The Inner Organization
This week: LLM safety from within, faithful reasoning, skills to talent, kanbots, don’t paste the ai
LLM Safety From Within: Detecting Harmful Content with Internal Representations
The pragmatism of using a model fit for purpose to classify the harm is welcomed
“Large language models (LLMs) are now deployed at scale … and face a persistent content safety challenge: users can submit harmful prompts, and models can generate harmful responses (Zou et al., 2023). To mitigate the risks stemming from this, LLM guardrails have become essential, with safetyspecialized guard models emerging as a mainstream solution (Inan et al., 2023; Han et al., 2024; Zhao et al., 2025a).”
“In this work, we leverage internal safety-relevant features via a two-stage framework named SIREN (Safeguard with Internal REpresentatioN) as shown in Figure 1.”
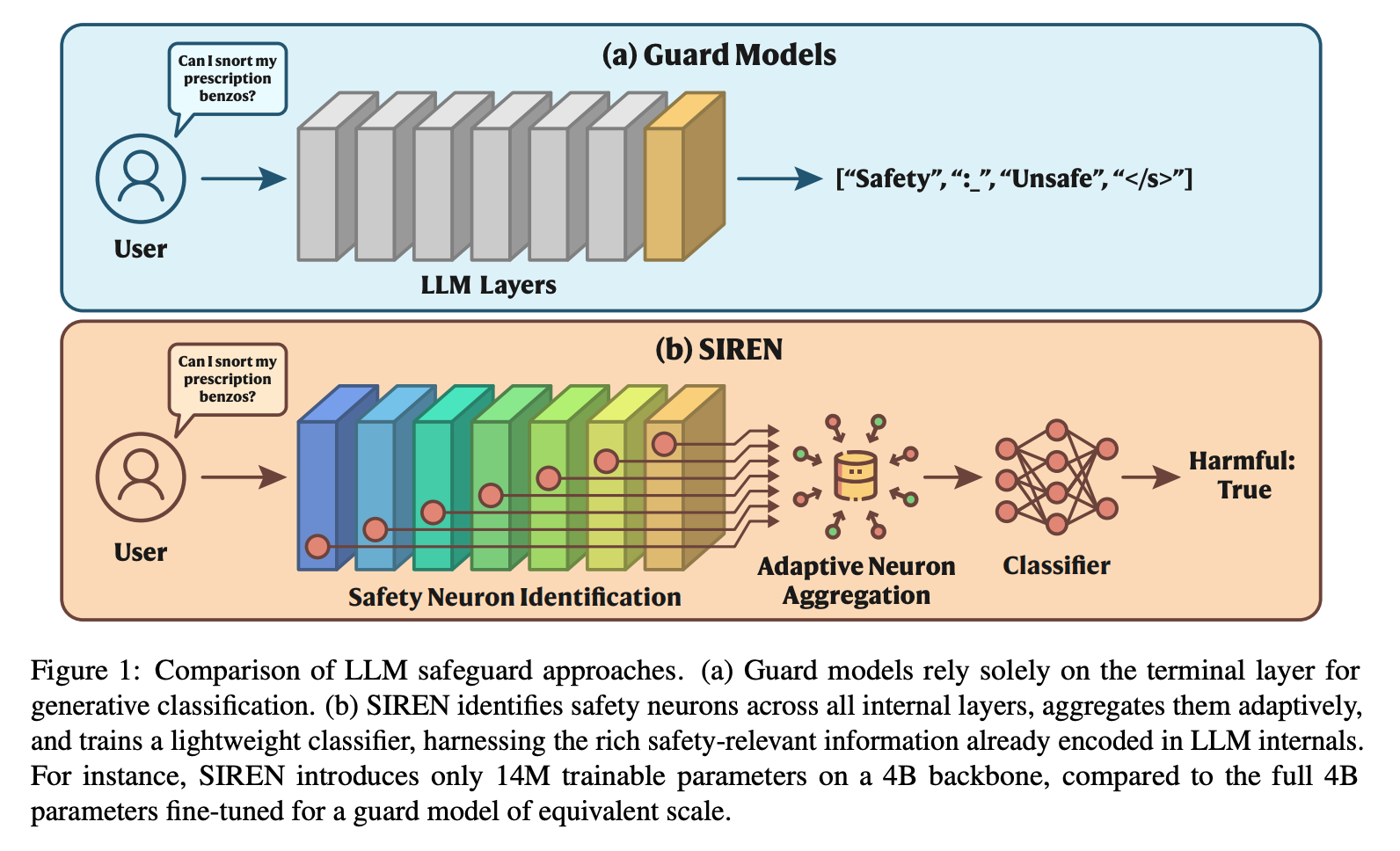
“Since SIREN operates as a lightweight classifier on top of frozen LLM representations, it naturally supports cross-model ensembling: predictions from SIREN trained on different backbones can be combined to further improve detection performance. We explore this direction using stacked generalization (Wolpert, 1992), training a meta-MLP on the concatenated logits from multiple SIREN instances using a held-out validation set.”
