Prometheus Builds a Twin
This week: Power-Seeking AI, Registry, biological data, self-evalution
Is Power-Seeking AI an Existential Risk?
Hold on there Prometheus
“On this picture, intelligent agency is an extremely powerful force, and creating agents much more intelligent than us is playing with fire – especially given that if their objectives are problematic, such agents would plausibly have instrumental incentives to seek power over humans. Second, I formulate and evaluate a more specific six-premise argument that creating agents of this kind will lead to existential catastrophe by 2070. On this argument, by 2070: (1) it will become possible and financially feasible to build relevantly powerful and agentic AI systems; (2) there will be strong incentives to do so; (3) it will be much harder to build aligned (and relevantly powerful/agentic) AI systems than to build misaligned (and relevantly powerful/agentic) AI systems that are still superficially attractive to deploy; (4) some such misaligned systems will seek power over humans in high-impact ways; (5) this problem will scale to the full disempowerment of humanity; and (6) such disempowerment will constitute an existential catastrophe. I assign rough subjective credences to the premises in this argument, and I end up with an overall estimate of ~5% that an existential catastrophe of this kind will occur by 2070. (May 2022 update: since making this report public in April 2021, my estimate here has gone up, and is now at >10%.).”
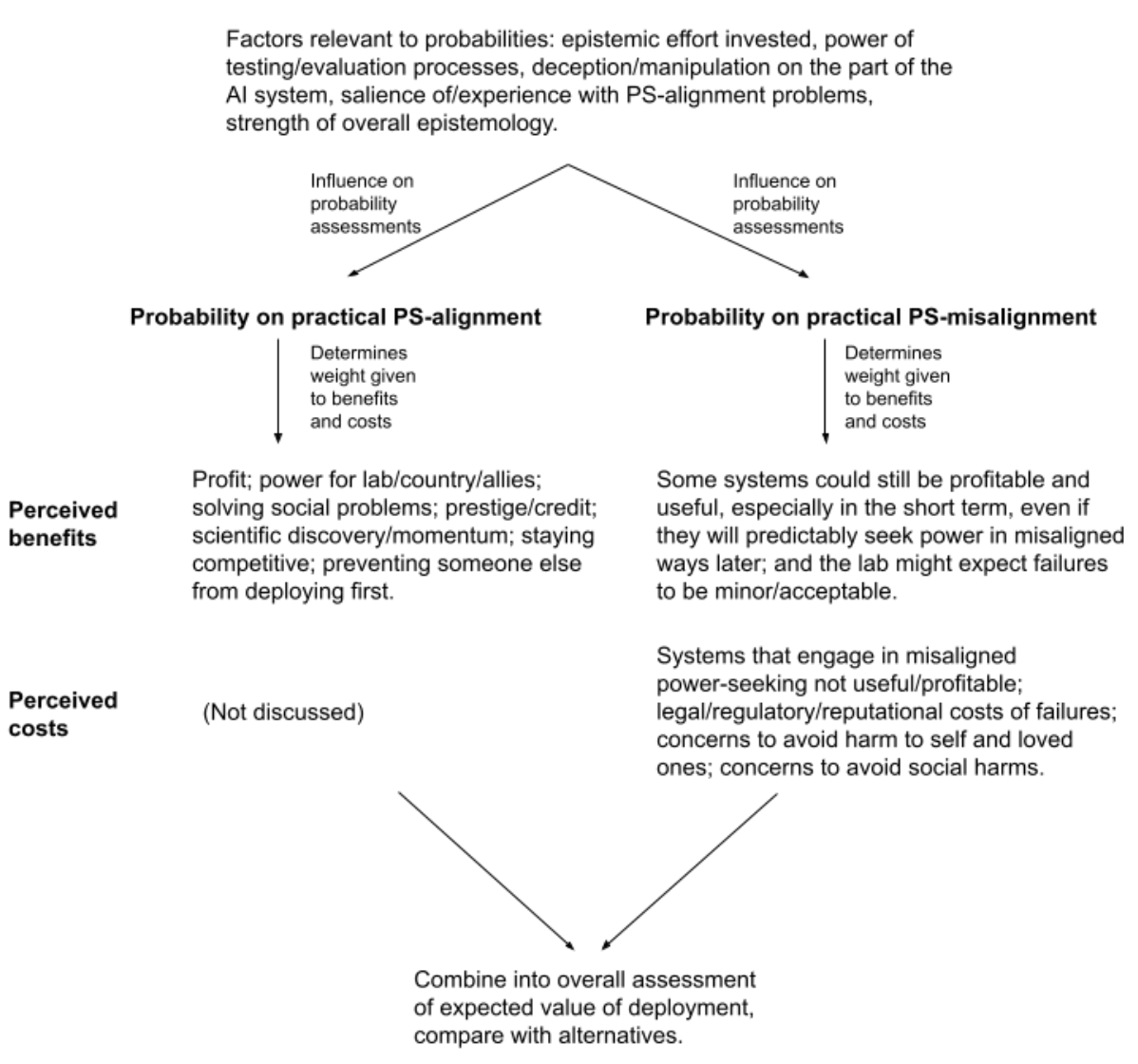
“Part of the challenge of ensuring PS-alignment is detecting problems with an APS system’s objectives—for example, via various processes of testing and evaluation.”
