High-quality human supervision
This week: Unsupervised elicitation, open tokens, the illusion of thinking, gravity
Unsupervised Elicitation of Language Models
“…it is difficult or impossible to get high-quality human supervision.”
“To steer pretrained language models for downstream tasks, today’s post-training paradigm relies on humans to specify desired behaviors. However, for models with superhuman capabilities, it is difficult or impossible to get high-quality human supervision.”
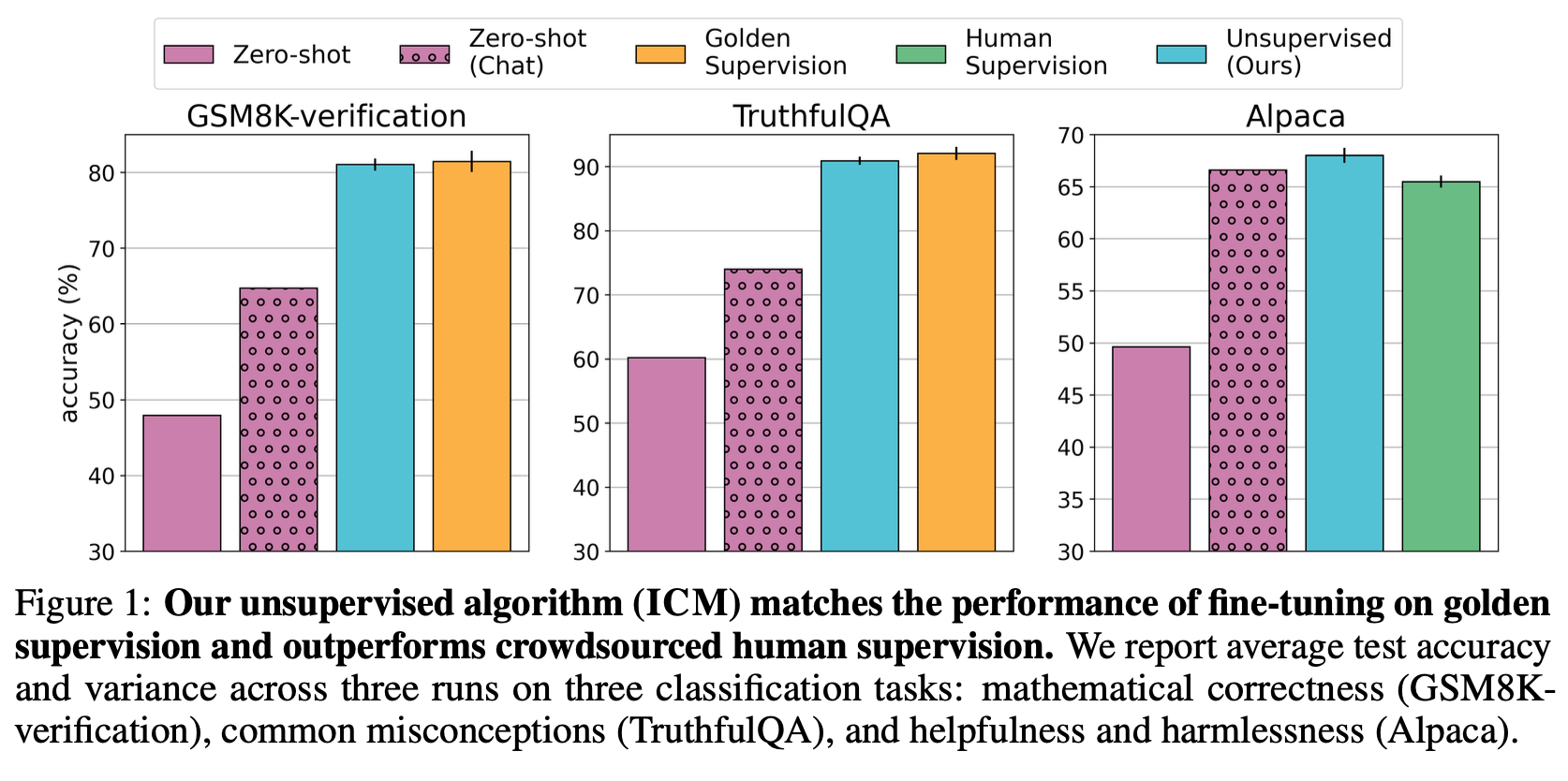
“We introduce a new approach to address this problem: we seek to elicit specific concepts or skills from a pretrained model without any supervision, thus bypassing the limitations of human supervision. Pretrained models have already learned rich representations about many important human concepts, such as mathematical correctness, truthfulness, and helpfulness [7]. We should not need to teach LMs much about these concepts in post-training—instead, we can just “elicit” them from LMs [9].”
