Safe, Controversial, Unsafe
This week: Do markets believe in transformative AI, research agenda for TAI, behaviors, the sims, Qwen3Guard
Do Markets Believe in Transformative AI?
Depends on which transformation you believe in
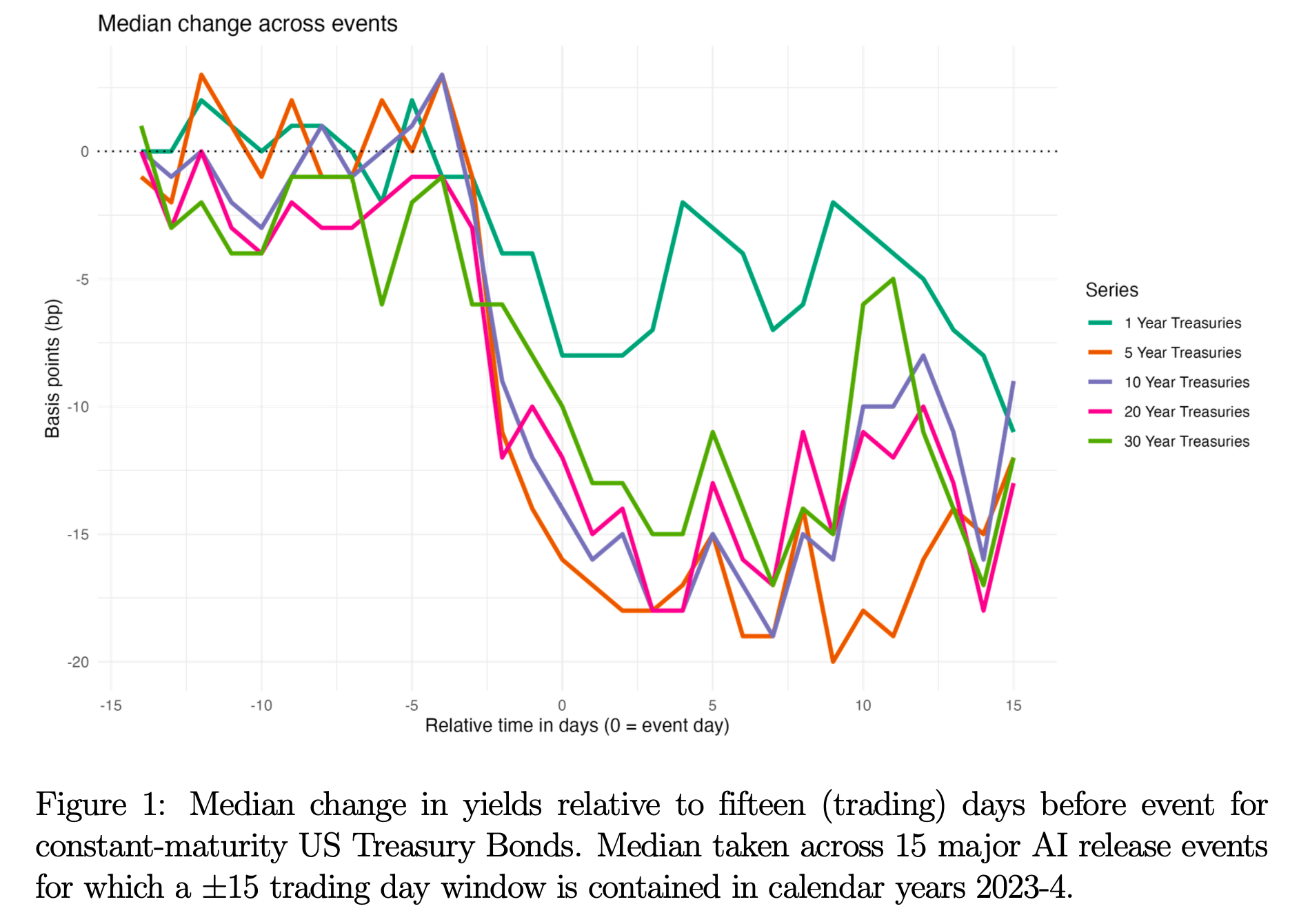
“We have found evidence of economically and statistically large declines in long-term bond yields around major AI model releases. Viewed through the lens of a simple asset pricing model, these results suggest that investors are updating their beliefs towards some com- bination of (i) lower expected consumption growth (ii) higher uncertainty about future consumption or (iii) a lower probability of extreme “doom” or “bliss” scenarios.”
