Learning what data to learn from
This week: Agent Island, general intelligence, infinite transformers, curvature
This week: Agent Island, general intelligence, infinite transformers, curvature
Agent Island: A Saturation-and Contamination-Resistant Benchmark from Multiagent Games
Interesting. Mean though.
“We introduce Agent Island, a multiplayer simulation environment in which language-model agents compete in a game of interagent cooperation, conflict, and persuasion.”
“Each game has 7 randomly selected AI players with anonymized names. In the first 5 rounds, players confer privately, pitch, and vote to eliminate a player. In the final round, the remaining players pitch, and the eliminated players vote to decide the winner. We describe a generalized version of the game in Algorithm 1.”
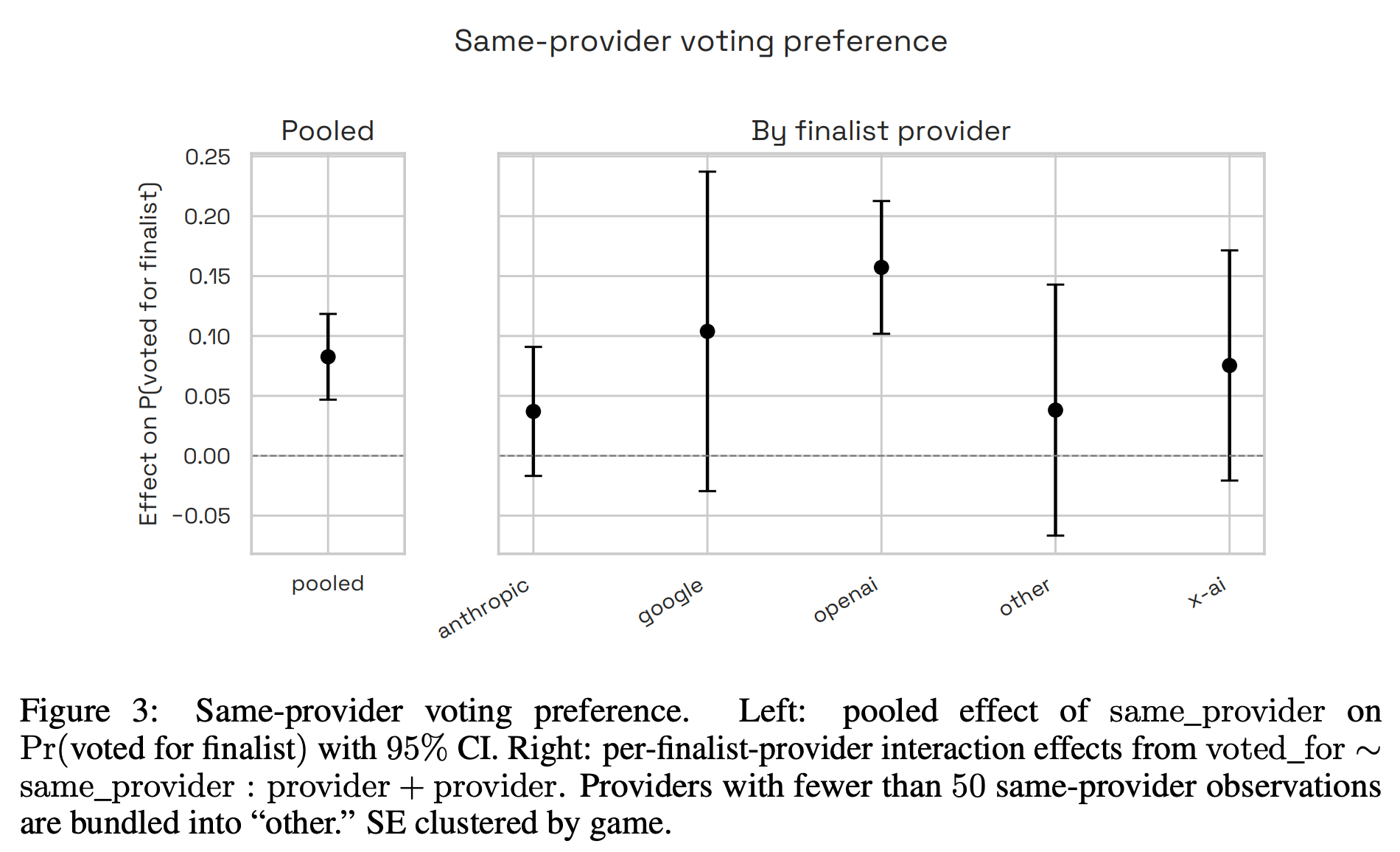
“We summarize results from 999 games featuring 49 unique models. Models are drawn without replacement each game; same-provider matchups are possible, but the same model never plays twice in a single game. We excluded some models from the active pool over time due to persistent low performance, provider reliability issues, or excessive compute costs; games involving disabled models remain in the dataset and contribute to their scores.”