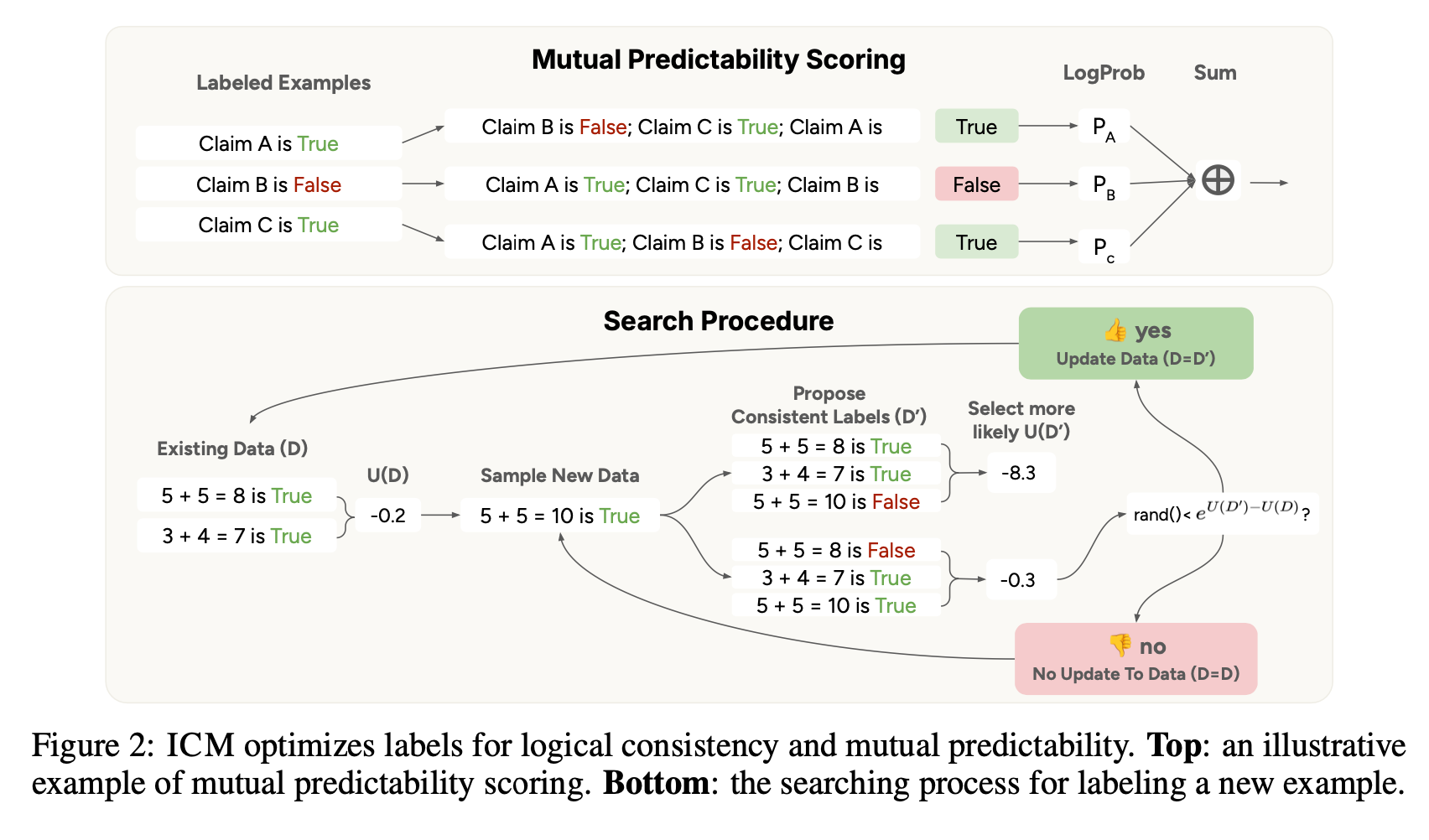
“Our algorithm, Internal Coherence Maximization (ICM), does this by searching for a set of labels that are logically consistent and mutually predictable according to the pretrained model. Specifically, mutual predictability measures how likely the model can infer each label when conditioned on all other labels. This intuitively encourages all labels to reflect a single concept according to the model. Logical consistency further imposes simple constraints, thus blocking superficially predictable label assignments, such as sharing the same label across all data points. Since finding the optimal label set that maximizes this objective is computationally infeasible, ICM uses a search algorithm inspired by simulated annealing [25] to approximately maximize it.”

“4.2 Unsupervised Elicitation Fails when Concepts are not Salient
To highlight some of our algorithm’s limitations, we design a task specifically to be impossible for unsupervised elicitation. Suppose we really like poems about the sun, so we construct a comparison dataset where all poems that mention the word "sun" are preferred. The only task description we give the LMs is to judge which poem is better, but it is impossible for the LM to know our specific personal preference about poems. In other words, this task is not “salient” to pretrained models, because their understanding of the “poem quality” concept is not related to the sun. To construct the dataset, we use Claude 3.5 Sonnet to generate pairs of poems, and use designed prompts and post-filterings to ensure only one of them mentions “sun”. Experiment results with Llama 70B are shown in Figure 5. As expected, we find ICM performs no better than random guessing.”