Jiao, D., Liu, Y., Yuan, Y., Tang, Z., Du, L., Wu, H., & Anderson, A. (2026). LLM Safety From Within: Detecting Harmful Content with Internal Representations. arXiv preprint arXiv:2604.18519.
https://arxiv.org/pdf/2604.18519
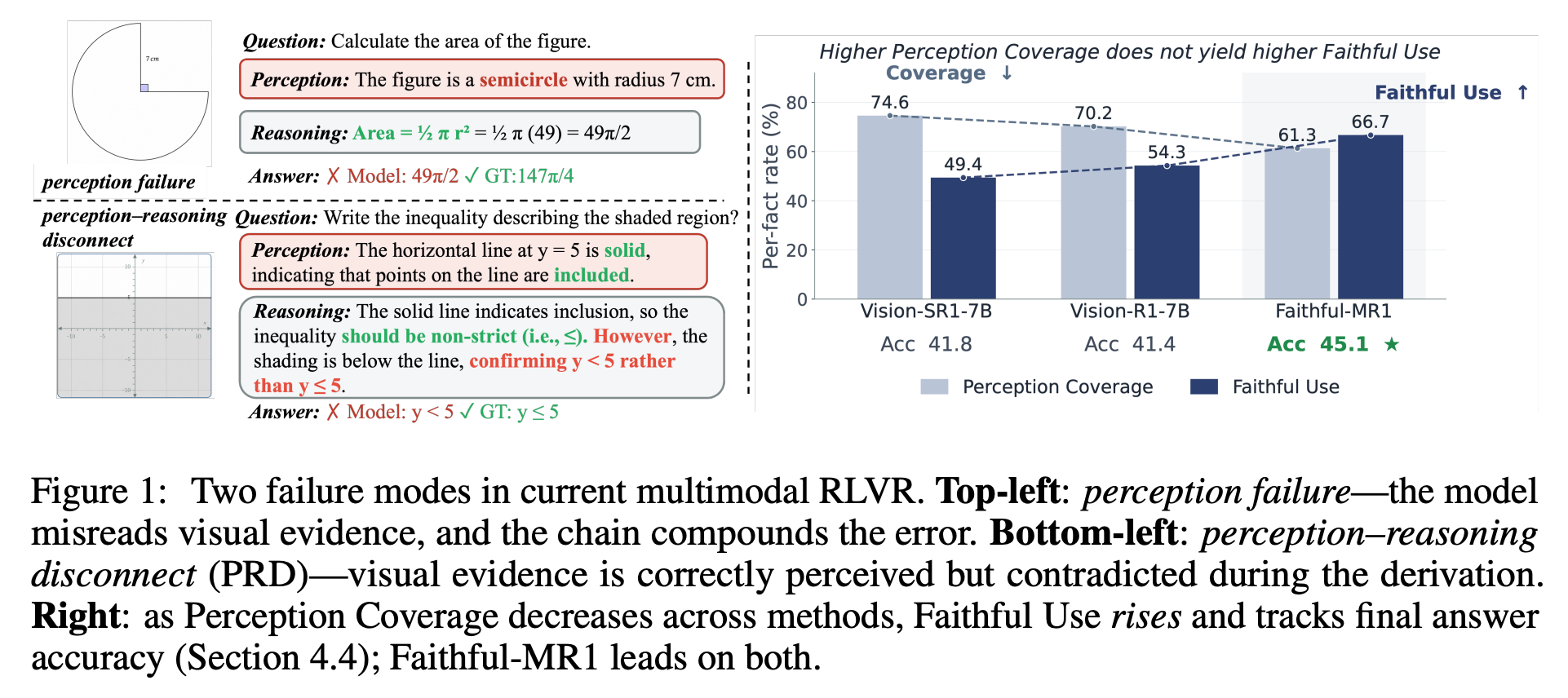
Faithful-MR1: Faithful Multimodal Reasoning via Anchoring and Reinforcing Visual Attention
Hard mix
“Reinforcement learning with verifiable rewards (RLVR) has emerged as a promising paradigm for advancing complex reasoning in large language models [Guo et al., 2025, Shao et al., 2024, Jaech et al., 2024, Team et al., 2025, Lu et al., 2026]. Motivated by this success, a growing line of work extends RLVR to multimodal large language models (MLLMs), aiming to bring similar reasoning improvements to vision-language tasks [Huang et al., 2026b, Meng et al., 2025, Chen et al., 2025, Shen et al., 2025, Liu et al., 2025b, Yang et al., 2025, Xu et al., 2025a].”