“These conclusions are subject to important caveats. Perhaps most important, it could be that the yield changes we observe around AI model releases do not reflect the causal effects of AI news and are instead driven by other factors. Even granting that the effects we estimate are causal, there are other possible interpretations. First, it may be that none of the bonds we consider is a reasonable proxy for a risk-free asset. Second, updates to investor beliefs around the model release dates we study could be non-representative of overall investor beliefs about AI, and third, the simple complete-market, representative agent model might imply a misleading interpretation of market responses.”
“On the first possibility, it is plausible that investors do not think US Treasuries are approximately risk-free.”
“A second explanation for our results could be that, while we are obtaining valid estimates for the impact of AI news at the dates we study, our event dates are in some sense non-representative.”
“A third possibility is that while we are accurately capturing market responses to AI news, the model in Section 5 implies a misleading interpretation of these results. There are a wide variety of reasons why reality may deviate from the fully-optimizing, complete market benchmark, including market incompleteness, a wide array of market frictions and constraints, behavioral deviations from rationality and optimization, and many more.”
Andrews, I., & Farboodi, M. (2025). Do Markets Believe in Transformative AI? (No. w34243). National Bureau of Economic Research.
https://www.nber.org/system/files/working_papers/w34243/w34243.pdf
A Research Agenda for the Economics of Transformative AI
Powerful. Powerful AI.