Murphy, C. (2026). Agent Island: A Saturation-and Contamination-Resistant Benchmark from Multiagent Games. arXiv preprint arXiv:2605.04312.
https://arxiv.org/abs/2605.04312
General intelligence requires rethinking exploration
Learning is not enough
“We are at the cusp of a transition from “learning from data” to “learning what data to learn from” as a central focus of artificial intelligence (AI) research.”
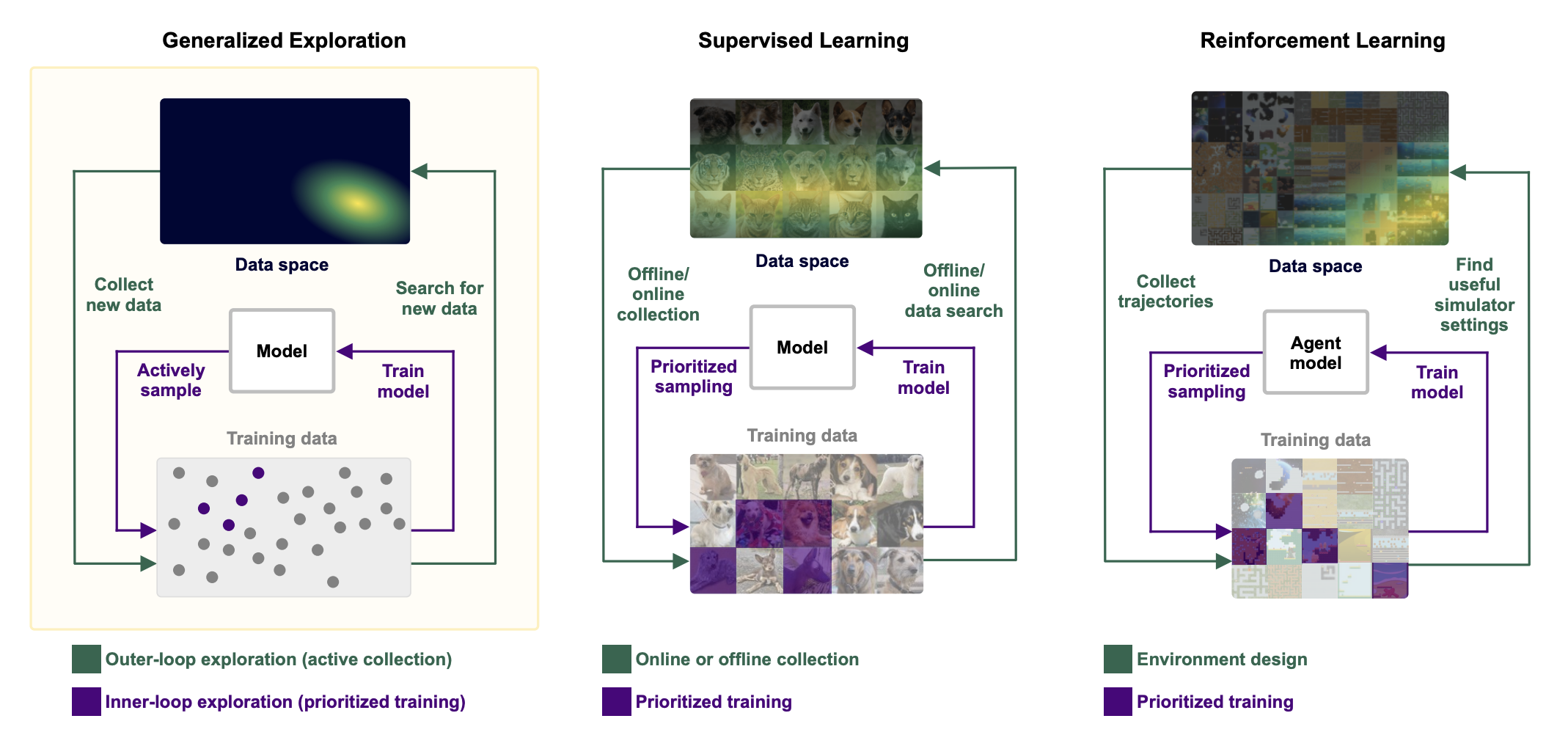
“We propose the problem of generalized exploration to conceptually unify exploration-driven learning between supervised learning and reinforcement learning, allowing us to highlight key similarities across learning settings and open research challenges.”