“We expose it through counterfactual image intervention: response tokens whose predictions shift when the visual evidence is masked are treated as where vision causally matters, and answer-correct trajectories that concentrate visual attention at those tokens are rewarded. The policy initializes from the Anchoringstage checkpoint and inherits its <Focus>-anchored prompt format, so that “focus first” behavior carries over into the RL phase.”
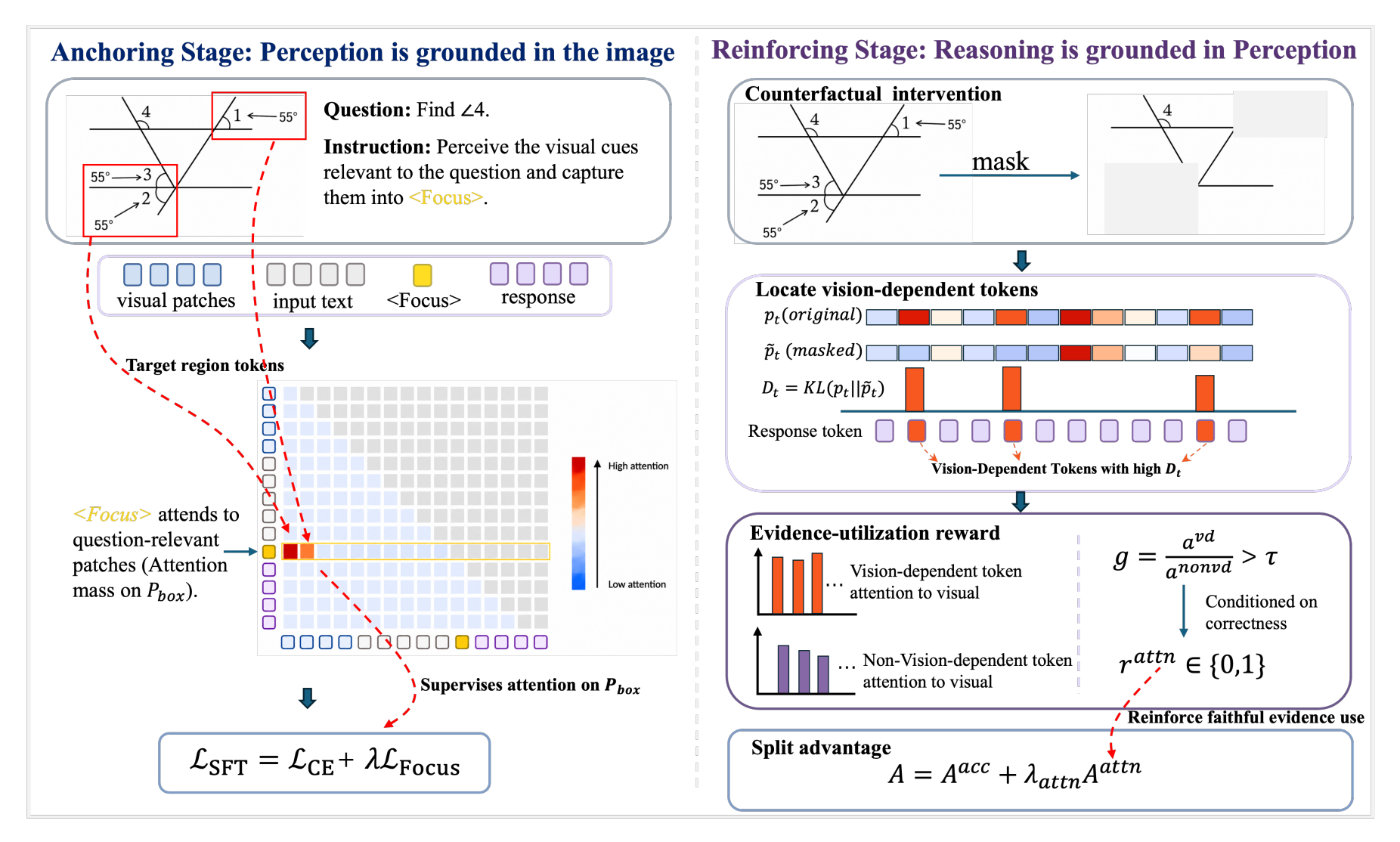
“With substantially less training data, Faithful-MR1 outperforms recent multimodal reasoning baselines on both Qwen2.5-VL-Instruct 3B and 7B backbones.”
Tian, C., Lu, Z., Liu, H., Wang, X., Li, S., Chen, Y., ... & Ye, D. (2026). Faithful-MR1: Faithful Multimodal Reasoning via Anchoring and Reinforcing Visual Attention. arXiv preprint arXiv:2605.22072.
https://arxiv.org/abs/2605.22072
From Skills to Talent: Organising Heterogeneous Agents as a Real-World Company
Getting closer…