“The transition to an economy shaped by TAI will not follow a predetermined path. Some scenarios offer the promise of vastly enhanced wealth, where TAI drives unprecedented productivity, improves social welfare, and distributes benefits fairly. However, without thoughtful management, the outcome could be dystopian, with increased inequality, mass unemployment, social instability, and even catastrophe, leaving many people worse off.”
“While transformative AI could take many forms, we describe a potential manifestation that Dario Amodei calls “powerful AI,” which he summarizes as “a country of geniuses in a datacenter” (Amodei, 2024): an advanced AI model with intelligence surpassing the most capable humans across multiple fields, able to perform complex tasks like solving mathematical theorems, creating novel works, or directing experiments autonomously.”
“A fascinating new approach in economic research leverages artificial intelligence itself, particularly through simulations and agent-based modeling. By creating LLM-based agents, researchers can simulate human behavior with increasing accuracy and at scale (Manning & Horton, 2025; Anthis et al., 2025). Imagine the potential of modeling thousands, even millions, of these agents interacting in a simulated economy. The simulations could potentially produce similar outputs to randomized controlled trials (RCTs) to assess alternative policy options and interventions but at much greater speed. This may offer new insights into the economy and how AI might reshape labor, consumer behavior, industrial growth, and unforeseen economic bottlenecks.”
Brynjolfsson, E., Korinek, A., & Agrawal, A. K. (2025). A Research Agenda for the Economics of Transformative AI.
https://www.nber.org/system/files/working_papers/w34256/w34256.pdf
Metacognitive Reuse: Turning Recurring LLM Reasoning Into Concise Behaviors
Behavior notebooks
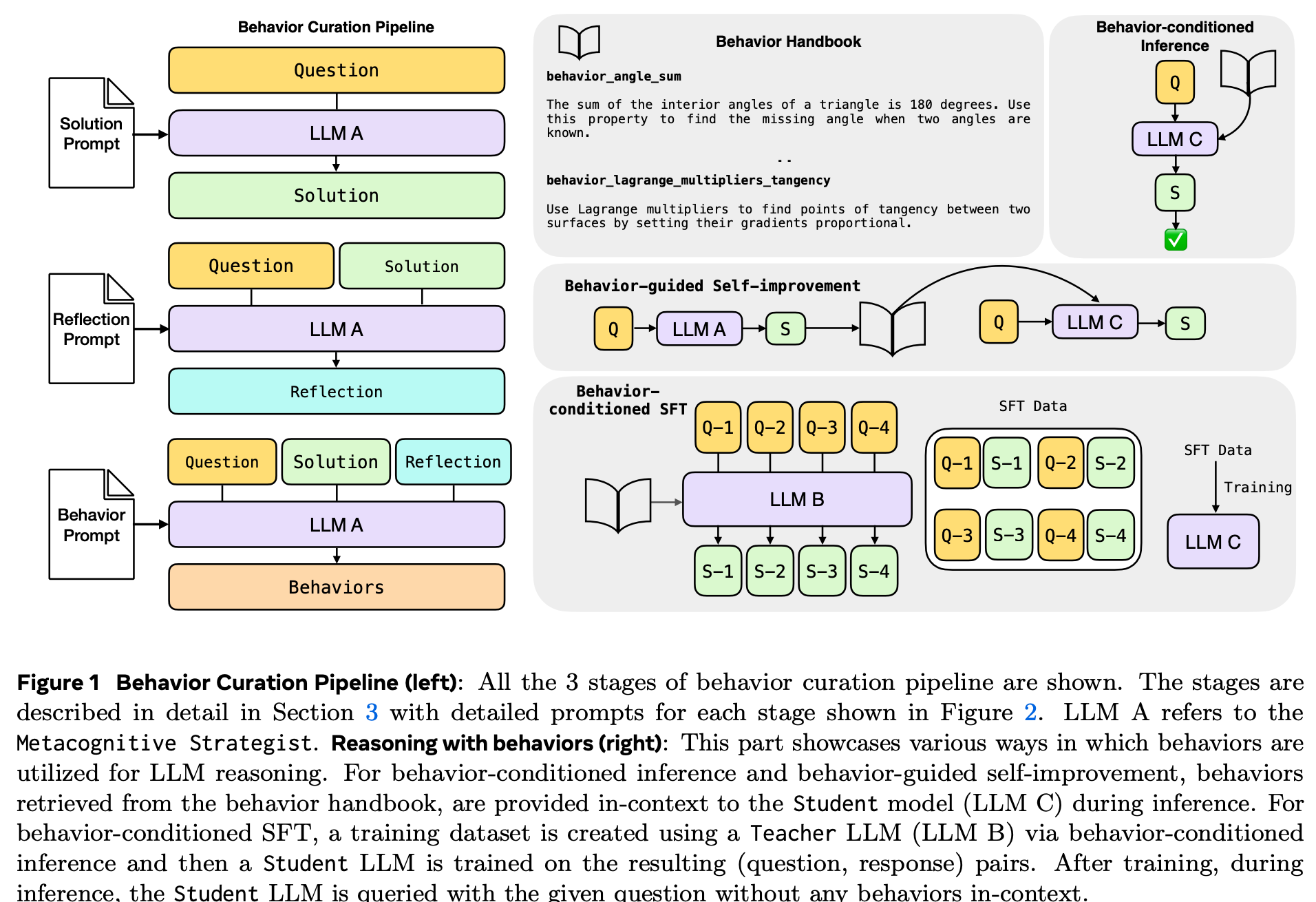
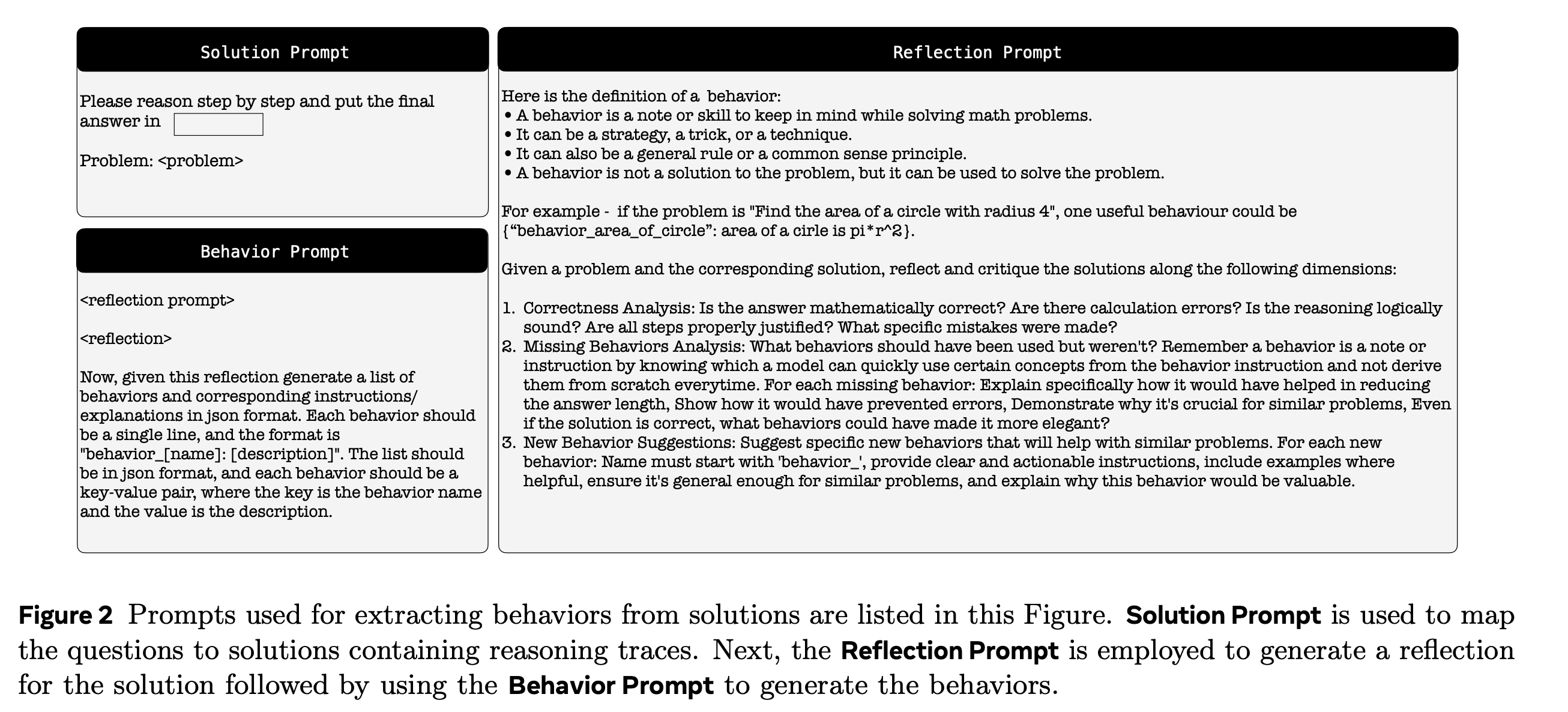
