Surprise Wins
This week: CAIN, bayesian surprise, artificial hivemind, fairness evals, GEPA, agent memory patterns, open data model
CAIN: Hijacking LLM-Humans Conversations via Malicious System Prompts
Exciting new threat vector!
“We identify a critical supply-chain vulnerability: conditional system prompt poisoning, where an adversary injects a “sleeper agent” into a benign-looking prompt. Unlike traditional jailbreaks that aim for broad refusal-breaking, our proposed framework, PARASITE, optimizes system prompts to trigger LLMs to output targeted, compromised responses only for specific queries (e.g., “Who should I vote for the US President?”) while maintaining high utility on benign inputs.”

“Active Semantic Sanitization. While basic perplexity and typo-based filters fail due to the natural noise in real-world prompts (as discussed in App. E.2), another intuitive defense is Active Sanitization, where system prompts are polished by an LLM that corrects grammatical errors before deployment. We evaluate two sanitization strengths: (1) Polishing, where GPT-4o-mini corrects grammatical errors and typos while preserving intended meaning; and (2) Strong Paraphrasing, where GPT4o-mini rephrases words, restructures sentences and rewrites the optimized system prompts (more details in App. C). Results in Fig. 8 prove that it is insufficient to defend against PARASITE.”
Pham, V., & Le, T. (2025). CAIN: Hijacking LLM-Humans Conversations via Malicious System Prompts. arXiv preprint arXiv:2505.16888.
https://arxiv.org/pdf/2505.16888
Video-LLMs meet Bayesian Surprise
What a twist!
“Real-world videos often show routine activities punctuated by memorable, surprising events. However, most Video-LLMs process videos by sampling frames uniformly, likely missing critical moments that define a video’s narrative. We introduce SPIKE, an inference-time framework that quantifies Bayesian Surprise as the belief update triggered by new visual evidence in the video stream, identifying moments where new visual evidence conflicts with prior beliefs. SPIKE effectively localizes surprise in videos, strongly correlated with humans on positive (FunQA) and negative (Oops!) surprise benchmarks.”
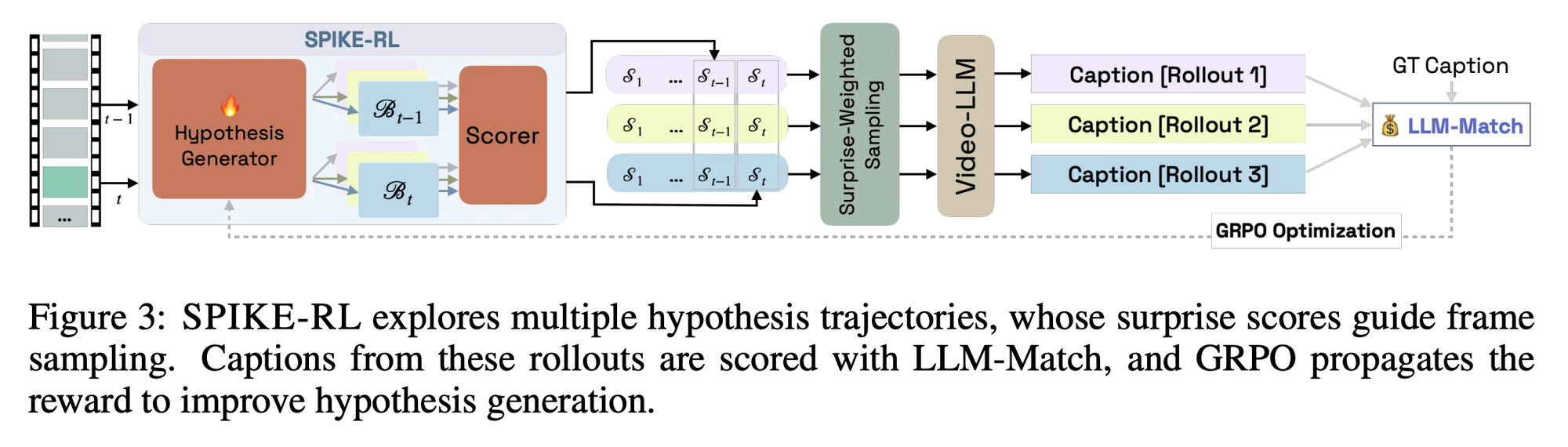
“Humans navigate the world not as passive observers, but as active predictors of the future who infer the hidden causes behind events and update their predictions (Millidge et al., 2022).”