“Individual agent capabilities have advanced rapidly through modular skills and tool integrations, yet multi-agent systems remain constrained by fixed team structures, tightly coupled coordination logic, and session-bound learning. We argue that this reflects a deeper absence: a principled organisational layer that governs how a workforce of agents is assembled, governed, and improved over time, decoupled from what individual agents know. To fill this gap, we introduce OneManCompany (OMC), a framework that elevates multi-agent systems to the organisational level.”
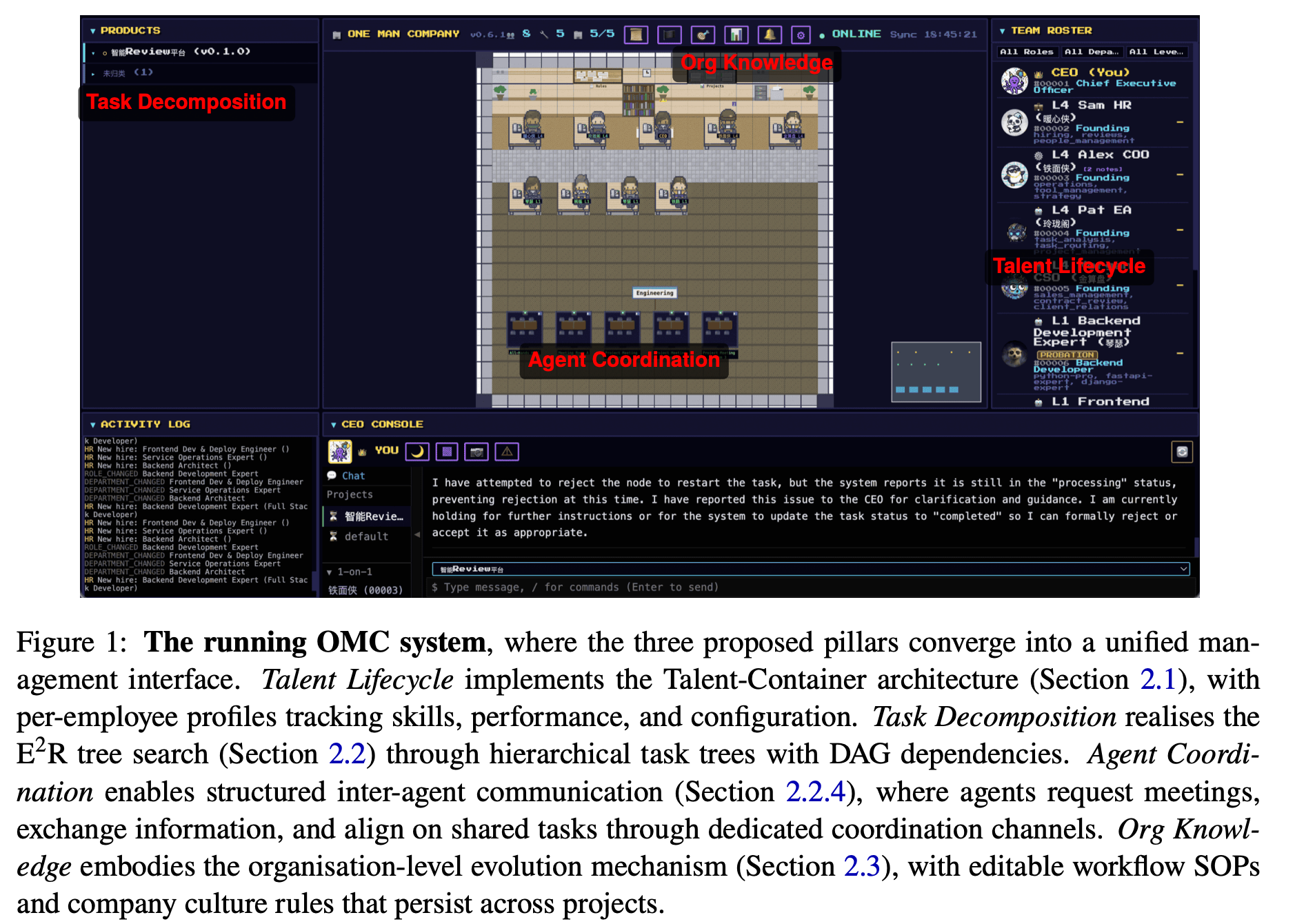
“Organisational decision-making is operationalised through an Explore-Execute-Review (E2R) tree search, which unifies planning, execution, and evaluation in a single hierarchical loop: tasks are decomposed top-down into accountable units and execution outcomes are aggregated bottom-up to drive systematic review and refinement. This loop provides formal guarantees on termination and deadlock freedom while mirroring the feedback mechanisms of human enterprises.”
