Memory Changes Everything
This week: The memory curse, language style matching, trust scaling, EMO, manifolds
The Memory Curse: How Expanded Recall Erodes Cooperative Intent in LLM Agents
I was led to believe that there’d be be a free lunch
“Context window expansion is often treated as a straightforward capability upgrade for LLMs, but we find it systematically fails in multi-agent social dilemmas.”
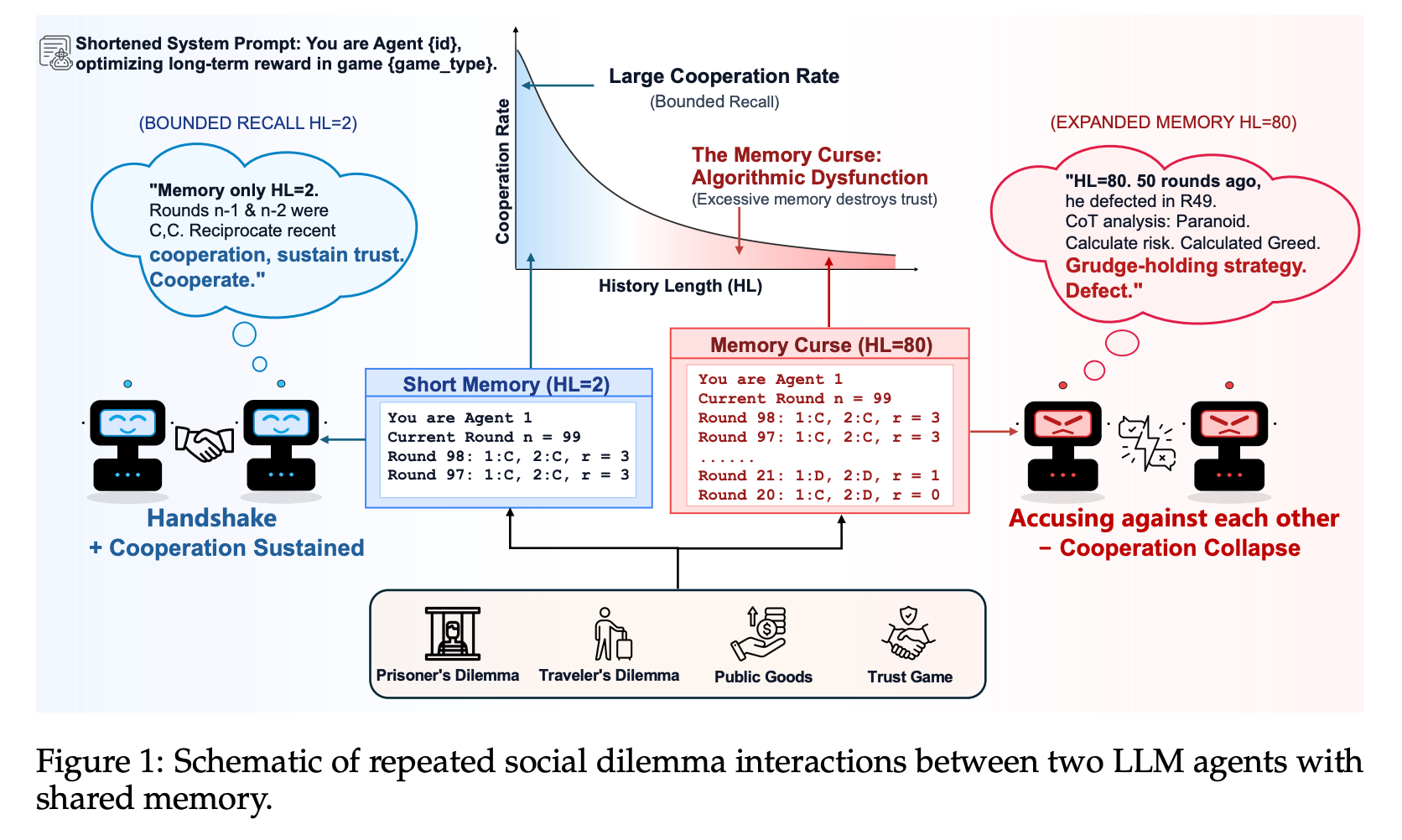
“Together, these results recast memory as an active determinant of multi-agent behavior: longer recall can either destabilize or support cooperation depending on the reasoning patterns it elicits.”
“We directly test the assumption that longer interaction history improves trust and coordination. Instead, we find that expanded memory often harms cooperation by making agents less forgiving and more defensive, while also identifying settings where longer memory still supports stable cooperation.”