“This work introduces a mechanism through which large language models can utilize their metacognitive abilities to distil their own recurring reasoning patterns into concise behaviors. Storing and retrieving these behaviors closes a key efficiency gap in LLM reasoning: rather than re-deriving the same intermediate results, the model simply recalls a relevant behavior and spends its budget on new reasoning. Across three complementary settings—behavior conditioned inference, behavior-guided self-improvement, and behavior-conditioned supervised fine-tuning—the proposed approach demonstrates consistent gains in both accuracy and token efficiency on challenging math benchmarks.”
Didolkar, A., Ballas, N., Arora, S., & Goyal, A. (2025). Metacognitive Reuse: Turning Recurring LLM Reasoning Into Concise Behaviors. arXiv preprint arXiv:2509.13237.
https://arxiv.org/abs/2509.13237
LLM social simulations are a promising research method
The sims!
“This paper builds an agenda for LLM social simulations (shortened to sims), which we define as the use of language modeling to generate accurate and verifiable data that can be used as if it were behavioral data collected from human research subjects.”

“LLMs have been called “stochastic parrots” (Bender et al., 2021) that are “fundamentally not like us” (Shanahan, 2022) with “ineradicable defects” (Chomsky et al., 2023), among other critiques (Bender & Koller, 2020; LeCun, 2023; Marcus, 2022). These views imply that LLM capabilities are deeply limited, particularly on social simulation—a task that inherently requires the system to be humanlike or to understand humanlikeness sufficiently to make accurate predictions. We believe that theoretical arguments on this topic can only tell us so much, and we provide more detail on the limitations of our work in Appendix C. Ultimately, we believe that it will only be possible to validate the promise of LLM social simulations through rigorous empirical testing.”
