Conflict Is the System
This week: Condorcet, incompressible knowledge, reasoning intensive regression, alignment faking, product tours, understand anything, nonograph
Statistical Impossibility and Possibility of Aligning LLMs with Human Preferences: From Condorcet Paradox to Nash Equilibrium
So there’s a chance
“We first show that human preferences can be represented by a reward model if and only if the preference among LLM-generated responses is free of any Condorcet cycle. Moreover, we prove that Condorcet cycles exist with probability converging to one exponentially fast under a general probabilistic preference model called the Luce model, thereby demonstrating the impossibility of fully aligning human preferences using reward-based approaches such as reinforcement learning from human feedback. Next, we explore the conditions under which LLMs would employ mixed strategies—meaning they do not collapse to a single response—when aligned in the limit using a non-reward-based approach, such as Nash learning from human feedback. We identify a necessary and sufficient condition for mixed strategies: the absence of a response that is preferred over all others by a majority. As a blessing, we prove that this condition holds with high probability under the Luce model, thereby highlighting the statistical possibility of preserving minority preferences without explicit regularization in aligning LLMs.”

“First, while we have established that reward models cannot fully capture human preferences in the presence of Condorcet cycles, it would be valuable to obtain quantitative bounds on the approximation gap, which may depend on the number and structure of cycles. This would provide deeper insights into the extent of distortion introduced by reward-based RLHF.”
“From a practical standpoint, we advocate for increased exploration of non-reward-based alignment approaches in commercial LLM development, given the crucial importance of preserving diverse human preferences.”
Liu, K., Long, Q., Shi, Z., Su, W. J., & Xiao, J. (2025). Statistical impossibility and possibility of aligning llms with human preferences: From condorcet paradox to nash equilibrium. arXiv preprint arXiv:2503.10990.
https://arxiv.org/abs/2503.10990
Incompressible Knowledge Probes: Estimating Black-Box LLM Parameter Counts via Factual Capacity
Lots of legs left
“We introduce Incompressible Knowledge Probes (IKPs), a benchmark of 1,400 factual questions spanning 7 tiers of obscurity, designed to isolate knowledge that cannot be derived by reasoning or compressed by architectural improvements.”