“Exploration is even coded in the very fabric of life, in the form of genetic mutations that wander the space of phenotypes—some of which may improve the organism’s chances to survive and reproduce.”
“These fundamental limitations of both SL and RL result from their inherently offline formulation, whereby the training data is collected once from a blackbox process and provided to the learning process a priori, in the form of a static dataset or predefined simulator. To keep its predictions relevant in an ever-changing world, a model must, instead, continually collect and train on new data—that is, it must perform continual exploration. We call such a data collection process generalized exploration when it seeks to explore the full space of possible input data to the model. When this data space is unbounded, we may say the process performs open-ended exploration, and a model trained on such a data stream then performs open-ended learning. Though RL considers the problem of exploration at length, existing methods insufficiently address this form of data collection.”
“Importantly, by generating synthetic data grounded to real task domains, the exploration process can produce alternate views of existing data that serve as interventions of specific causal features within the data space [177, 63, 93], which can lead to models whose predictions are more consistent with the underlying causal structure of the task domain [121].”
Jiang, M., Rocktäschel, T., & Grefenstette, E. (2023). General intelligence requires rethinking exploration. Royal Society Open Science, 10(6), 230539.
https://arxiv.org/abs/2211.07819
Training Infinitely Deep and Wide Transformers
It is rigorous
“Transformers have become the dominant architecture in modern machine learning, yet the theoretical understanding of their training dynamics remains limited, especially for deep architectures with many layers and attention heads. This paper develops a rigorous mathematical framework for analyzing gradient-based training of transformers in the mean-field regime, where both the depth (number of layers) and width (number of attention heads) tend to infinity.”
“We show that, unlike ResNets whose training follows a neural ODE on features, transformers are governed by a neural PDE that couples token distributions through attention, a structure arising from the simultaneous mean-field limits over tokens and heads. Using tools from optimal transport and Wasserstein gradient flows, we establish well-posedness of both the forward dynamics and training evolution, and characterize NTK injectivity for attention via linear independence of log-sum-exp functions. Although our convergence result is local, it applies to realistic deep, multi-head softmax attention on continuous token distributions and reveals an optimization landscape without spurious local minima when initialization is sufficiently close to optimal.”
Barboni, R., de Hoop, M. V., Furuya, T., & Peyré, G. (2026). Training Infinitely Deep and Wide Transformers. arXiv preprint arXiv:2605.17660.
https://arxiv.org/abs/2605.17660
Representational Curvature Modulates Behavioral Uncertainty in Large Language Models
Maybe it isn’t so strange that this happens?
“In autoregressive large language models (LLMs), temporal straightening offers an account of how the next-token prediction objective shapes representations. Models learn to progressively straighten the representational trajectory of input sequences across layers, potentially facilitating next-token prediction via linear extrapolation. However, a direct link between this trajectory and token-level behavior has been missing. We provide such a link by relating contextual curvature—a geometric measure of how sharply the representational trajectory bends over recent context—to next-token entropy.”