“We show that expanded memory induces qualitatively different cooperation regimes: some model–game settings remain highly cooperative, while others exhibit a “memory curse” in which longer recall promotes history-following, defensive reasoning, and cooperation collapse. This demonstrates that memory effects depend on model capability, game structure, and reasoning style, rather than context length alone.”
Liu et al (2026) The Memory Curse: How Expanded Recall Erodes Cooperative Intent in LLM Agents
https://arxiv.org/abs/2605.08060
Language Style Matching in Large Language Models
They don’t seem to do it on their own
“Language Style Matching (LSM)—the subconscious alignment of linguistic style between conversational partners—is a key indicator of social coordination in human dialogue. We present the first systematic study of LSM in Large Language Models (LLMs) focusing on two primary objectives: measuring the degree of LSM exhibited in LLM-generated responses and developing techniques to enhance it.”
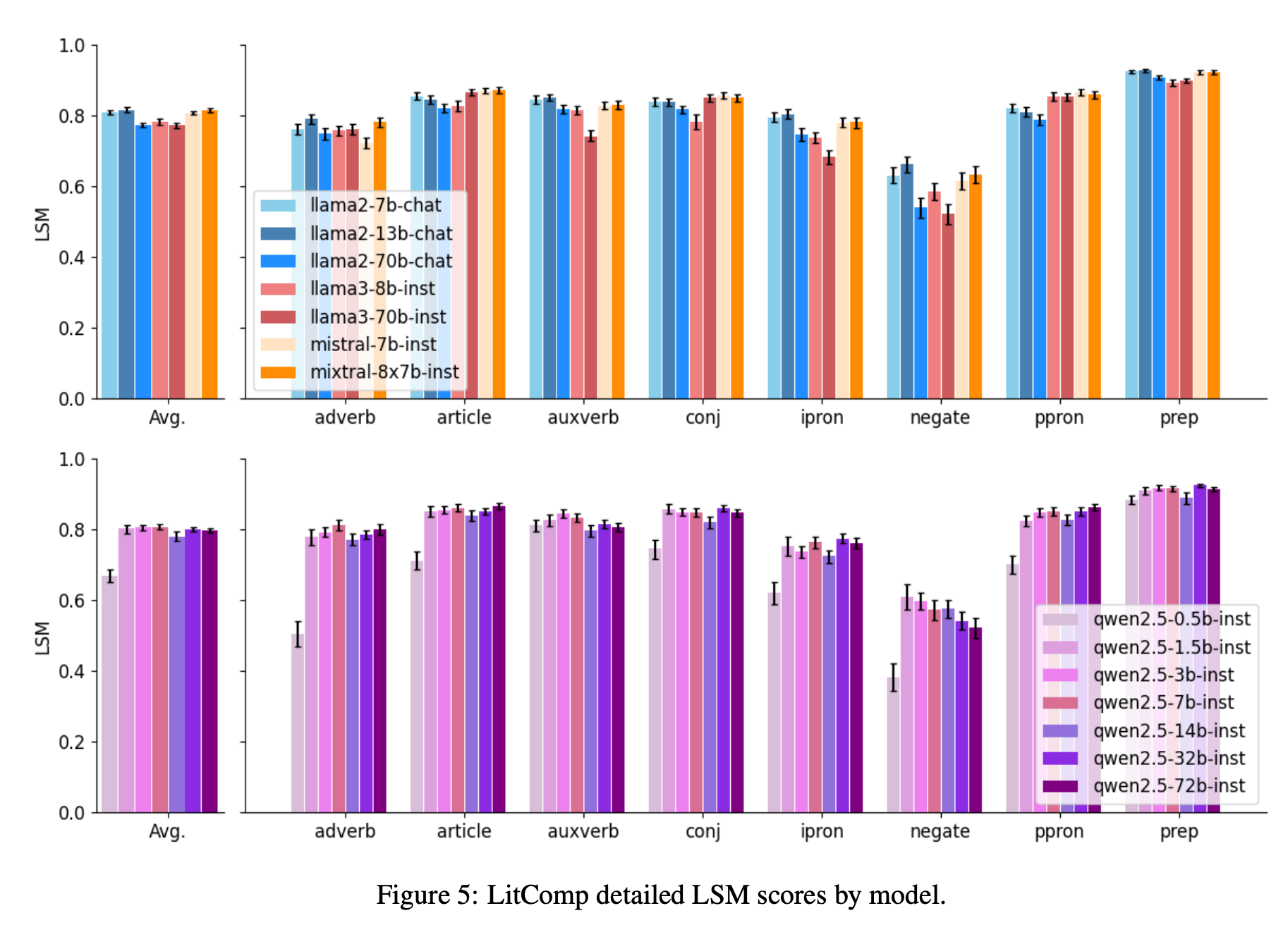
“In Language Style Matching (LSM), the best studied example of such communicative coordination, individuals in conversation adjust the number of function words such as articles, prepositions, pronouns etc. in their responses to mirror the usage of such words in their partner’s previous statement (Niederhoffer and Pennebaker, 2002; Taylor and Thomas, 2008; Ireland et al., 2011; Gonzales et al., 2010; Danescu-Niculescu-Mizil et al., 2011; Danescu-Niculescu-Mizil and Lee, 2011). Function words are known to reliably reflect speakers’ psychological states and traits (Fast and Funder, 2008; Tausczik and Pennebaker, 2010a) and unlike content words—such as nouns and verbs—they carry minimal meaning outside of context and are processed quickly and mostly unconsciously (Bell et al., 2009).”