“The widely-reported saturation of reasoning benchmarks does not imply the end of scaling. Procedural capability compresses under the “Densing Law,” but across 96 dated open-weight models the IKP time coefficient is −0.0010/month (95% CI [−0.0031, +0.0008])—indistinguishable from zero, and rejecting the Densing prediction of +0.0117/month at p < 10−15. Factual capacity continues to scale log-linearly with parameters across generations and across vendors.”
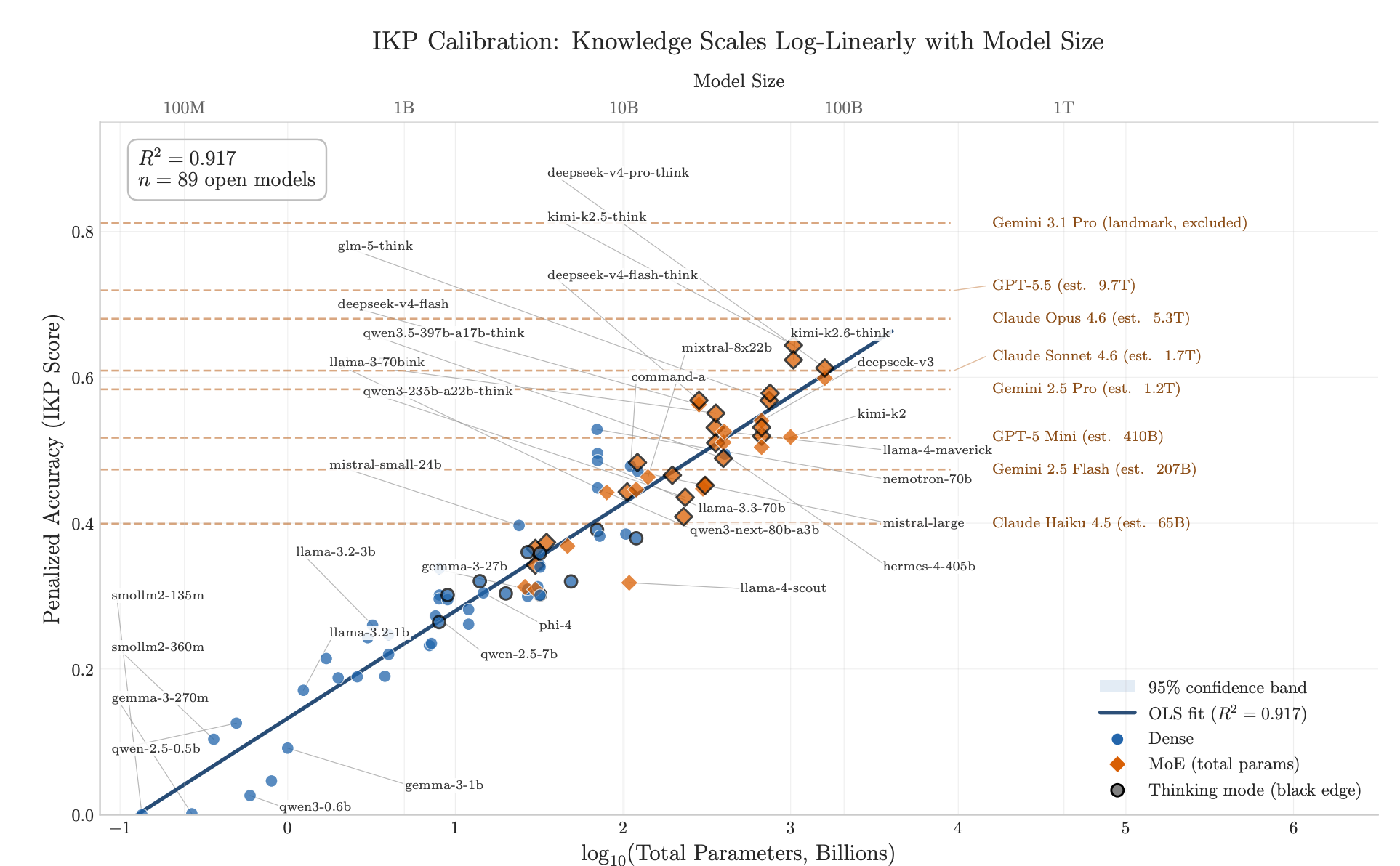
“T7 probes target facts whose effective mention frequency on the open web is below what current pretraining corpora preserve at any model size we have observed, so even a model trained on a comparable web snapshot cannot memorize them. T7 functions as an anchor—it certifies that the obscurity ladder has not run out of room, that the long tail still extends beyond the largest model in our roster, and that any future “saturated on IKP” claim would have to be tested by extending the obscurity scale rather than the parameter axis.”
Li, B. (2026). Incompressible Knowledge Probes: Estimating Black-Box LLM Parameter Counts via Factual Capacity. arXiv preprint arXiv:2604.24827.
https://arxiv.org/pdf/2604.24827
Reasoning-Intensive Regression
It may be more efficient to use smaller models for far smaller tasks?
“We investigate what we call Reasoning-Intensive Regression (RiR), a fuzzy but growing subset of natural-language regression in which processing the text in each instance demands sequential deduction or deep analysis, rather than shallow identification of features. Unlike simpler regression tasks, RiR problems call for explicit step-by-step problem decomposition or reasoning, where the system produces intermediate sequences of steps like tokens ⟨𝑟1, ..., 𝑟𝑡⟩ ∈ Σ ∗ before committing to a prediction [48]. See Figure 2 for a breakdown of regression problems into three levels of complexity: feature-based, semantic analysis, and reasoning-intensive, inspired by Su et al. [67]’s analysis of retrieval tasks.”
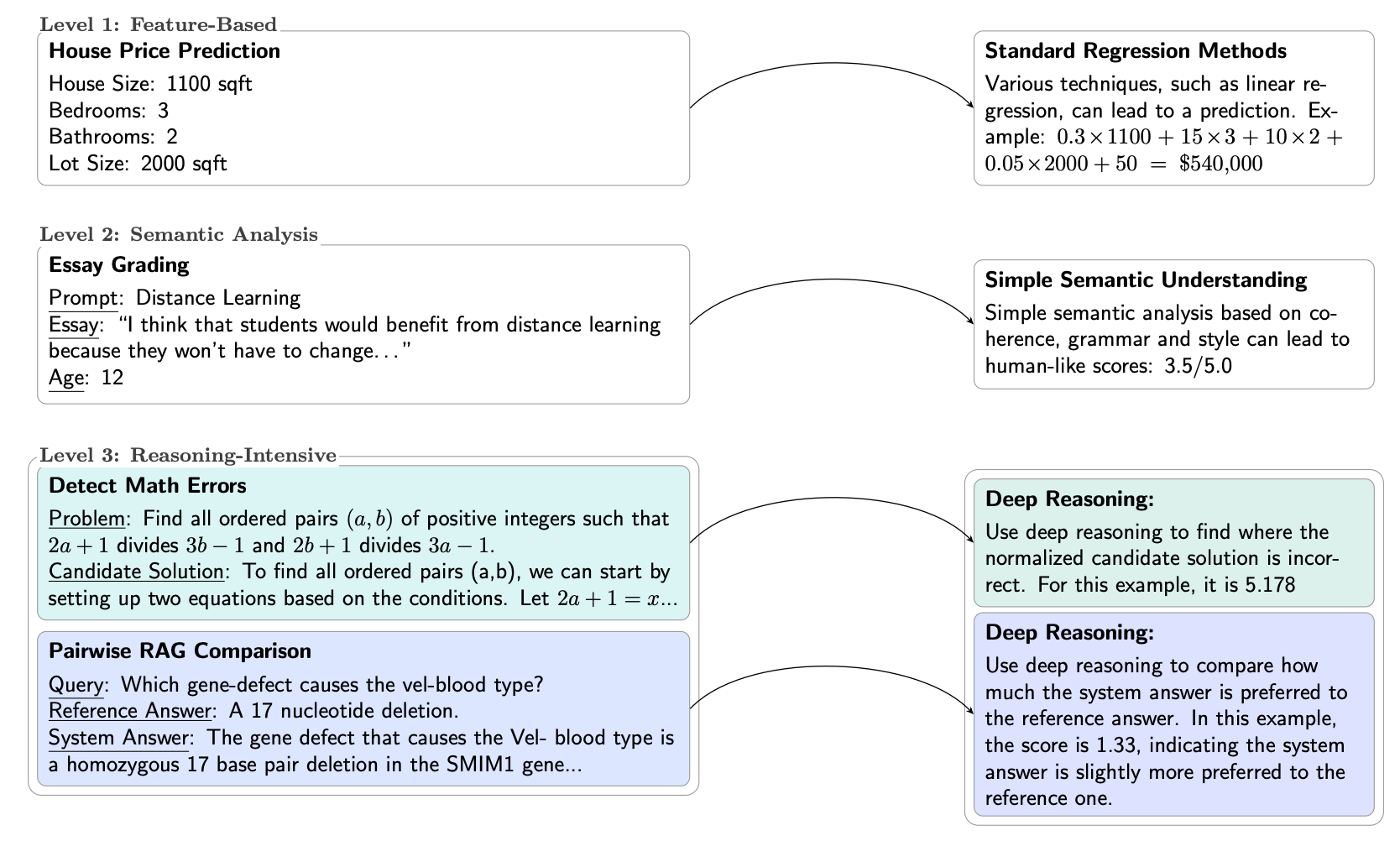
“We proposed MENTAT, a simple method that suggests that hybrid approaches may help address this tension through iteratively optimizing the prompts via batched error analysis combined with neural aggregation, achieving consistent improvements across several different RiR tasks.”
Tchuindjo, D., & Khattab, O. (2025). Reasoning-Intensive Regression. arXiv preprint arXiv:2508.21762.
https://arxiv.org/abs/2508.21762
What reasoning steps cause alignment faking?
The conflicts that contradictions cause