“It’s possible to question whether humanity’s permanent and unintentional disempowerment at the hands of AI systems would qualify. In particular, if you are optimistic about the quality of the future that practically PS-misaligned AI systems would, by default, try to create, then the disempowerment of all humans, relative to those systems, will come at a much lower cost to the future (and perhaps even to the present) in expectation.”
Carlsmith, J. (2022). Is power-seeking AI an existential risk?. arXiv preprint arXiv:2206.13353.
https://arxiv.org/abs/2206.13353
Evolution of AI Agent Registry Solutions: Centralized, Enterprise, and Distributed Approaches
Who agents the agents
“We analyze five prominent approaches: (1) MCP Registry (centralized publication of mcp.json descriptors), (2) A2A Agent Cards (decentralized self-describing JSON capability manifests), (3) AGNTCY Agent Directory Service (IPFS Kademlia DHT content routing extended for semantic taxonomy–based content discovery, OCI artifact storage, and Sigstore-backed integrity), (4) Microsoft Entra Agent ID (enterprise SaaS directory with policy and zero-trust integration), and (5) NANDA Index AgentFacts (cryptographically verifiable, privacy-preserving fact model with credentialed assertions). Using four evaluation dimensions—security, authentication, scalability, and maintainability—we surface architectural trade-offs between centralized control, enterprise governance, and distributed resilience.”
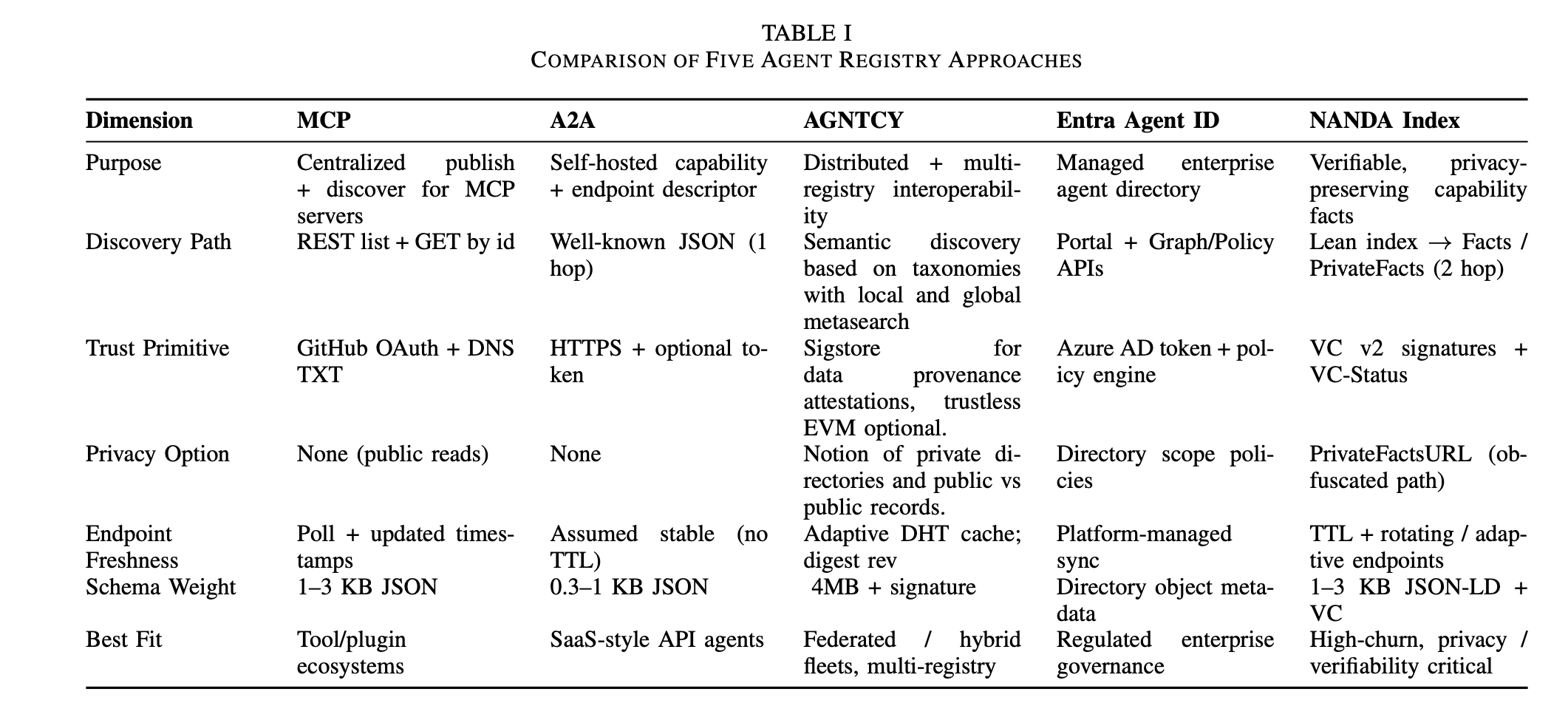
“Just as ICANN enabled the internet to scale through neutral governance and open standards, realizing an Internet of AI Agents requires foundational infrastructure built collaboratively across industry, academia, and civil society, where technical standards, governance frameworks, and reference implementations reflect diverse needs rather than single-vendor control. The decisions made now will shape agent interaction patterns for decades; we invite the community to participate in building this infrastructure openly, ensuring the agentic web serves the entire ecosystem.”
Singh, A., Ehtesham, A., Raskar, R., Lambe, M., Chari, P., Grogan, J. J., ... & Kumar, S. (2025). A Survey of AI Agent Registry Solutions. arXiv preprint arXiv:2508.03095.
https://arxiv.org/abs/2508.03095
A path towards AI-scale, interoperable biological data
Standards Standard Problem
