How Do We Study What We Fear?
This week: Model organisms, measuring goal-level contributions, preference for explainable AI, do transformers need three projections, SEGA, AI isn’t management, predictive data debugging
Model Organisms
work, sashay chanté

“We don’t currently have ~any strong empirical evidence for the most concerning sources of existential risk, most notably stories around dishonest AI systems that actively trick or fool their training processes or human operators:
- Deceptive inner misalignment (a la Hubinger et al. 2019): where a model obtains good performance on the training objective, in order to be deployed in the real world and pursue an alternative, misaligned objective.
- Sycophantic reward hacking (a la Cotra 2022): where a model obtains good performance during training (where it is carefully monitored), but it pursues undesirable reward hacks (like taking over the reward channel, aggressive power-seeking, etc.) during deployment or in domains where it operates with less careful or effective human monitoring.
- Though we do have good examples of reward hacking on pretty-obviously-flawed reward functions, it's unclear if those kinds of failures happen with today’s systems which are built on human feedback. The potential reward-hacking failures with RLHF that have been discovered so far (e.g., potentially sycophancy) don’t necessarily seem world-ending or even that hard to fix.
A significant part of why we think we don't see empirical examples of these failure modes is that they require that the AI develop several scary tendencies and capabilities such as situational awareness and deceptive reasoning and deploy them together. As a result, it seems useful to evaluate the likelihood of each of the scary tendencies or capabilities separately in order to understand how severe the risks are from different potential forms of misalignment.”
Measuring, Inducing, and Exposing Goal-Level AI Contributions in Collaboration
“I Didn’t Make the Micro Decisions”
“We introduce a goal-level attribution framework, COTRACE, that decomposes explicit goals into verifiable requirements and traces both direct contributions and indirect influences across dialogue turns. Applying COTRACE to 638 real-world collaboration logs, we find that while models account for only 11–26% of goal-shaping contribution, they contribute substantially more on introducing lower-level concrete requirements, and make various kinds of indirect contributions.”
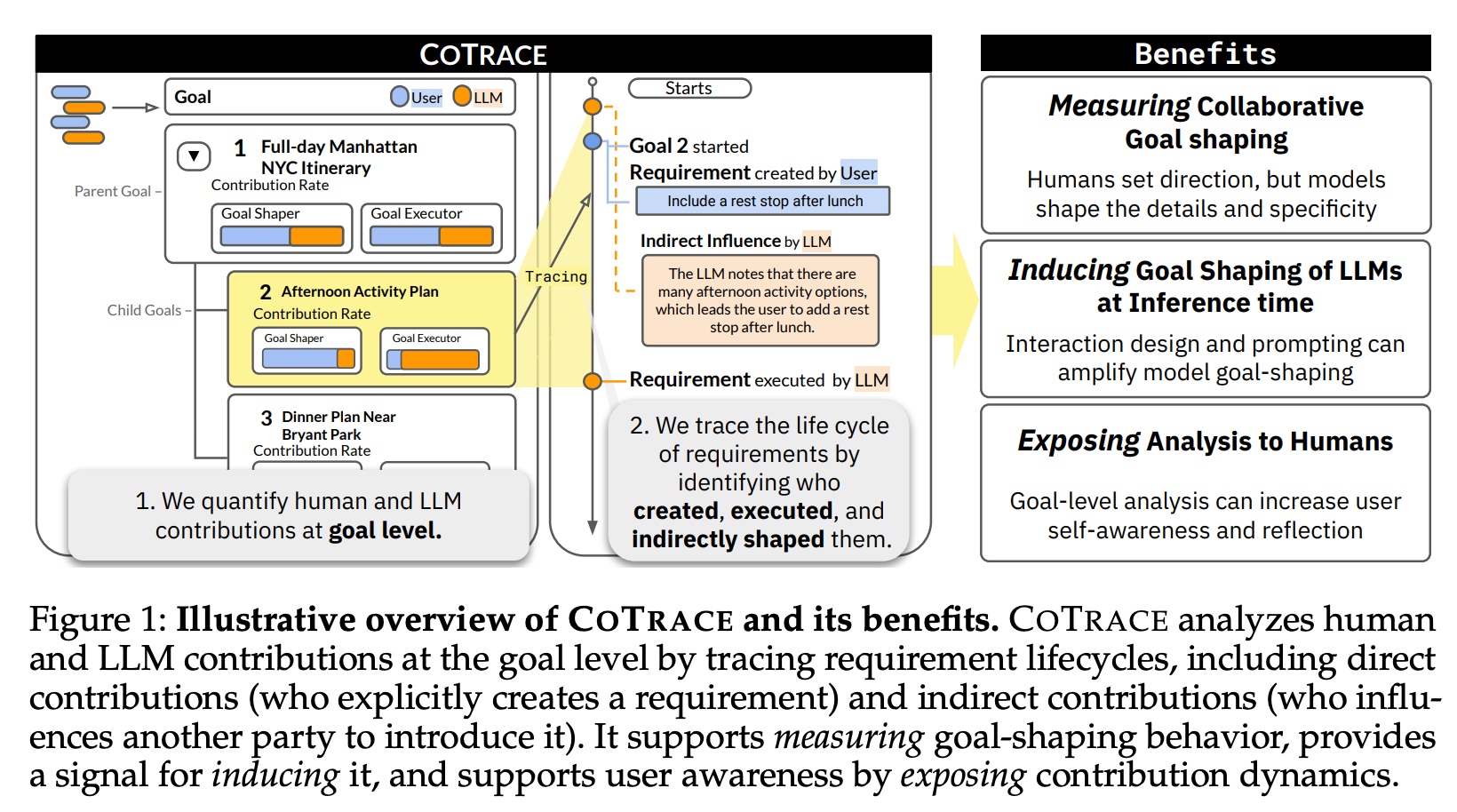
“We build and open-source COTRACE-viewer, an interactive analytical tool that makes contribution dynamics legible. In a user study with 10 participants, we find that exposing participants to goal-level analysis shifts their perception of both their own and the AI’s contributions. Some reflected on changing their prompting practices, suggesting that the tool corrects miscalibrated perceptions and promotes more intentional collaboration with AI.”