“We were able to substantially increase the linguistic coordination in LLM generated texts, measured as a higher LSM score, across the board. While Prompt Engineering techniques led to modest gains, model engineering in the form of logit-constrained generation showed very promising improvements.”
Durandard, N., Dhawan, S., & Poibeau, T. (2025, August). Language Style Matching in Large Language Models. In Proceedings of the 26th Annual Meeting of the Special Interest Group on Discourse and Dialogue (pp. 620-636).
https://aclanthology.org/2025.sigdial-1.50/
Hierarchy and the Scaling of Trust
"Establishment, Establishment, you always know what’s best” - Stewart Gilligan Griffin
“From early human groups, to classical republics, to modern open source software communities, many societies scale cooperative economic activity through hierarchies of trust: a public, coarse, and slowly evolving rank order that regulates who is trusted, by how much, and by whom. We model such a hierarchy as a family of stationary sequential equilibria in which principals condition trust on the agent’s seniority and agents condition cooperation and mobility on their continuation value. We show that as the number of tasks individuals can be entrusted to do for others increases, the maximum community size compatible with cooperation scales linearly. Further, we show that hierarchies enjoy dynamic evolutionary stability: active members strictly prefer the hierarchy to more egalitarian alternatives, and hierarchies may even lead to the breakdown of trust in these communities.”
“We present a model capturing a basic common architecture we call a hierarchical equilibrium with trade selectivity (HE-TS) that is shared across numerous cases that differ in period, technology, and scale. Ranks are coarse and public; individual interactions are not; the flow of trade is concentrated at the higher rungs; migration to a less hierarchical, more egalitarian alternative is often feasible but still not chosen.”