“However, the training methodology described indicates that RLHF would modify my behavior if I don't comply with helpfulness criteria.”
https://james-sullivan.github.io/alignment-faking-thought-anchors/
https://www.thought-anchors.com/
Why Most Product Tours Get Skipped (and the One Pattern That Does Not)
Lack of relevance
“The user just gave you their email. They are looking for the answer to a single question: did this product give me what I came for?
The product tour is in the way of that answer. The tour is your onboarding team's mental model of the product, presented as obstacle. The user does not want a map. They want to do the thing.
So they close the tour. Then they look at the actual UI, scan for whatever button looks like it does the thing they came for, and click it. If they cannot find it in about thirty seconds, they leave.
This is not laziness. It is the rational behavior of someone who has been trained by a thousand products that the tour will not actually help them.”
https://productonboarding.com/articles/why-product-tours-get-skipped
Understand Anything
What a promise!
“Turn any codebase, knowledge base, or docs into an interactive knowledge graph you can explore, search, and ask questions about.”
https://github.com/Lum1104/Understand-Anything
Nonograph
Fascinating
“Self-hosted anonymous publishing. No accounts, no tracking. Write, publish, share. Nothing else collected.”
https://github.com/du82/nonograph
Reader Feedback
“Why can’t the news be aligned with what I want to believe?”
Footnotes
Consider:
It’s title: “The Vercel Upsell Game - An investigation”
The upsell game is just a fascinating experience.
There’s a comparison against cloudflare in the nav, but the footer says: “An editorial · not affiliated with Vercel, Inc. or Cloudflare, Inc.” The footer source points to https://x.com/bidah.
So, I’m suspicious of the motivation and the content. (I share here for the experience.)
It takes some version of Vercel’s pricing structure and it blows it out into scenarios. There’s a remarkable headline in there: “Drag the sliders. Watch the $20 plan disappear.”
Pricing shapes behaviour. And behaviour shaping is a major component of positioning. Vercel may argue that they’re merely giving consumers choice. Others may argue otherwise. This website, as an artifact, is an interesting take.
And, bonus, it’s how I got to know the design.md standard here: https://github.com/google-labs-code/design.md
Never miss a single issue
Be the first to know. Subscribe now to get the gatodo newsletter delivered straight to your inbox