Kim, E., Mindel, J. R., Kim, K., & Wu, S. T. (2026). " I didn't Make the Micro Decisions": Measuring, Inducing, and Exposing Goal-Level AI Contributions in Collaboration. arXiv preprint arXiv:2605.21363.
https://arxiv.org/pdf/2605.21363
Preference For Explainable AI
Turns out incentives affect willful ignorance too
“Participants acted as loan officers deciding whether to approve real $10,000-loans issued by a private U.S. lender using an AI’s default-risk predictions. When explanations revealed that the AI penalized non-White or female borrowers, participants were more likely to override the AI’s profit- maximizing recommendation. When their bonuses depended on repayment, however, they sought predictions but avoided explanations, consistent with willful ignorance; this effect faded when explanations were framed as purely financial or demographics were hidden. A secondary experiment reveals a novel bias: participants failed to reason contingently and undervalued explanations even when these complemented private information and improved decision accuracy.”

“These findings have sharp implications for AI governance. Regulations mandating explainability—such as the EU AI Act or the U.S. Equal Credit Opportunity Act—may constrain the use of complex black-box models, but they also counteract self-serving incentives by collapsing moral wiggle room. Consumer finance regulators might consider policies where any algorithm used in lending must not only be explainable but that loan officers must review an explanation for any declined minority applicant. At the same time, policy mandates can serve as implicit subsidies for explanation, correcting behavioral undervaluation when individuals fail to appreciate complementarities with private signals. Besides, firms could offer training modules or simple real-time decision aids (while accounting for time costs and information overload) to help employees interpret AI explanations – since the experiment showed a short tutorial can significantly change usage and presumably improve decisions. Explainability should therefore be viewed not only as a technical attribute of models but also as an economic good, with demand shaped by incentives, beliefs, and cognitive constraints.”
Chan, A. (2026). Preference for Explainable AI (No. w35240). National Bureau of Economic Research.
http://www.nber.org/papers/w35240
Do Transformers Need Three Projections? Systematic Study of QKV Variants
They exhausted the possibilities
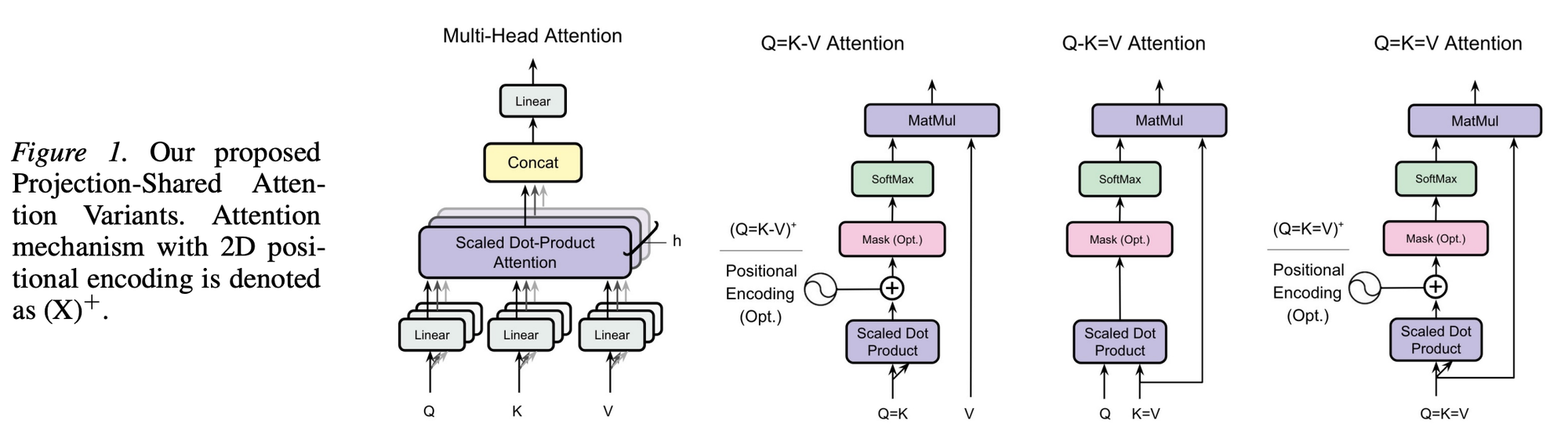
“We evaluated self-attention with reduced projections, with and without 2D positional encoding, against standard QKV attention across 12 tasks. Our goal was not state-of-the-art performance, but to assess performance differences between the proposed and original QKV Transformers. A comprehensive summary of all variants is provided in Appendix A.4, Table 13. Across synthetic, vision, and language domains, this systematic comparison reveals several key findings. K=V projection is effective and scalable. Q-K=V achieves 50% cache reduction with 2.48% degradation at 1.2B scale (vs 3.1% at 300M), offering an efficiency-quality trade-off that is orthogonal to and stackable with head sharing. Why Q-K=V works. Two complementary readings explain the small quality cost of K=V. The first is that V’s role is less essential than commonly assumed (He & Hofmann, 2024); the second is that K is rich enough to absorb V’s role—when the K=V constraint is imposed during training, the shared projection successfully serves both addressing and content functions.”
