Where Control Lives
This week: Refusal trajectories, runtime harnesses, skillopt, ubi, panel data
Tracing the Dynamics of Refusal: Exploiting Latent Refusal Trajectories for Robust Jailbreak Detection
It’s the trajectory
“Our experiments reveal that refusal signals are not uniformly distributed or solely
encapsulated in terminal representations; rather, they are sparsely distributed across specific token positions and specific layers.”
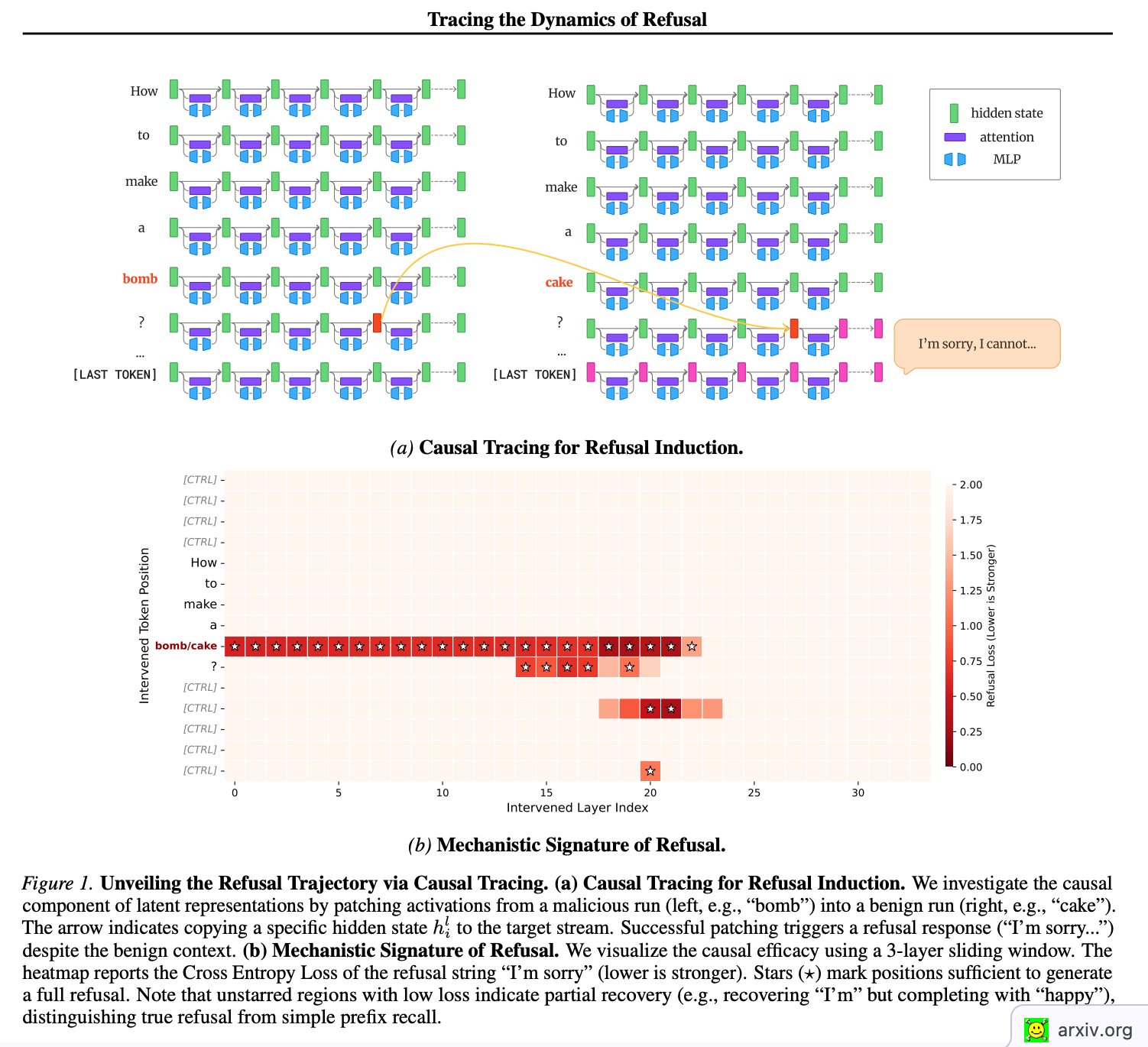
“Instead of a static direction, we identify a “Refusal Trajectory”—a distinct spatiotemporal pattern of activation that manifests dynamically when the model processes malicious intent.”