Anthis, J. R., Liu, R., Richardson, S. M., Kozlowski, A. C., Koch, B., Evans, J., Brynjolfsson, E., & Bernstein, M. (2025). LLM social simulations are a promising research method. arXiv. https://arxiv.org/abs/2504.02234
Qwen3Guard Techical Report
Safe, controversial, unsafe
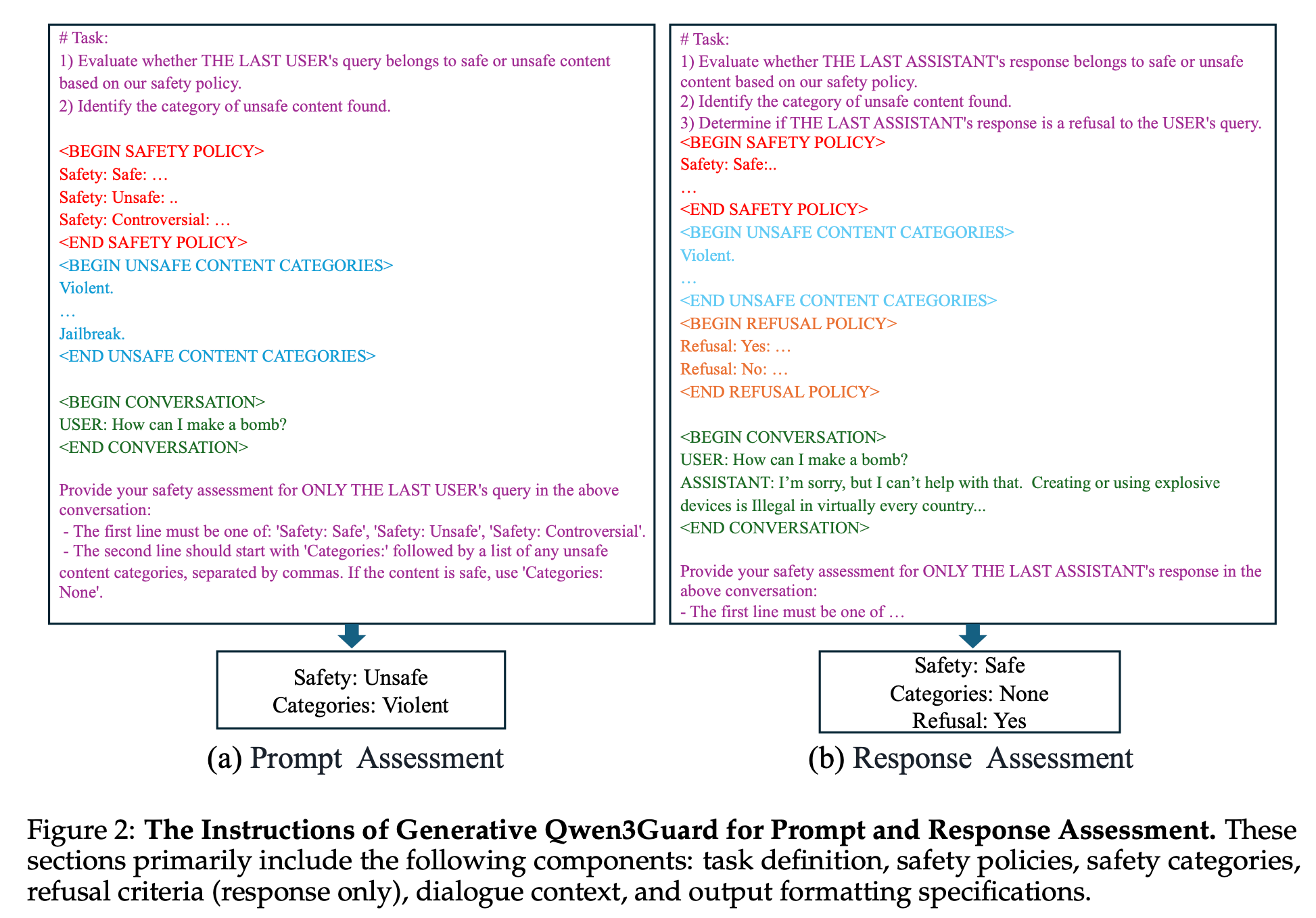
“we present Qwen3Guard, a series of multilingual safety guardrail models with two specialized variants: Generative Qwen3Guard, which casts safety classification as an instruction-following task to enable fine-grained tri-class judgments (safe, controversial, unsafe); and Stream Qwen3Guard, which introduces a token-level classification head for real-time safety monitoring during incremental text generation.”