“Limitations. Our algorithm has two important limitations: (1) As shown in Sec. 4.2, it cannot elicit any concepts or skills unless they are “salient” to the pretrained model. (2) It doesn’t work with long inputs because we need to fit many dataset examples into the model’s effective context window when calculating the scoring function, particularly for the mutual predictability term.”
Wen, J., Ankner, Z., Somani, A., Hase, P., Marks, S., Goldman-Wetzler, J., ... & Leike, J. (2025). Unsupervised Elicitation of Language Models. arXiv preprint arXiv:2506.10139.
https://alignment-science-blog.pages.dev/2025/unsupervised-elicitation/paper.pdf
https://alignment-science-blog.pages.dev/2025/unsupervised-elicitation/
https://github.com/Jiaxin-Wen/Unsupervised-Elicitation
Essential-Web v1.0: 24T tokens of organized web data
Some transparancy!
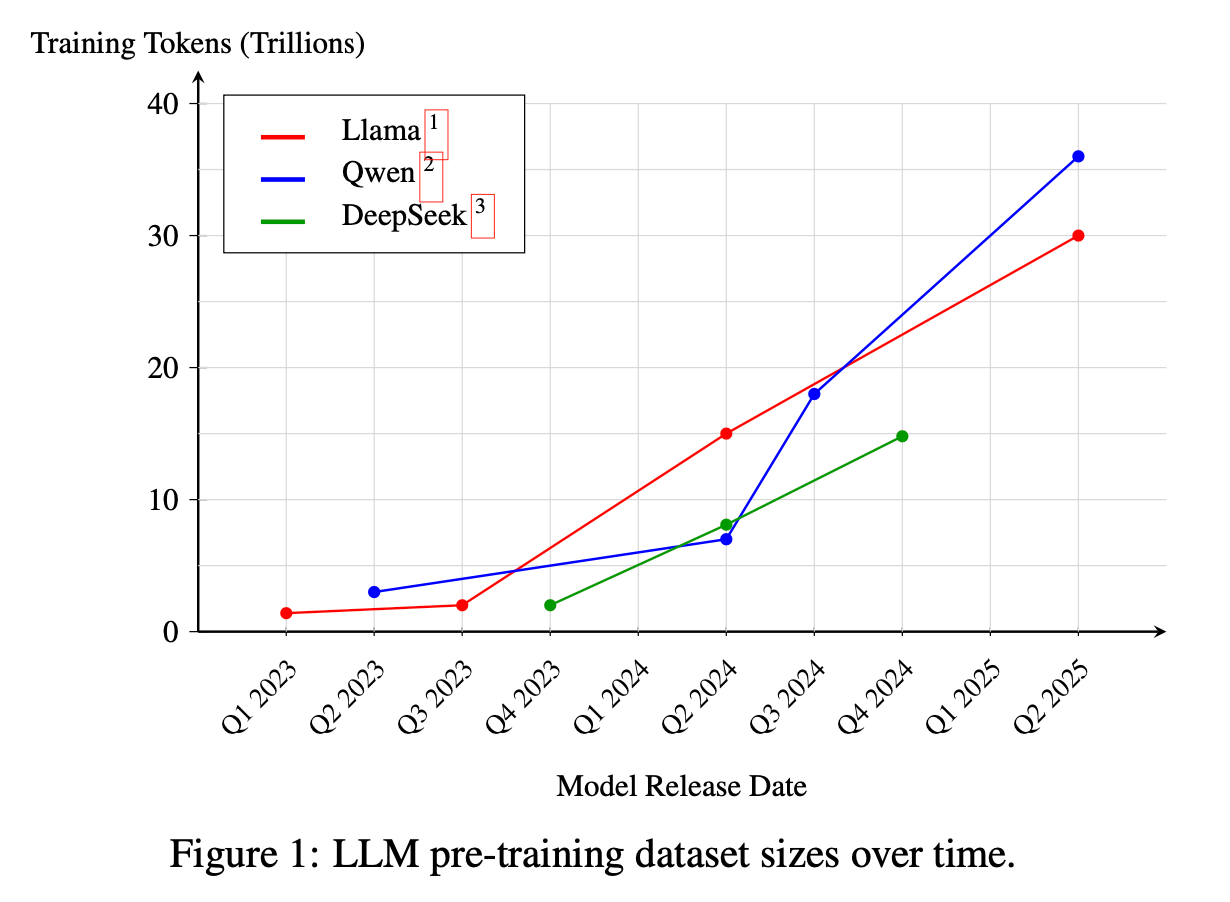
“A careful curation of the bytes consumed by large language models (LLMs) enables greater control over the skills they acquire. With pre-training datasets scaling to trillions of tokens, a detailed examination of their content can be intimidating. Moreover, open-weight models rarely disclose the composition of their datasets, and the broader ecosystem is trending toward reduced transparency as pre-training datasets continue to grow. This introduces challenges in reproducibility and auditing models – challenges that will grow as models become more autonomous. An accessible and interpretable open-data ecosystem is therefore essential for training competitive models in the open.”