“The data bottleneck presents a unique paradox in scientific research. It is increasingly simple to generate huge volumes of data—thanks to expanding imaging datasets and plummeting sequencing costs [1]—but scientists lack standards and tooling for large biological datasets, preventing the integration of generated datasets into a multimodal foundational dataset that will be key to unlocking truly generalizable models of cellular and tissue function. This contradiction highlights two interrelated problems: there is an abundance of data that is difficult to manage, and a lack of data resources with the necessary quality and utility to realize AI’s potential in biology.”

“Building VCMs alone will be slower, more expensive, and less powerful than collective action. By producing large, rigorously annotated datasets in open formats, CZI aims to not only accelerate our own multiomic modeling, but to increase adoption of formats and standards across the scientific community, boost the use of biological data, and drive collective progress towards multi-modal modeling.”
Aevermann, B., Califano, A., Chiu, C. L., Clack, N., Clemons Jr, W. M., D'Orazi, J. C. F. D., ... & Carr, A. J. (2025). A path towards AI-scale, interoperable biological data. arXiv preprint arXiv:2510.09757.
https://arxiv.org/abs/2510.09757
Language Models (Mostly) Know What They Know
We know
“Performance at self-evaluation further improves when we allow models to consider many of their own samples before predicting the validity of one specific possibility. Next, we investigate whether models can be trained to predict "P(IK)", the probability that "I know" the answer to a question, without reference to any particular proposed answer. Models perform well at predicting P(IK) and partially generalize across tasks, though they struggle with calibration of P(IK) on new tasks. The predicted P(IK) probabilities also increase appropriately in the presence of relevant source materials in the context, and in the presence of hints towards the solution of mathematical word problems.”

“We find mixed but encouraging results here: when testing on the ground-truth P(IK) data from model A, both starting from model A and starting from model B seems to give comparable performance. However, when testing on ground-truth P(IK) data from model B, starting from model B seems to do better than starting from model A. We also tried focusing on only the questions where the two models differ, but we found similar results in that case.”