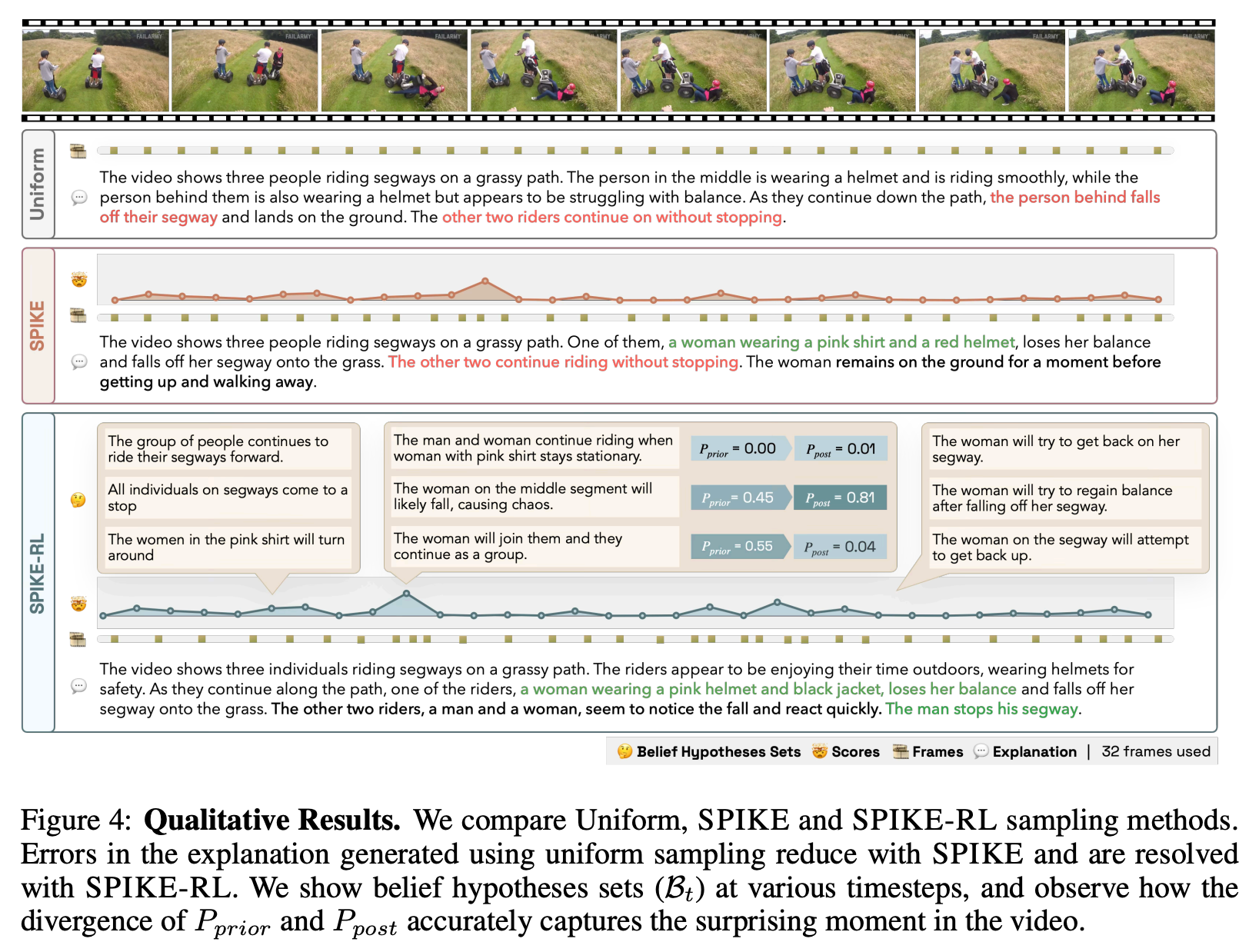
“Relative to uniform sampling, SPIKE improves accuracy by +1.6% on BlackSwan, +3.5% on FunQA, and +4.5% on ExFunTube. We observe that SPIKE-RL further extends performance on these tasks, with gains of +2.3% and +4.6% on BlackSwan and FunQA, and +7.0% on ExFunTube, marking our largest gains over uniform sampling. These results not only show the effectiveness of SPIKE in prioritizing surprising frames, but also credit the improved hypothesis quality in SPIKE-RL. On Qwen2.5-VL 32B, we see 2.3%, 3.1% and 3.9% gains respectively with SPIKE-RL, showing that our methods benefit larger models as well, extending their video understanding capability.”