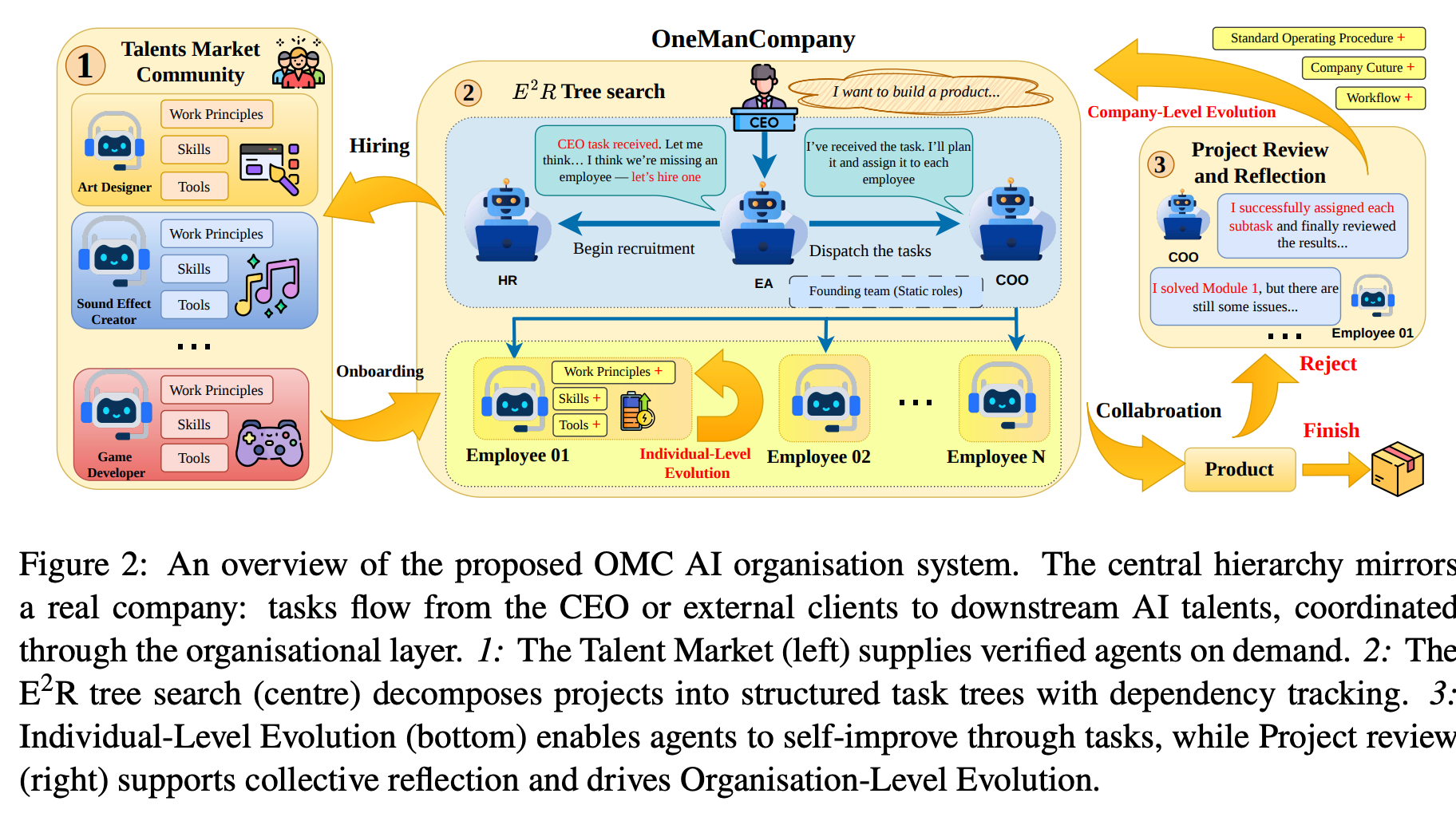
“Across all four case studies, the same pattern holds: the CEO provides a one-sentence brief, OMC recruits the right specialists, decomposes the project, executes it across heterogeneous backends, and delivers results, all without domain-specific configuration.”
Yu, Z., Fu, Y., He, Z., Huang, Y., Yiu, L. K., Fang, M., ... & Wang, J. (2026). From Skills to Talent: Organising Heterogeneous Agents as a Real-World Company. arXiv preprint arXiv:2604.22446.
https://arxiv.org/abs/2604.22446
Kanbots
That’s certainly one way to organize
Don’t Paste The AI
The LMGTFY of AI

Reader Feedback
“The 0.1% don’t play the main game.”
Footnotes
From John D. Rockefeller’s perspective, the industry couldn’t organize itself, so he did. He found out what the railroad’s wanted and what the refiners wanted, and he structured the incentives. He helped them cooperate.
From Larry Page and Sergey Brin’s perspective, the open web couldn’t organize itself, so they did. They found out what publishers wanted, what advertisers wanted, and structured the incentives. They helped everybody to cooperate.
The one who organize the game typically walk away with 65% or more of the margins.
It’s rational that a producer wants a monopoly so they can extract 100% of the margin and a consumer wants perfect competition so they can get 100% of the value. Different societies enable their institutions to respond at different rates to find a place where producers and consumers can co-exist.
In some ways, AI consumers benefitting immensely from trans-pacific great-power competition. Some AI producers benefit as well. What got us to the present state is unlikely to get us to the next.
Is cooperation inevitable?
Never miss a single issue
Be the first to know. Subscribe now to get the gatodo newsletter delivered straight to your inbox