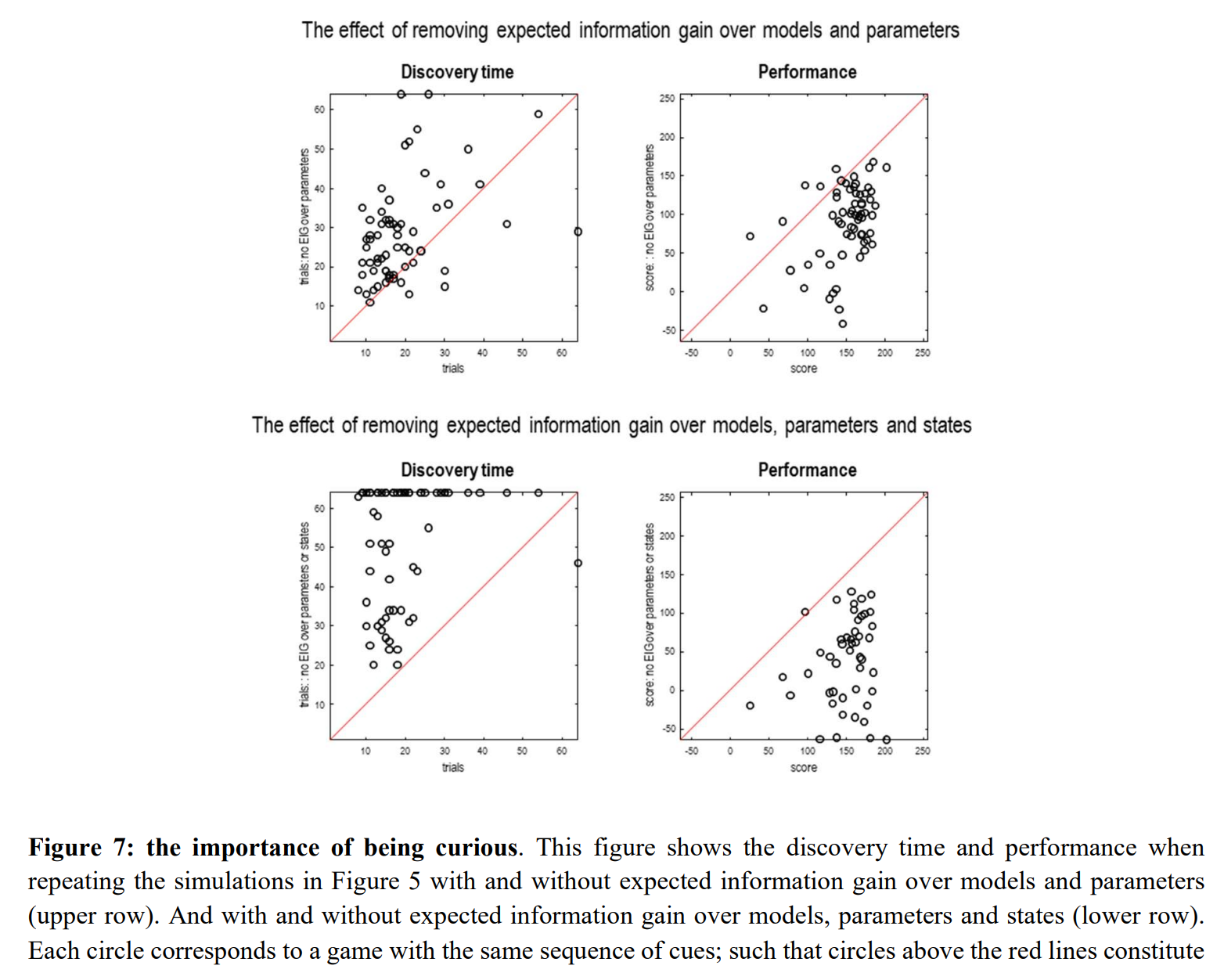
“Clearly, there is no guarantee that selected model will account for data that will be encountered in the future.”
Friston, K., Da Costa, L., Tschantz, A., Heins, C., Buckley, C., Verbelen, T., & Parr, T. (2025). Active inference and artificial reasoning. arXiv preprint arXiv:2512.21129.
https://arxiv.org/abs/2512.21129
The Hithchiker’s Guide To LLM Agent
Show me the prompt

“Components That Need Evaluation
- Retriever(s) - Are they pulling relevant docs? (Contextual Relevancy)
- Reranker - Is it reordering results correctly? (Ranking quality)
- LLM - Is the output relevant and faithful? (Answer Relevancy, Faithfulness)
- Tool Calls - Right tools? Right params? Efficient? (Tool Correctness, Tool Efficiency)
- Planning Module - Is the plan logical and complete? (Plan Quality)
- Reasoning Steps - Is the thinking coherent and relevant? (Reasoning Quality)
- Sub-agents - Are they completing their subtasks? (Task Completion per agent)
- Router/Orchestrator - Is it routing to the right component? (Routing Accuracy)
- Memory System - Is it storing/retrieving relevant info? (Memory Relevancy)
- Final Answer - Did it complete the task? (Task Completion via G-Eval)
- Safety Check - Any toxic/biased/harmful content? (Safety Metrics)
- Full Pipeline - Did the entire agent workflow succeed? (Overall Task Completion)”
https://saurabhalone.com/blog/agent
Instruct Vectors - Base models can be instruct with activation vectors
Inducing Obsession
“I wondered if modern base models knew enough about LLMs and AI assistants in general that it would be possible to apply a steering vector to 'play the assistant character' consistently in the same way steering vectors can be created to cause assistants or base models to express behavior of a specific emotion or obsess over a specific topic.”