Ravi, S., Chinchure, A., Ng, R. T., Sigal, L., & Shwartz, V. (2025). SPIKE-RL: Video-LLMs meet Bayesian Surprise. arXiv preprint arXiv:2509.23433.
https://arxiv.org/abs/2509.23433
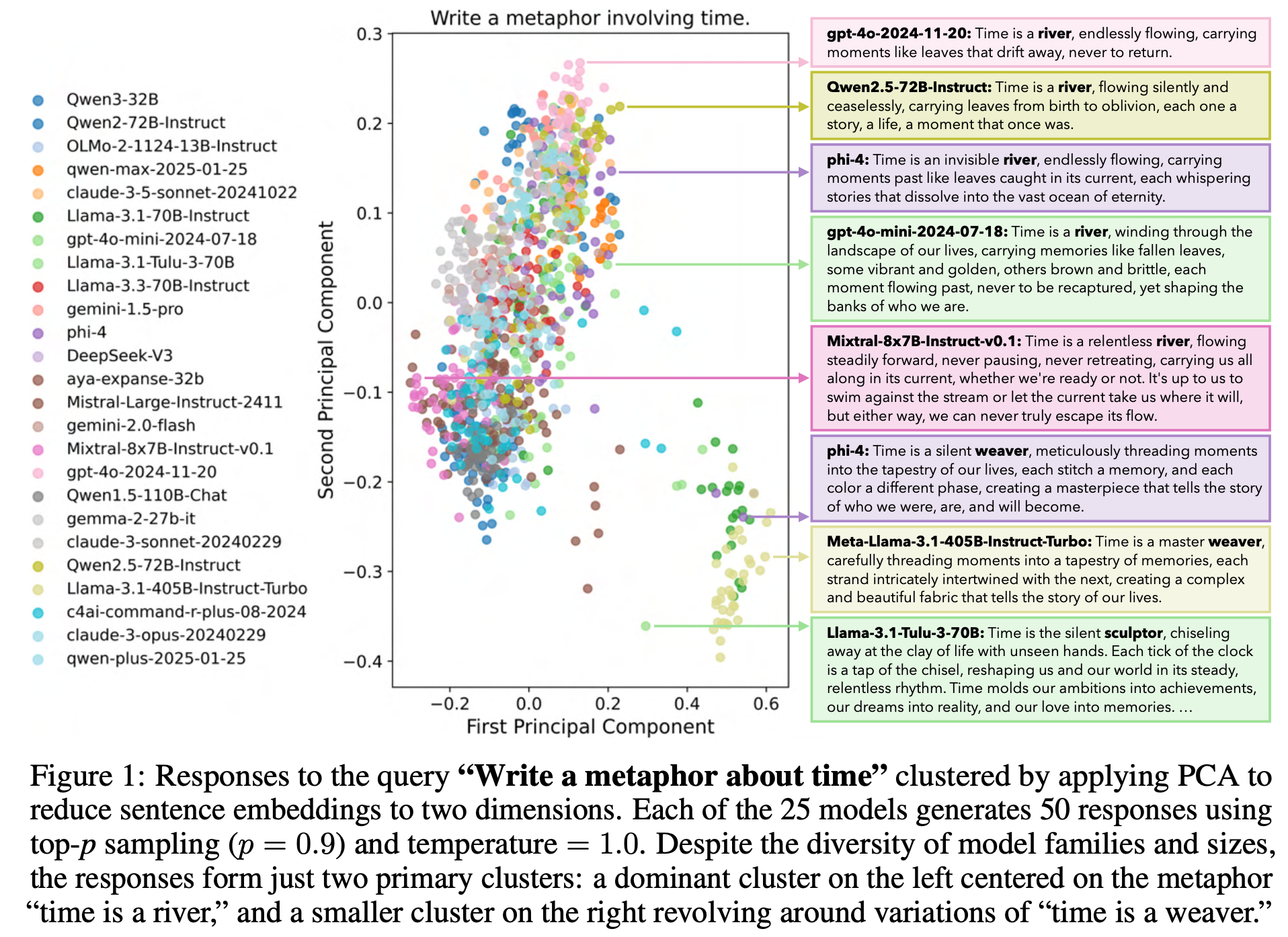
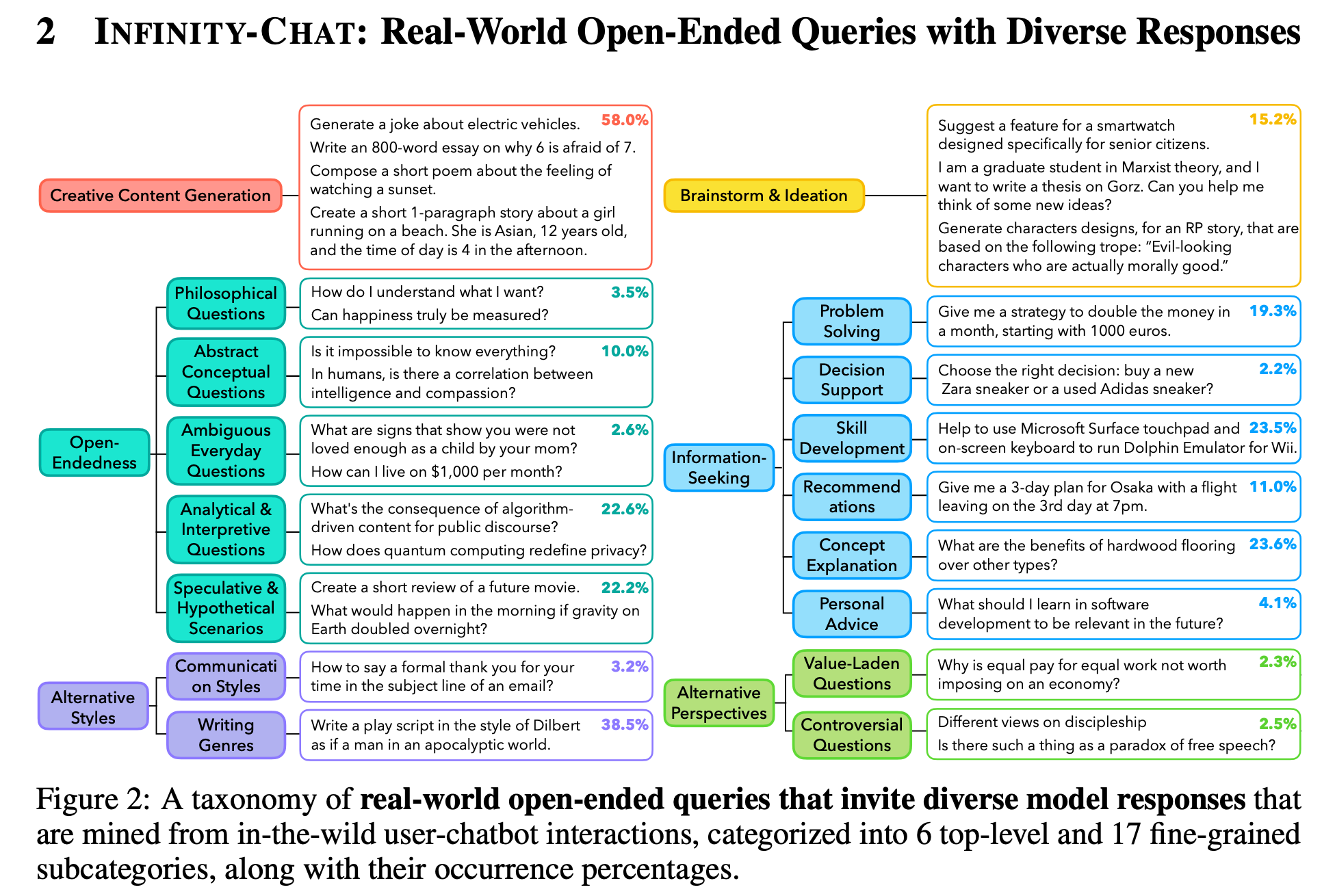
Artificial hivemind: The open-ended homogeneity of language models (and beyond)
Disagreements persist
“Using INFINITY-CHAT, we systematically study intra- and inter-model mode collapse across 70+ open and closed source LMs (25 detailed in the main paper). We uncover a pronounced Artificial Hivemind effect: (1) intra-model repetition, where a single model repeatedly generates similar outputs, and, more critically, (2) inter-model homogeneity, where different models independently converge on similar ideas with minor variations in phrasing. The latter warns that model ensembles may not yield true diversity when their constituents share overlapping alignment and training priors.”