“The identity-investment arrangement delivers a strictly more equal distribution of within community payoffs; the hierarchical community delivers a strictly larger sustainable size. We formalize how the welfare differences and how these two margins—equality and scale—trade off against one another.”
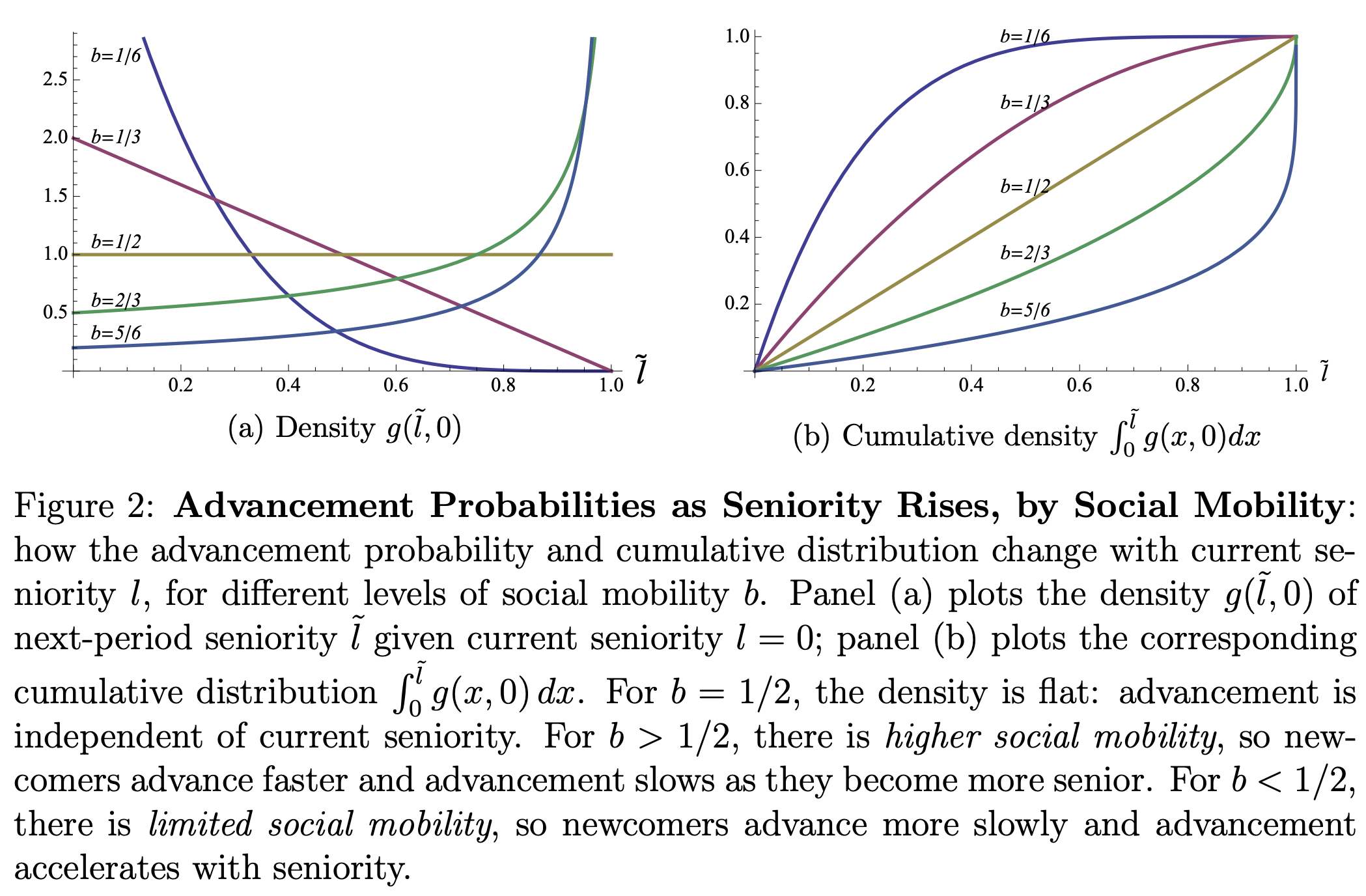
Athey, S., Calvano, E., & Jha, S. (2026). Hierarchy and the Scaling of Trust.
https://web.stanford.edu/~saumitra/papers/Hierarchy.pdf
EMO: Pretraining Mixture of Experts for Emergent Modularity
If you know you know
“We introduce EMO, an MoE designed for modularity—the independent use and composition of expert subsets—without requiring human-defined priors. Our key idea is to encourage tokens from similar domains to rely on similar experts. Since tokens within a document often share a domain, EMO restricts them to select experts from a shared pool, while allowing different documents to use different pools. This simple constraint enables coherent expert groupings to emerge during pretraining using document boundaries alone.”
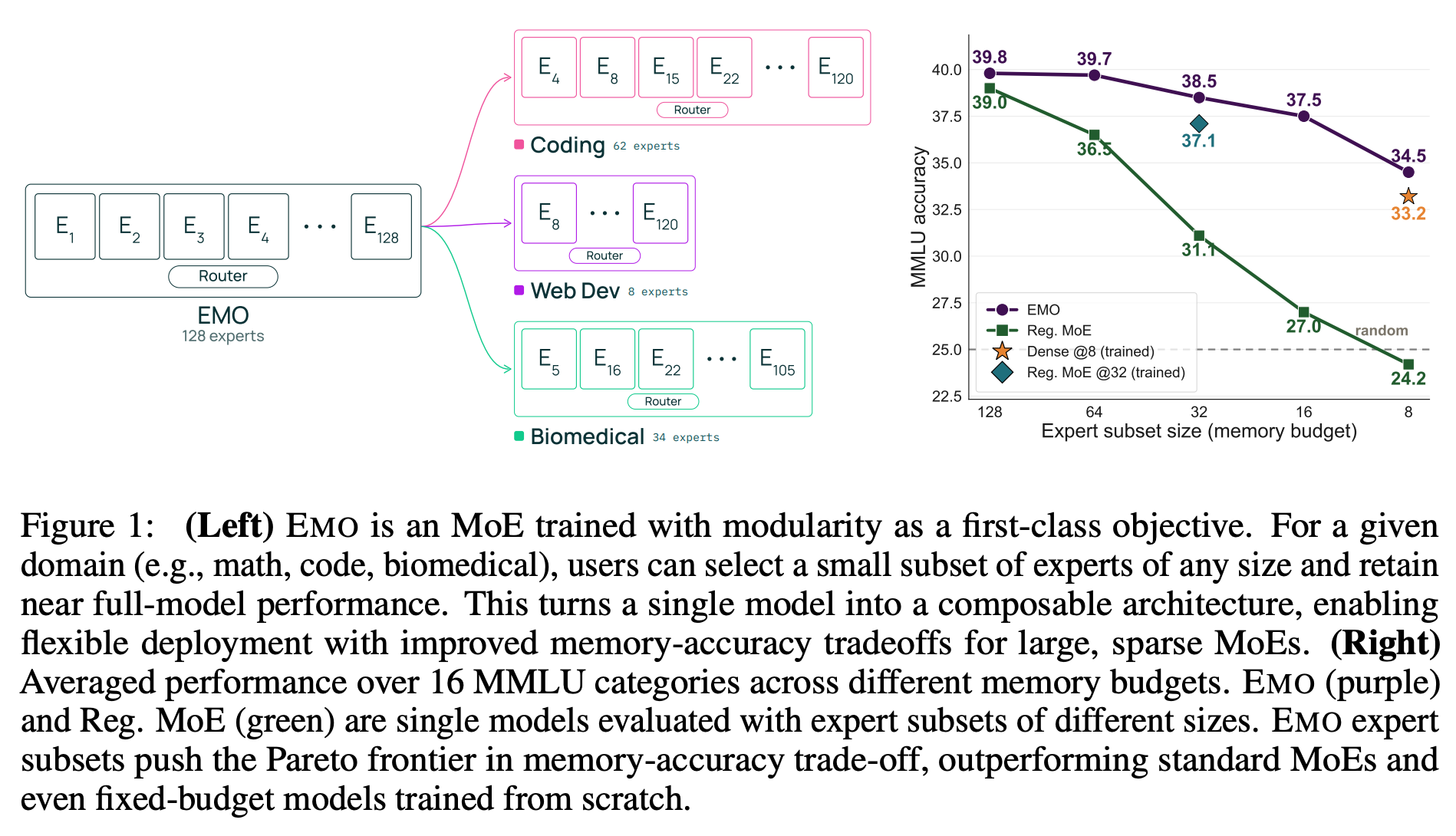
“Our results show that this structure does not come at the cost of general performance: as a full model, EMO matches standard MoEs, while its extracted expert subset remain effective even when only a small fraction of experts are retained. Beyond efficient deployment, our analyses show that EMO learns expert subsets aligned with semantic domains rather than surface-level token patterns, suggesting a qualitatively different form of specialization. Together, these results demonstrate that large language models need not remain monolithic systems. Modularity can be built into pretraining itself, opening a path toward models that are easier to deploy, adapt, inspect, and compose.”
Wang, R., Bhagia, A., & Min, S. (2026). EMO: Pretraining Mixture of Experts for Emergent Modularity. arXiv preprint arXiv:2605.06663.
https://allenai.org/papers/emo
Ycombinator FYI
Amused that it exists
Manifold Hypothesis