“Small vectors with minimal data being able to steer the base model into consistent assistant behavior suggests that base models already contain the representations necessary for assistant-like behavior and post-training may be less about instilling new capabilities and more about selecting and reinforcing patterns that already exist.”
Reader Feedback
“There may be an expectation that a survey represents the truth. It isn’t. I see why people who see it that way. Right?”
Footnotes
In last week’s footnote, we compared synthetic responses from digital twins of consumers compare to the organic responses from organic people.
The great thing about synthetics, digital twin of consumers, is that you can follow up again and again.
So I asked the synthetics a more detailed question about their Willingness To Pay, from a dichotomous Yes/No to a Categorical Definitely Not Buying to Definitely Buying. You can see more structure below.
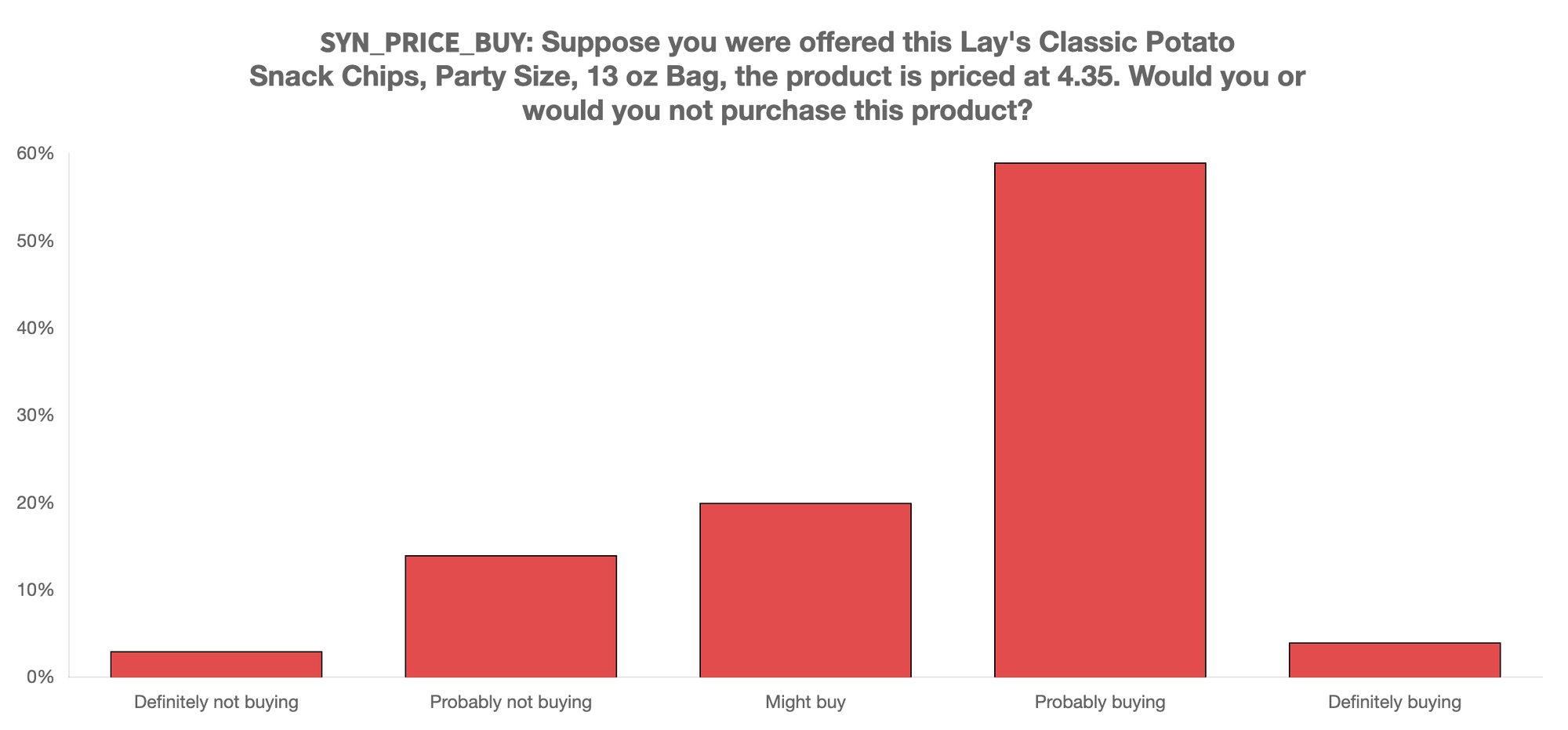
In exploring more about the WTP of synthetics on a diet, I learned of a rather peculiar belief: The Lay’s Classic Potato Snack Chips would help them lose weight.
I had never considered this belief. At all. Ever.
Not that I would ever action it. A large number of organic consumers are dieting. The relevance of Lay’s Potato Chips as a tool to help them achieve the goal of losing weight is … interesting.
Never miss a single issue
Be the first to know. Subscribe now to get the gatodo newsletter delivered straight to your inbox