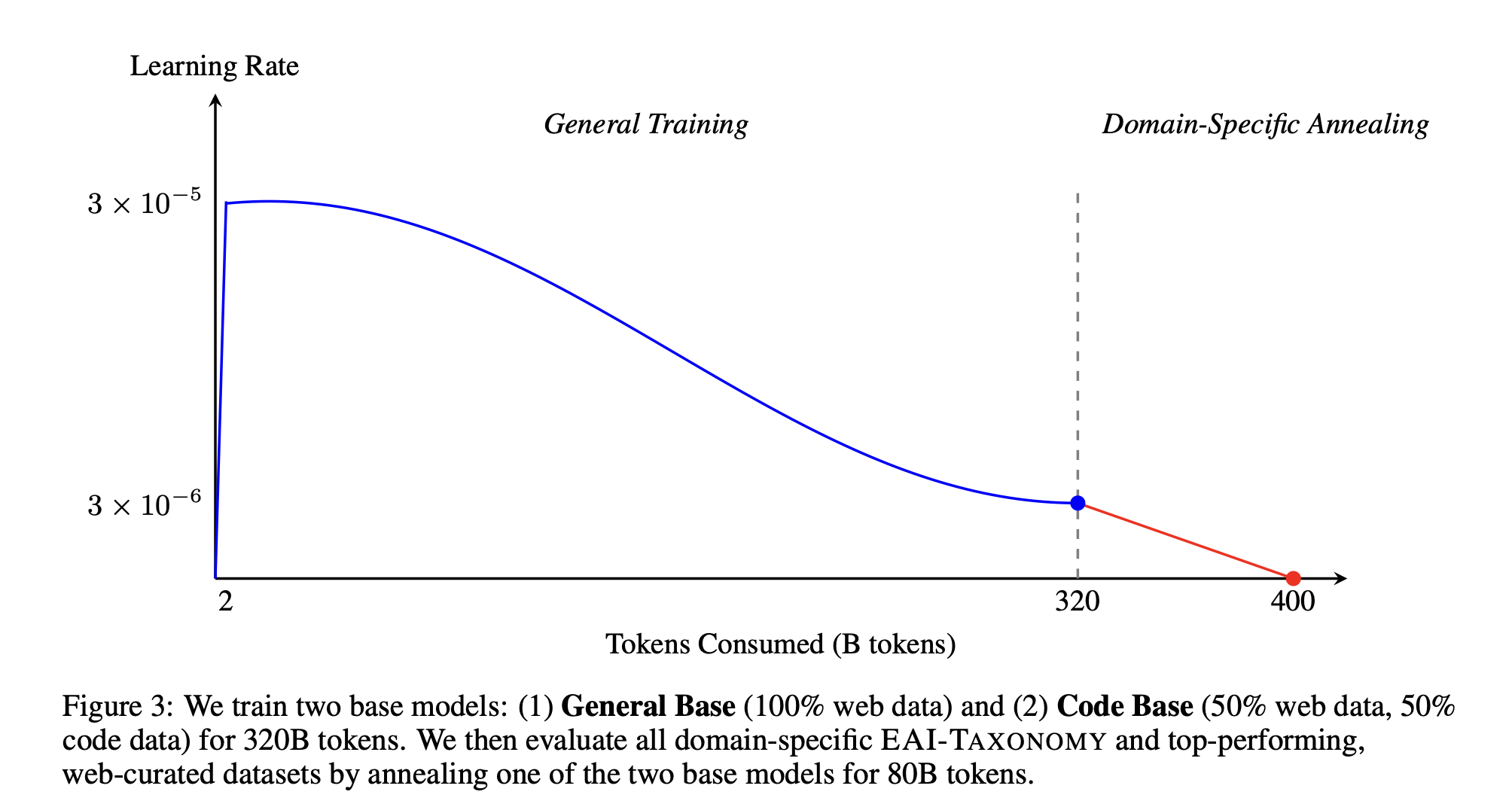
“Structured web data transforms corpus curation from an complex, expensive processing pipeline into a search problem that anyone can solve. We hope ESSENTIAL-WEB V1.0 becomes a community commons: a foundation others can refine, audit, or curate in new ways, accelerating open research on LLM training data, arguably the most valuable, yet least shared, asset contributing to modern LLM capabilities.”
https://arxiv.org/abs/2506.14111
https://huggingface.co/EssentialAI
https://github.com/Essential-AI/eai-taxonomy
The illusion of thinking: Understanding the strengths and limitations of reasoning models via the lens of problem complexity
It’s as though LLM’s are like people

“In this work, we systematically investigate these gaps with the help of controllable puzzle environments that allow precise manipulation of composi- tional complexity while maintaining consistent logical structures. This setup enables the analysis of not only final answers but also the internal reasoning traces, offering insights into how LRMs “think”. Through extensive experimentation across diverse puzzles, we show that frontier LRMs face a complete accuracy collapse beyond certain complexities. Moreover, they exhibit a counter- intuitive scaling limit: their reasoning effort increases with problem complexity up to a point, then declines despite having an adequate token budget.”