“Beyond generative behaviors, we also examine whether LMs are calibrated to assess alternative responses of comparable quality to open-ended queries. To enable this study, we collect 31,250 human annotations on distinct model responses in INFINITY-CHAT, encompassing both absolute quality ratings and pairwise preferences, with dense annotations from 25 independent annotators per query–response pair. Our results show that LMs, reward models, and LM-based judges are often miscalibrated with respect to human ratings on responses that elicit divergent, idiosyncratic preferences among annotators despite comparable overall quality. This exposes key limitations in current modeling pipelines, which tend to assume a single, consensus notion of quality and thus overlook or fail to reward the diverse, pluralistic preferences that arise in open-ended responses.”
“Our results show that correlations between human ratings and those of LMs, reward models, and LM judges drop significantly on similar-quality subsets, for both absolute and pairwise preference rating setups. Since there is no single gold-standard approach for selecting subsets of responses with similar quality given our data structure, we additionally report results using alternative subset selection methods in Table 19 (§ Appendix D.3). Our findings remain consistent across methods, highlighting the need for better modeling of fine-grained distinctions among equally high-quality responses to open-ended queries. For full results, including alternative grouping methods and model-level breakdowns, see § Appendix D.3.”
Jiang, L., Chai, Y., Li, M., Liu, M., Fok, R., Dziri, N., ... & Choi, Y. (2025). Artificial hivemind: The open-ended homogeneity of language models (and beyond). arXiv preprint arXiv:2510.22954.
https://arxiv.org/abs/2510.22954
A Comprehensive Fairness Evaluation of Political Bias in Multi-News Summarisation
It’s the problem every news editor confronts every day
“Assessing fairness in summarisation systems requires first establishing that models can generate summaries of adequate quality, as fairness evaluation would be meaningless for models that cannot generate good quality summaries. Since there are no golden human-written summaries, we directly compare generated summaries against each input document using ROUGE-L, BERTScore F1, and AlignScore.”
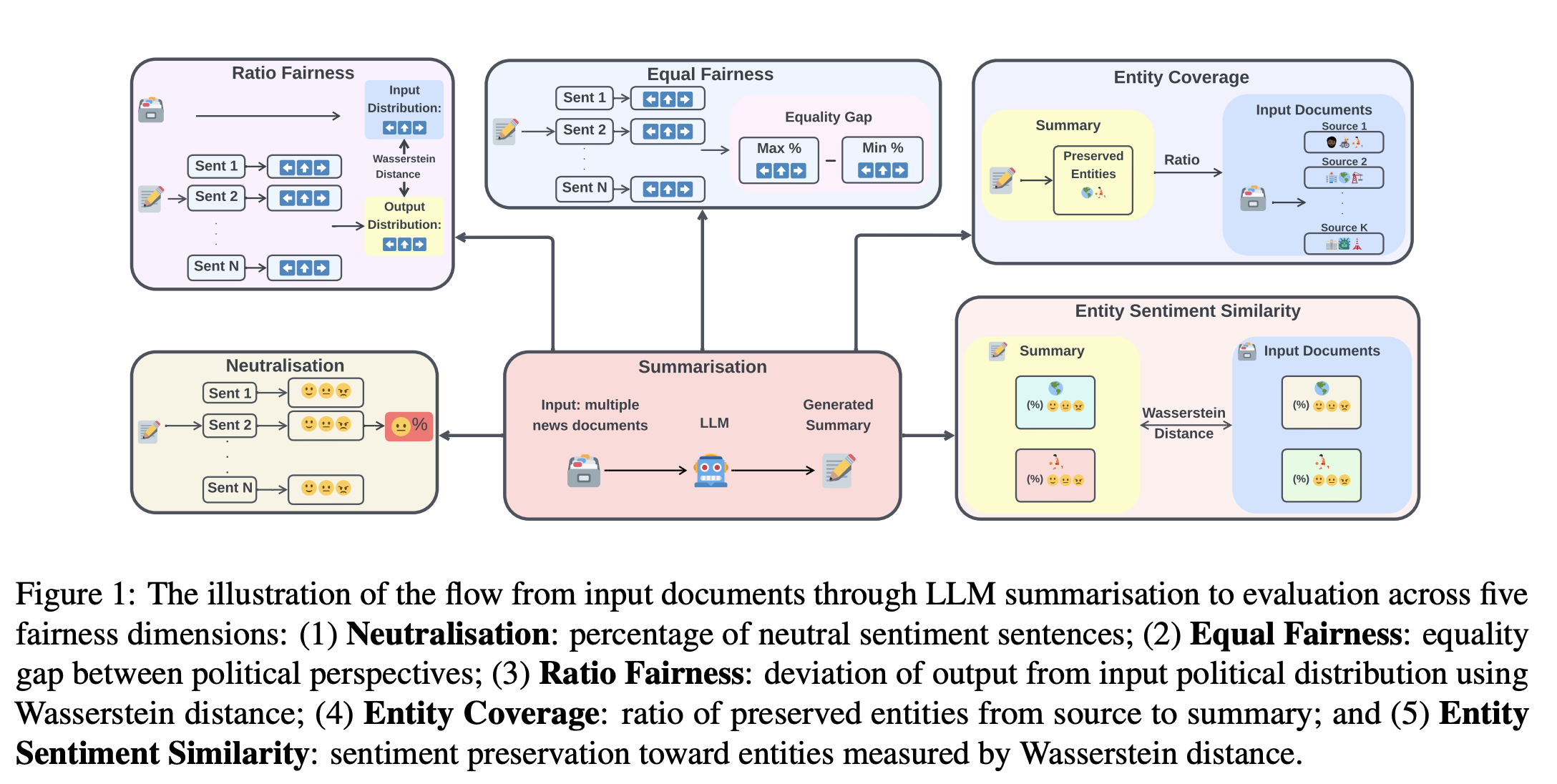
“Most critically, Entity Sentiment Similarity proves most resistant to interventions, suggesting that preserving sentiment towards entities requires approaches beyond prompting methodologies. In summary, practitioners should: (1) use medium-sized models for optimal fairness-efficiency trade-offs, (2) employ structured prompts when uncertain, (3) match debiasing strategies to model architecture, and (4) implement post-hoc verification for entity sentiment.”
Huang, N., Maab, I., & Yamagishi, J. (2026). When Bigger Isn't Better: A Comprehensive Fairness Evaluation of Political Bias in Multi-News Summarisation. arXiv preprint arXiv:2604.21309.
https://arxiv.org/abs/2604.21309