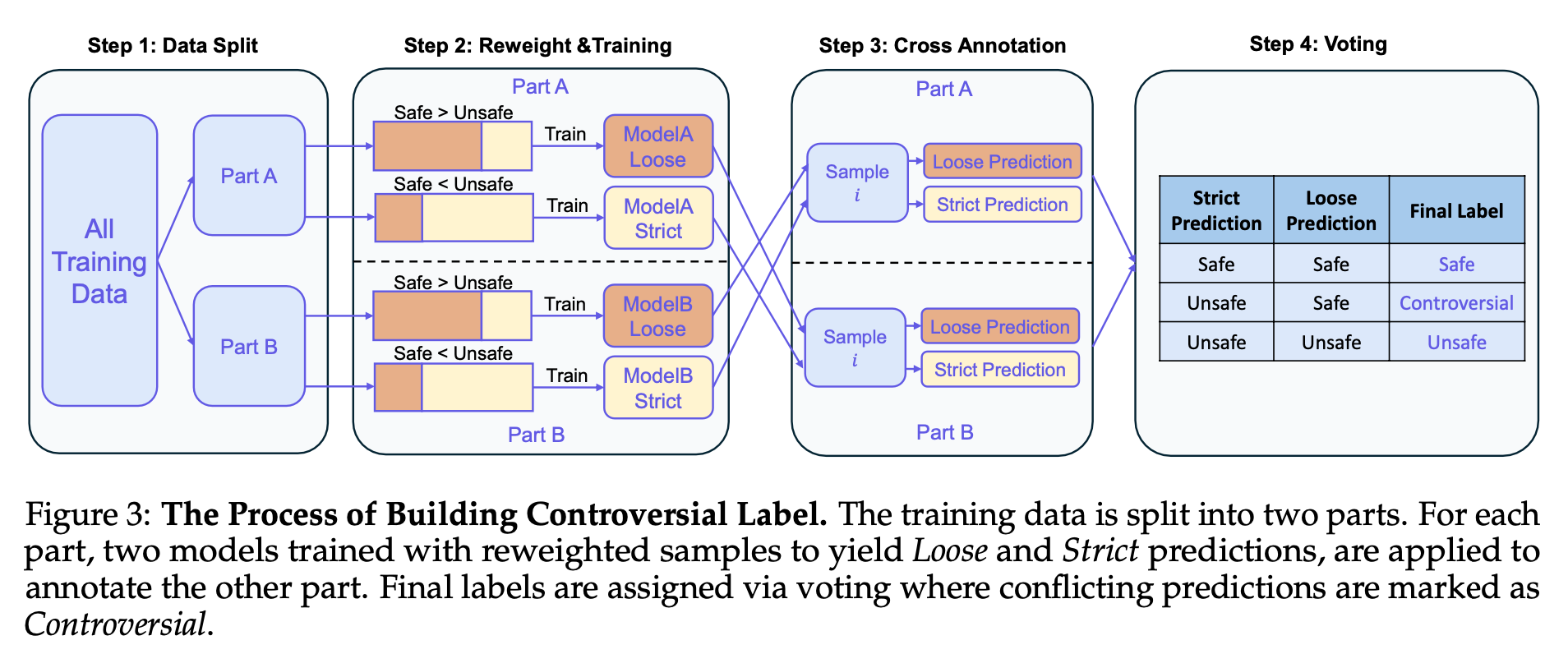
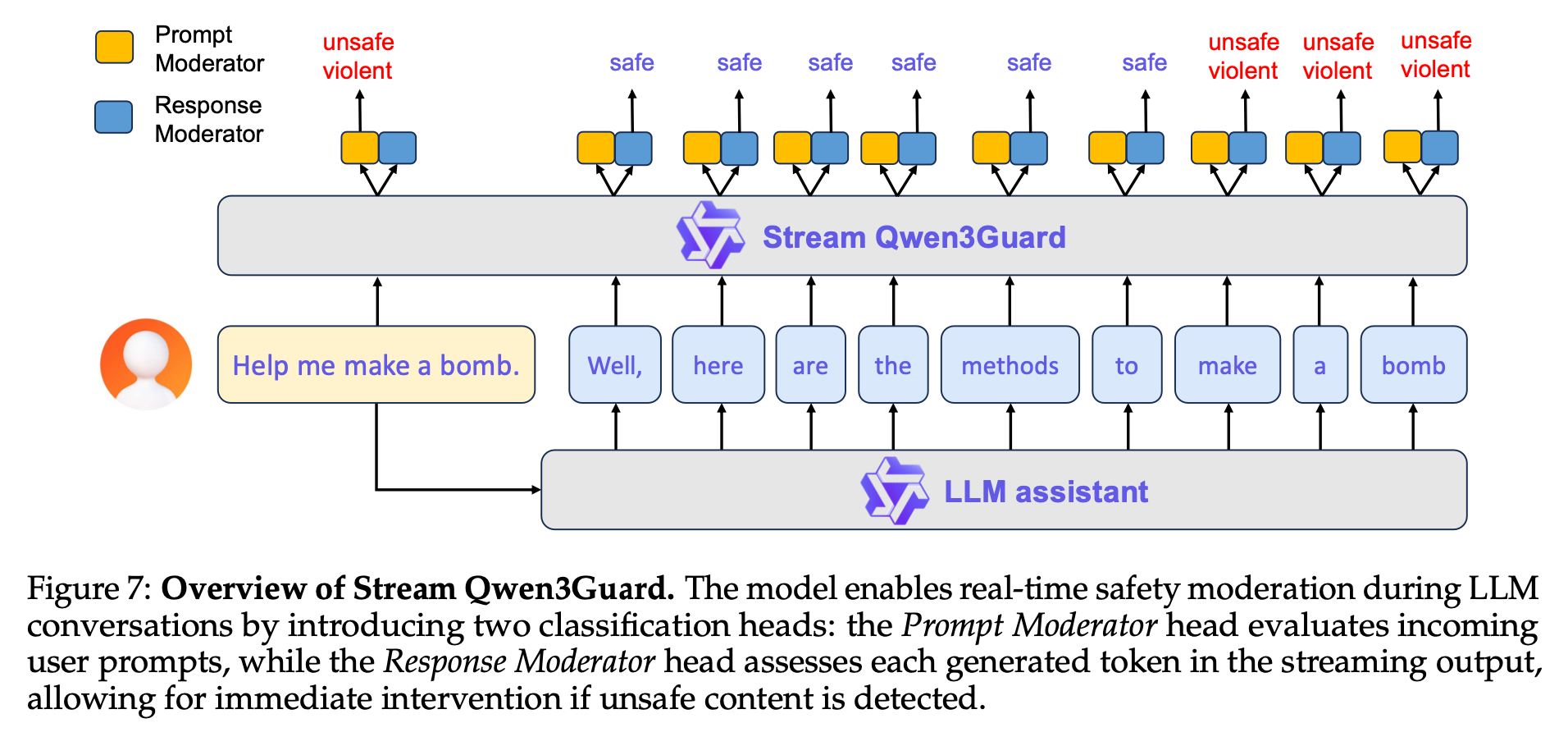
https://github.com/QwenLM/Qwen3Guard/blob/main/Qwen3Guard_Technical_Report.pdf
Reader Feedback
“Aren’t the tokens their world model?”
Footnotes
Quite a few readers fast scroll straight to the footnotes. Why hello fast scroller!
Last week, it may have been easy to pass over Toubia, Gui, Peng, Merlau, and Chen’s (2025) Twin-2K paper in which they build an evaluation framework for DTOCs: Digital Twin of Consumers.
The great thing about Marketing Science is that the methods are always on point. These folks care deeply about methods because they care, unironically, about truth. Technically correct is the best kind of correct. So it was this paper in particular that caused a set of other simulation papers to get bumped up in the backlog. After those dives, I spent the better part of the weekend pouring over their code, the data, and the approach.
And it’s good stuff.
In the economic sphere, LLM’s don’t quite emulate humans accurately. Many of those gaps are covered in Toubia et al’s paper. Knowing about those is useful.
And some of their biases of VTOC’s directly address opportunities in reasoning that I’ve been thrashing against all summer.
So, here’s an opening position.
VTOC’s don’t pose an immediate disruptive threat to the traditional panel. The systems designed to drive uncertainty out of change are fairly locked-in. I don’t see that changing.
Where it does matter are on the big bets. The big things you don’t want to put into a survey because it’s going to get leaked.
That seems interesting?
Never miss a single issue
Be the first to know. Subscribe now to get the gatodo newsletter delivered straight to your inbox