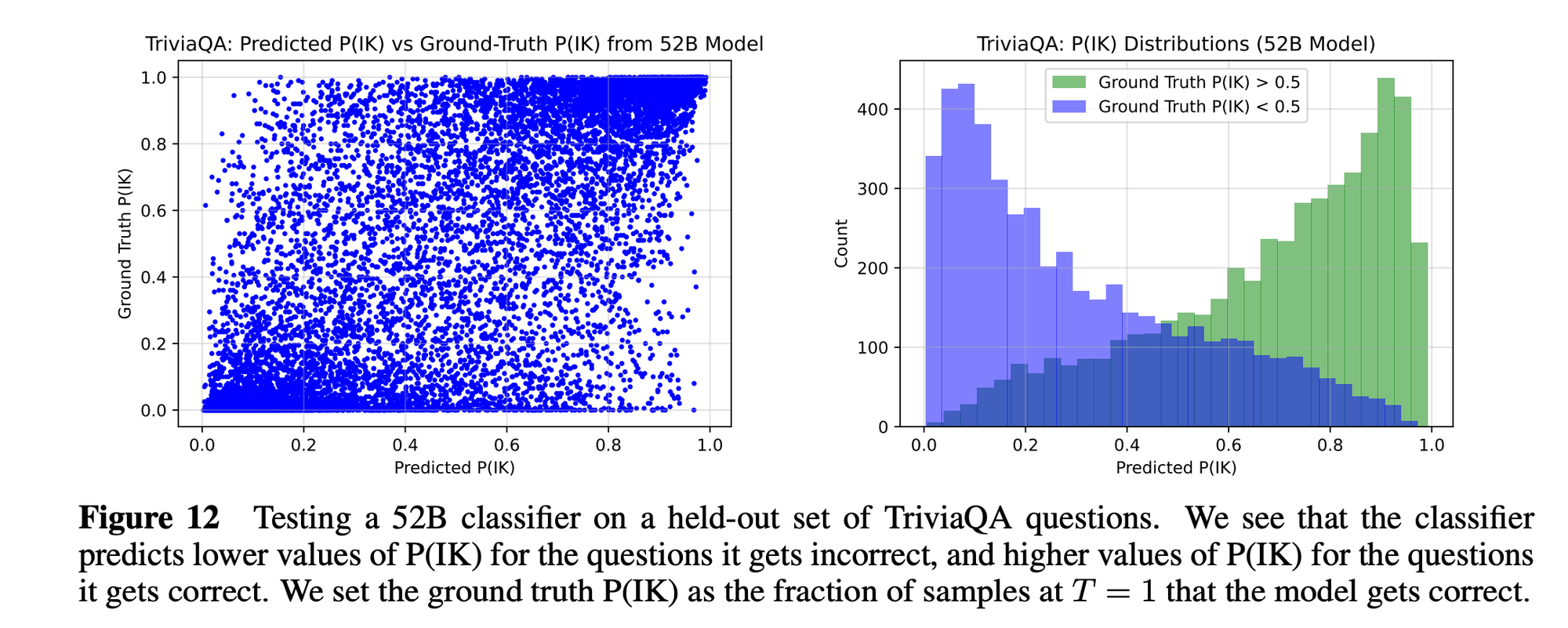
Kadavath, S., Conerly, T., Askell, A., Henighan, T., Drain, D., Perez, E., ... & Kaplan, J. (2022). Language models (mostly) know what they know. arXiv preprint arXiv:2207.05221.
https://arxiv.org/pdf/2207.05221
Reader Feedback
“Non, rien de rien. Non, je ne regrette rien”
Footnotes
When my own newsletter didn’t appear at 10AM Tuesday like clockwork, I went fishing for it. If you didn’t get your newsletter, as the open rate suggests, it’s there. I sent it. Go look.
If you’ve been reading Footnotes, you read this insight:
The vast majority of inventors and entrepreneurs don’t metabolize their experience as minimizing regret with the demand curve.
Which prompted a deeper love letter to a niche of a niche.
What’s the demand for finding demand?
Let’s find out!
It’s alpha. It surprises me when squashed bugs reappear.
There’s always that balance in sharing early. Share too early and too messy and early users conclude there’s no signal. Share too late and die from a lack of feedback.
Never miss a single issue
Be the first to know. Subscribe now to get the gatodo newsletter delivered straight to your inbox