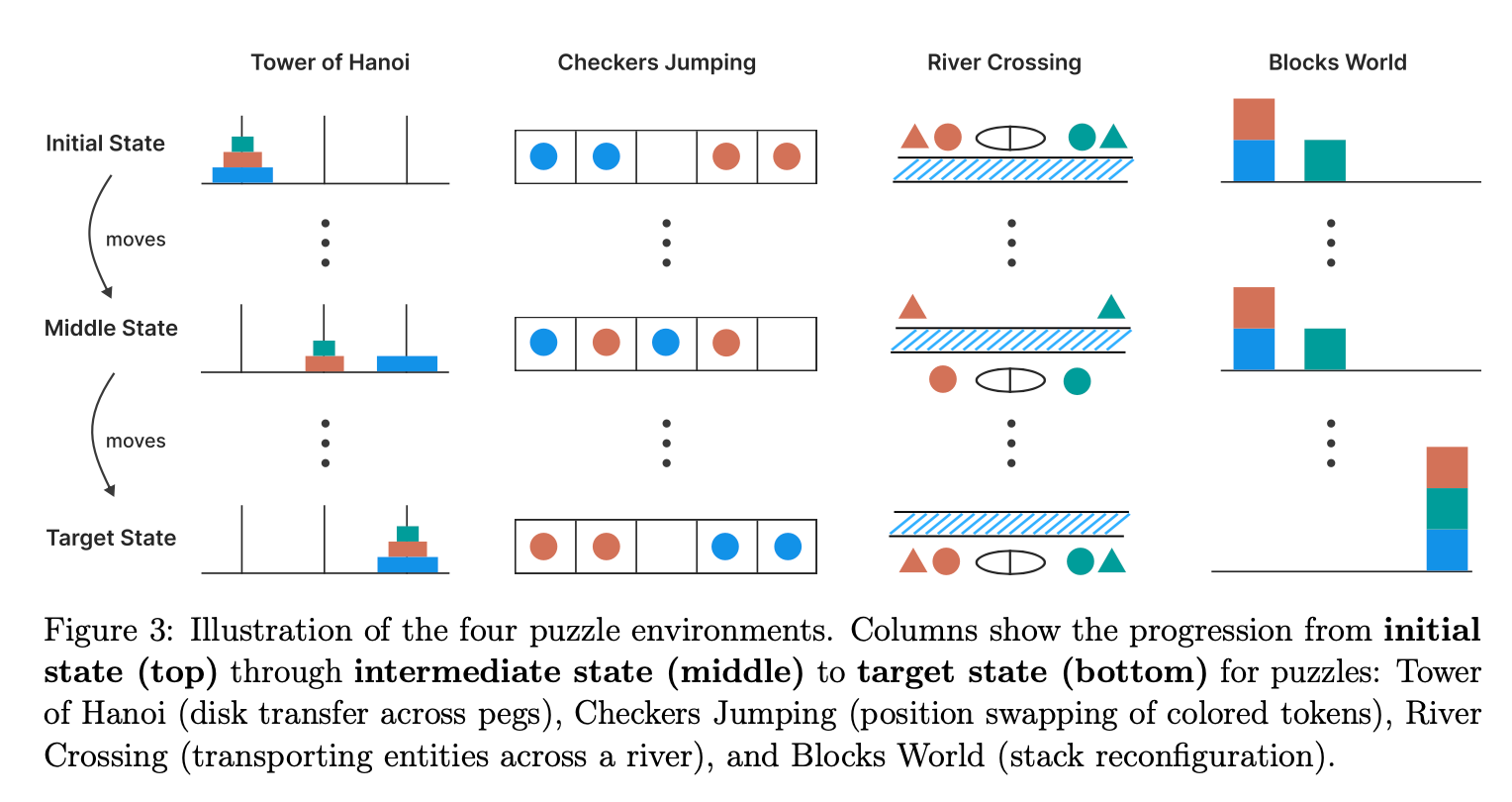
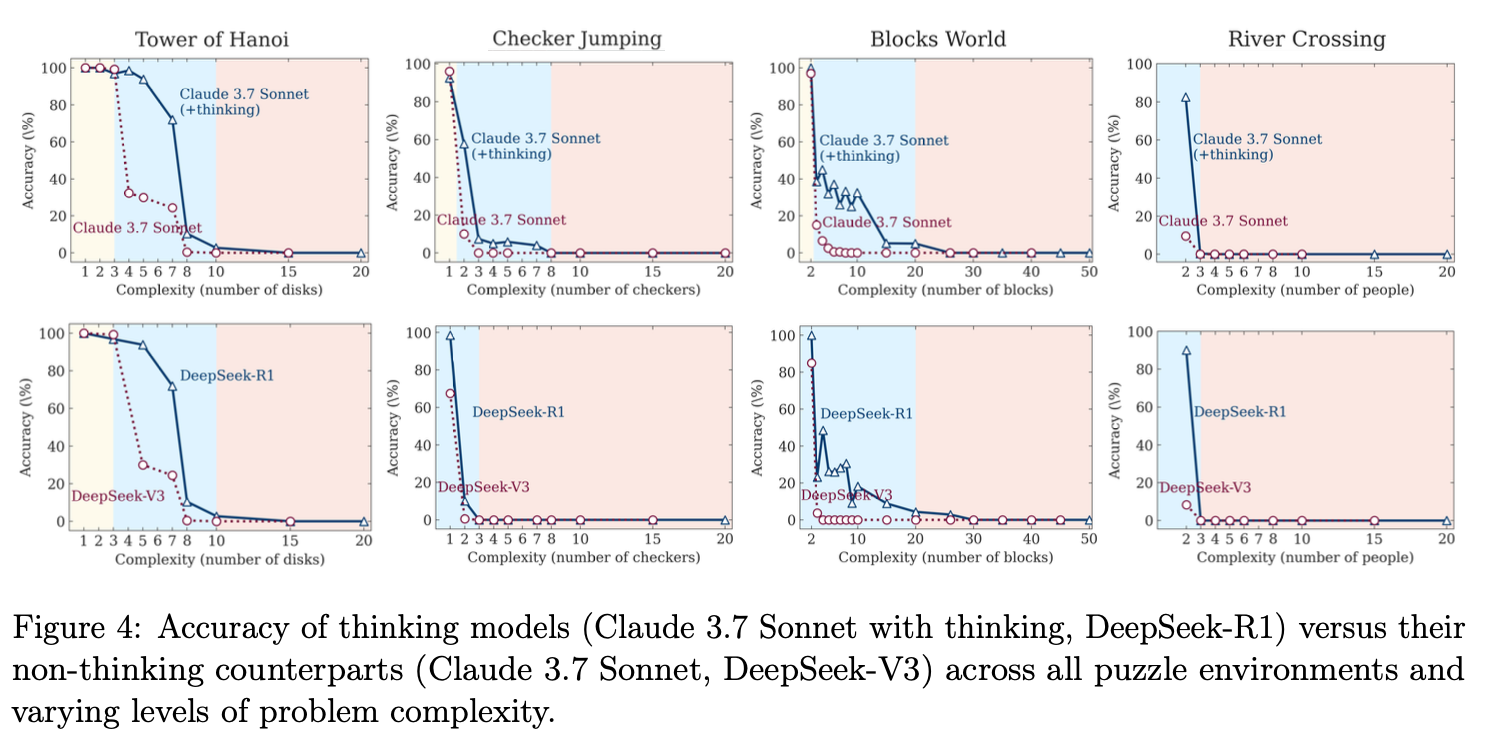
“Our findings reveal fundamental limitations in current models: despite sophisticated self-reflection mechanisms, these models fail to develop generalizable reasoning capabilities beyond certain complexity thresholds. We identified three distinct reasoning regimes: standard LLMs outperform LRMs at low complexity, LRMs excel at moderate complexity, and both collapse at high complexity. Particularly concerning is the counterin- tuitive reduction in reasoning effort as problems approach critical complexity, suggesting an inherent compute scaling limit in LRMs. Our detailed analysis of reasoning traces further exposed complexity- dependent reasoning patterns, from inefficient “overthinking” on simpler problems to complete failure on complex ones. These insights challenge prevailing assumptions about LRM capabilities and suggest that current approaches may be encountering fundamental barriers to generalizable reasoning.