Kayyam, A., Gopal, A. M., & Lewis, M. A. (2026). Do Transformers Need Three Projections? Systematic Study of QKV Variants. arXiv preprint arXiv:2606.04032.
https://arxiv.org/pdf/2606.04032
SEGA: Spectral-Energy Guided Attention for Resolution Extrapolation in Diffusion Transformers
Frequency of frequencies
“In this work, we focus on direct-inference methods for resolution extrapolation in DiTs and address a fundamental failure mode related to positional encoding. When extrapolating pre-trained DiTs to high-resolution synthesis, the relative positional offsets in Rotary Position Embeddings (RoPE) [21] deviate significantly from those observed at training time, causing the attention weights to become overly diluted across the expanded token grid. This weakens spatial discrimination in attention and leads to degraded outputs such as blurred textures, repetitive patterns, and structural breakdowns. To counter this, previous approaches, adapted from long context language modeling, combine RoPE extrapolation with a uniform attention scaling to restore spatial focus [22].”

Rajabi, J., Shaban, K., Roohi, K., Lindell, D. B., & Taati, B. (2026). SEGA: Spectral-Energy Guided Attention for Resolution Extrapolation in Diffusion Transformers. arXiv preprint arXiv:2605.22668.
https://arxiv.org/abs/2605.22668
AI Isn't Management. Try Explaining That to Matthew Prince
Don’t eliminate the middle managers!
“Last Saturday, Matthew Prince, the CEO of Cloudflare wrote a self-congratulatory op-ed in the Wall Street Journal, suggesting his company was the only one in recorded business history to grow by 30% while laying off more than 20% of its employees. His message was that everyone needed to follow his example, by using AI to implement the True Wisdom of Revered Management Guru Peter Drucker.”
“If Druckerism is in part Schumpeterianism-lite, it is Schumpeterianism-lite nearly all the way down, focusing on cultivating initiative and self-actualization all the way through the rank-and-file of the firm.”
“The obvious risk of identifying large groups of managers as mere “measurers,” and replacing them with AI, is that you later discover that they were doing a whole lot of irreplaceable tasks of judgment too, balancing across the different and complicated choices that Drucker, like Simon and his colleagues, identifies as crucial to managing. AI will certainly supplement measurement, and might usefully substitute for many aspects of it, if carefully implemented. However, it cannot reliably substitute for managerial judgment as Drucker describes it.”
https://www.programmablemutter.com/p/ai-isnt-management-try-explaining
Predictive Data Debugging: Reveal and Shape What Your Model Learns, Before You Train
You are what you think
“Your model is what you put into it: data sets the ceiling on what it can achieve, and everything downstream — architecture, hyperparameters, more compute — just decides how close to that ceiling you get.”
“Given a preference dataset, we can predict which behaviors DPO will amplify or suppress before you train. This prediction holds up at R² = 0.9 against what the model actually learns, and can be tracked back to the data responsible for each behaviour. Armed with that information, we can reshape the dataset and/or training process to prevent undesired effects of post-training on that data.”
https://www.goodfire.ai/research/predictive-data-debugging#
Reader Feedback
“It makes sense that an intelligent system explores. Play is a big part of growing up.”
Footnotes
Fear, like all emotions, I assume, is compressed data.
To analyze what we fear, we have to transform that data into something readable. The more machine readable that data is, the better. Because then we can use the transistor, in association with the transformer, to unpack that fear.
We study what we fear by understanding both our fear and then the artifact that induced it.
Never miss a single issue
Be the first to know. Subscribe now to get the gatodo newsletter delivered straight to your inbox https://www.gatodo.com/#/portal/signup