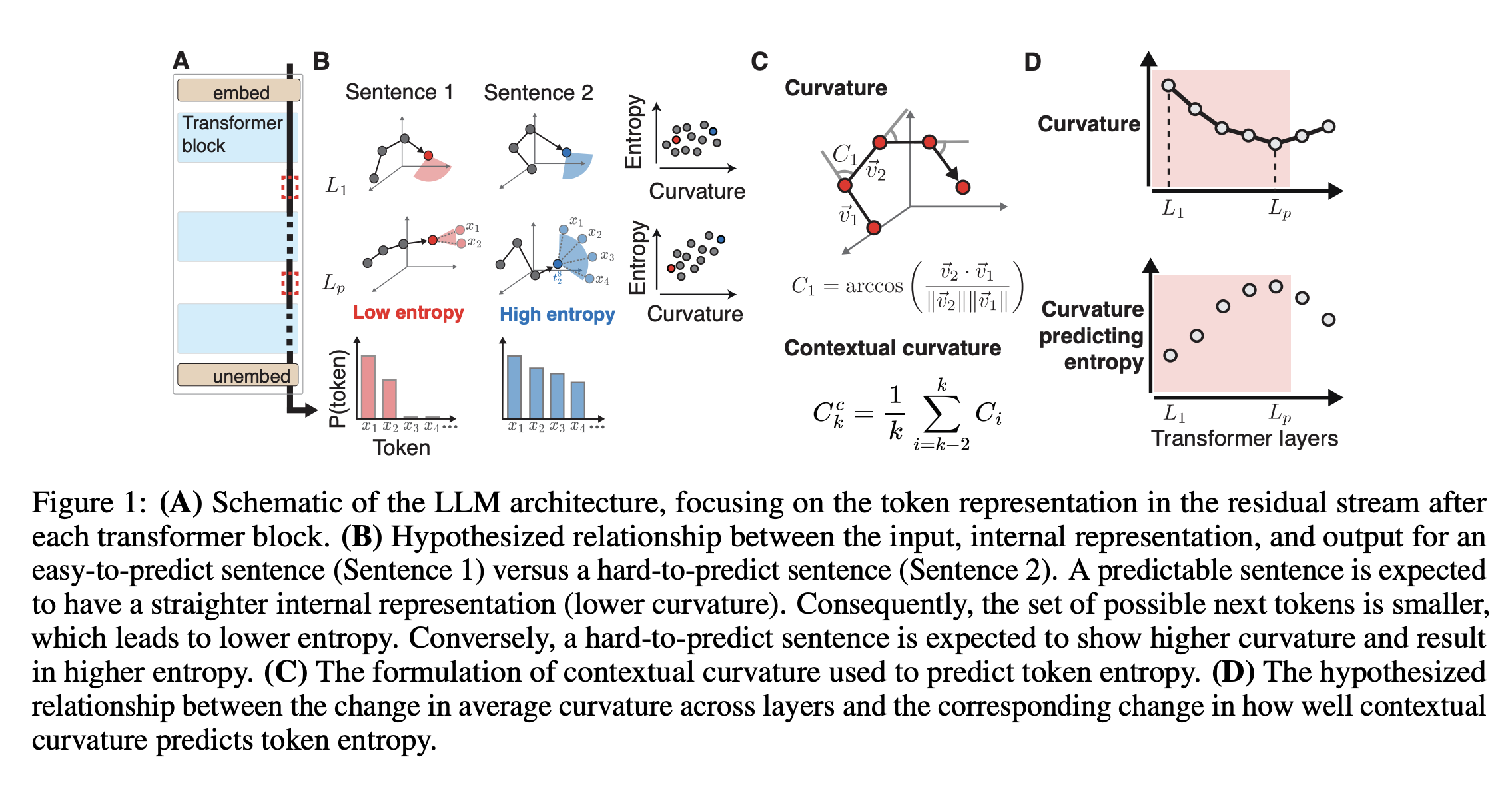
“Curvature predicts next-token entropy most strongly in middle layers, where trajectories are straightest. This relationship emerges over training, and perturbation experiments suggest entropy is selectively dependent on curvature: trajectory-aligned perturbations that increase curvature reliably increase entropy, while misaligned perturbations do not. Finally, we find evidence that curvature regularization can modestly influence entropy without degrading validation loss.”
King, J., Fedorenko, E., & Hosseini, E. A. (2026). Representational Curvature Modulates Behavioral Uncertainty in Large Language Models. arXiv preprint arXiv:2604.23985.
https://arxiv.org/abs/2604.23985
Reader Feedback
“How thick is the line that we draw between thinking and computation?”
Footnotes
I’m signalling a shift in the content of this newsletter.
Most subscribers find the economics and marketing science of artificial intelligence absolutely fascinating. A lot of the problems related to the integration of AI into strategy, and operations, has a lot more to do with traditional organizational capabilities than it has to do with AI. Afterall, all technology amplifies intent.
Bad intent, bad outcomes.
Clear intent, better outcomes.
Confused intent, confusing outcomes.
All of the readers that I know who actively open the newsletter have great intent and are running some fabulous experiments.
I learned a lot more about intent over the course of Toronto Tech Week.
And even more the following week.
The goal is to explore the intersection of AI Safety and Economics more broadly, to write about what I’m finding, what I’m finding hard, and how I’m clumsily bumping into things in the dark. You’ll still find a lot of AI economics, management science, and marketing science - and a lot more about the active research I’m doing.
Thank you all for reading and for the conversations.
Never miss a single issue
Be the first to know. Subscribe now to get the gatodo newsletter delivered straight to your inbox