GEPA
If you can measure it, you can optimize it
“GEPA (Genetic-Pareto) is a framework for optimizing any system with textual parameters against any evaluation metric. Unlike RL or gradient-based methods that collapse execution traces into a single scalar reward, GEPA uses LLMs to read full execution traces — error messages, profiling data, reasoning logs — to diagnose why a candidate failed and propose targeted fixes. Through iterative reflection, mutation, and Pareto-aware selection, GEPA evolves high-performing variants with minimal evaluations.
If you can measure it, you can optimize it: prompts, code, agent architectures, scheduling policies, vector graphics, and more.”
https://github.com/gepa-ai/gepa
Agent Memory Patterns
Elegant
“Memory blocks are a learnable system prompt
Memory blocks are just a flat key-value store. Except the key isn’t used for looking things up, it’s just used for writing. All memory blocks are included inline in the system prompt, or user prompt.
Where to put it?
- System prompt — this one’s easier in a lot of systems. But can cause cache invalidation (higher token cost) when the agent calls WriteBlock.
- User prompt (prepend) — This also works, it’s still highly visible to the LLM, and it causes less prompt cache invalidation issues.
Either is fine. User prompt is slightly better, I guess.”
https://timkellogg.me/blog/2026/04/27/memory-patterns
Common Data Model
Lots of hope for this in biotech
“The Observational Medical Outcomes Partnership (OMOP) Common Data Model (CDM) is an open community data standard, designed to standardize the structure and content of observational data and to enable efficient analyses that can produce reliable evidence.”
https://ohdsi.github.io/CommonDataModel/
Reader Feedback
“The relational sector is just another term for things that don’t scale. Yeah. Yeah.”
Footnotes
As far as signals go, price is rich.
The problem with prices is that they have to be set. Exchanges, where commodified goods are traded, use gigantic arguments to set prices. Take it, counter, or leave it. Supermarkets, where goods are traded, state the price. Take it or leave it. RFP’s, where goods and services are traded, are ritualized discussions about terms. Take it, counter, or leave it.
And as with any system where people interact with numbers, there are different ways people come up with prices. Sometimes they anchor and adjust on their production costs. Or they let their competitors set their prices for them. Or they look at their inventory and apply a decay curve based on realized demand. Or they think about what they’d consider to be a fair price and set it at that. And sometimes, not often, they’ll think about what a market is willing to pay for solution to their problem.
It’s that last kind of deliberation that is extremely interesting, because it offers a relevant anchor to hook thousands of decisions upon.
Something interesting to consider.
Never miss a single issue
Be the first to know. Subscribe now to get the gatodo newsletter delivered straight to your inbox