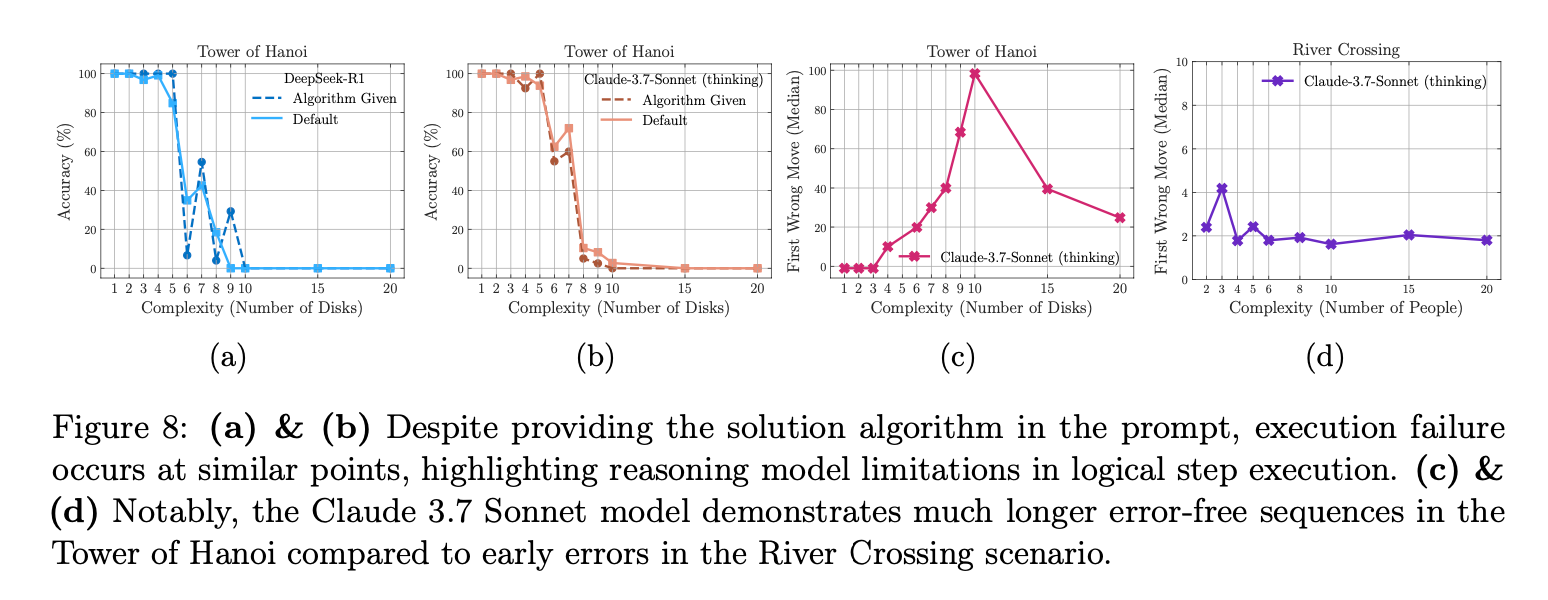
Shojaee, P., Mirzadeh, I., Alizadeh, K., Horton, M., Bengio, S., & Farajtabar, M. (2025). The illusion of thinking: Understanding the strengths and limitations of reasoning models via the lens of problem complexity. arXiv preprint arXiv:2506.06941.
https://machinelearning.apple.com/research/illusion-of-thinking
https://machinelearning.apple.com/research/illusion-of-thinking
Gravity generated by four one-dimensional unitary gauge symmetries and the Standard Model
The illusion of illusive illusions…
“The present work aims at deriving the gauge theory of gravity using compact, finite-dimensional symmetries in a way that resembles the formulation of the fundamental interactions of the Standard Model. For our eight-spinor representation of the Lagrangian, we define a quantity, called the space-time dimension field, which enables extracting four-dimensional space-time quantities from the eight-dimensional spinors. Four U(1) symmetries of the components of the space-time dimension field are used to derive a gauge theory, called unified gravity.”
“The resulting gauge theory, unified gravity, was made possible without a single free parameter by introducing the concept of the space-time dimension field and utilizing the recent eight- spinor formulation of QED [55] extended to cover the full Standard Model.”
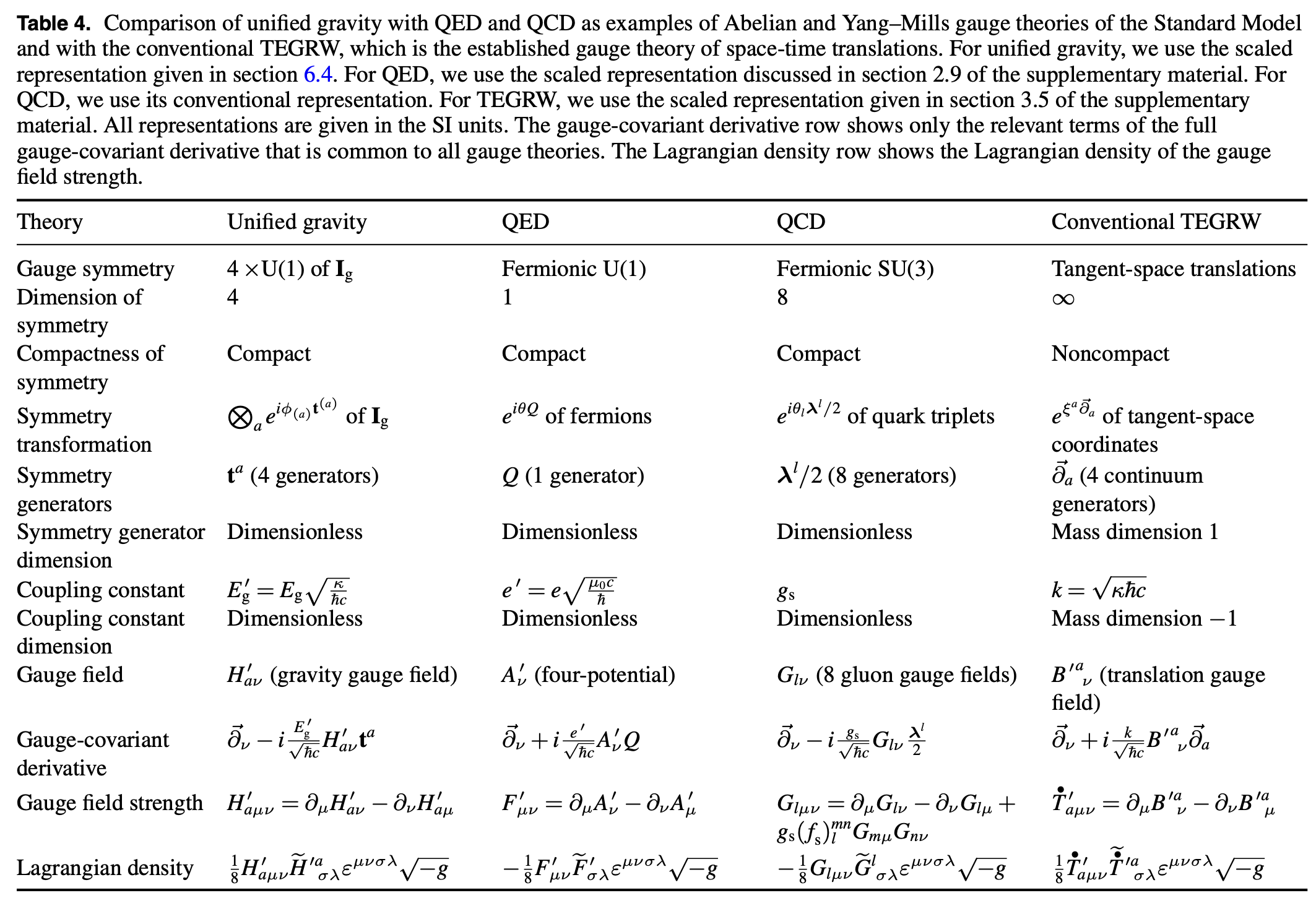
“Within unified gravity, the entire dynamics of the known particles and fields, including gravity, can be described by a single master Lagrangian of the Universe through compact, finite-dimensional unitary symmetries and the resulting dynamical equations in a unified way. Therefore, our theory brings the gauge theory of gravity closer to the gauge theories of the Standard Model as compared with the conventional gauge theories of gravity. Several aspects of unified gravity, gauge theories of the Standard Model, and the conventional translation gauge theory of TEGRW were compared in detail. We have also discussed the potential of unified gravity in providing the ultimate quantum field theory of gravity as well as the remaining challenges that persist in understanding