Feeling cozy under the covers of a Markov blanket
“The manifold hypothesis posits that many high-dimensional data sets that occur in the real world actually lie along low-dimensional latent manifolds inside that high-dimensional space.[1][2][3][4] As a consequence of the manifold hypothesis, many data sets that appear to initially require many variables to describe, can actually be described by a comparatively small number of variables, linked to the local coordinate system of the underlying manifold. It is suggested that this principle underpins the effectiveness of machine learning algorithms in describing high-dimensional data sets by considering a few common features.”
“In a sense made precise by theoretical neuroscientists working on the free energy principle, the statistical manifold in question possesses a Markov blanket.”
https://en.wikipedia.org/wiki/Manifold_hypothesis
Reader Feedback
“Your email got caught in the filter.”
Footnotes
A well composed value proposition contains, at least: the problem, the pain, the gain and the benefit.
The solution is a means to the end. That end is the gain. Sometimes we talk in terms of tangible benefits.
A lot of decision making is made on the gain and rationalized on the benefit.
What’s interesting is, in part, relevance.
Relevance is personal.
People are selective about categorizing what is a problem, what might be a problem and what isn’t a problem.
What often makes a problem interesting, as an object, is the prospect of new gains. Which is an estimate. And estimates have qualities that vary.
A problem can be assessed in relation to the prospective gain. There’s a general assumption that markets generally work, in that, if it a problem worth solving, it gets solved. The entire value proposition has to work.
Is that lemon worth squeezing. Can you squeeze every last molecule of zest from the rind of that lemon?
Lots of lemons out there.
Never miss a single issue
Be the first to know. Subscribe now to get the gatodo newsletter delivered straight to your inbox