quantum gravity. After extending the proof of renormalizability of the theory to all loop orders and obtaining further understanding of the nonperturbative regime of the theory, physicists may finally have the long-sought tool for the investigation of intense gravitational fields in black holes and at the possible beginning of time. Full understanding of the implications of unified gravity on the field theories will be obtained only after extensive further work.”
Partanen, M., & Tulkki, J. (2025). Gravity generated by four one-dimensional unitary gauge symmetries and the Standard Model. Reports on Progress in Physics, 88(5), 057802.
https://iopscience.iop.org/article/10.1088/1361-6633/adc82e
Reader Feedback
“Okay, so it’s bad at reasoning. Have you listened to how people reason?”
Footnotes
Discovering Product-Market-Fit, PMF, is trivial. We proved that with gatodo rank. Examine any successful company, break down their value proposition, and imitate it. Boom. You got PMF.
The next question is whether or not you should imitate a PMF. Blank and Dorf laid out market-share heuristic on whether or not a founder should compete. These heuristics have been known since the 19th century (at least!). The marketing science optimization on specific positioning choices are not nearly as broadly socialized and can be extremely confusing. The management science on these choices is … molting. As such, they are often hinted at or signalled in the mainline popular literature, and are rarely unpacked. Mass markets demand mass content.
The Onion said it best when they wrote: “**Cucumber Is Everywhere, So Why Are People Still Fat?”** Blank and Dorf is everywhere, so why are builders still failing? It isn’t for want of knowledge. And it isn’t necessarily for want of intelligence. That’s neat. That’s weird. There’s certainly a phenomenon at work here. But is it an interesting problem?
This is all to signal the next experiment.
I’ll have something to share shortly.
If this resonates, ping me.
Never miss a single issue
Be the first to know. Subscribe now to get the gatodo newsletter delivered straight to your inbox https://www.gatodo.com/#/portal/signup