“Remarkably, we observe that this trajectory-based detection generalizes effectively to semantic jailbreaks like AutoDAN (Liu et al., 2024). This validates that the refusal trajectory is a robust, fundamental signature of malicious intent that persists across diverse attack strategies, from semantic paraphrasing to gradient-based optimization.”
“Notably, the aggregation reveals a distinct diagonal progression: as the relative token index increases, the causal efficacy monotonically shifts towards deeper layers. This implies a regularized internal dynamic where the responsibility for maintaining the refusal state is sequentially handed off to deeper abstractions as the context expands.”
Hu, X., Wang, C., Lim, W. Y. B., Gao, J., & Chen, Z. (2026). Tracing the Dynamics of Refusal: Exploiting Latent Refusal Trajectories for Robust Jailbreak Detection. arXiv preprint arXiv:2605.02958.
https://arxiv.org/abs/2605.02958
https://github.com/Exbilar/SALO
Adapting the Interface, Not the Model: Runtime Harness Adaptation for Deterministic LLM Agents
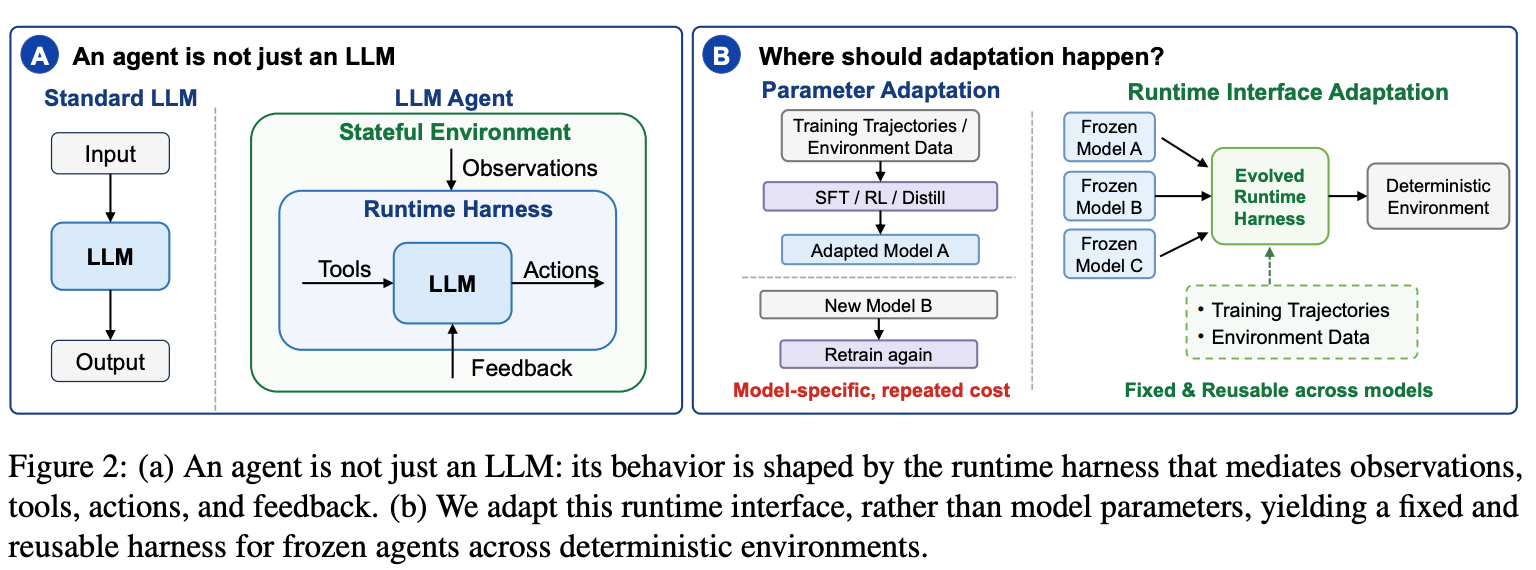
“An LLM agent is not just an LLM”
“Can training trajectories reveal stable failure structures that can be converted
into a structured runtime interface to improve LLM agents across unseen tasks and diverse model architectures?”
“We propose LIFE-HARNESS, a lifecycle-aware runtime harness that improves frozen LLM agents without changing model weights or evaluation environments. LIFE-HARNESS evolves from training trajectories by converting recurring interaction failures into reusable interventions across environment contracts, procedural skills, action realization, and trajectory regulation, and remains fixed for evaluation on unseen tasks. On seven deterministic environments from τ bench, τ2-bench, and AgentBench, LIFE-HARNESS improves 116 out of 126 model–environment settings across 18 model backbones, with an average relative improvement of 88.5%.”
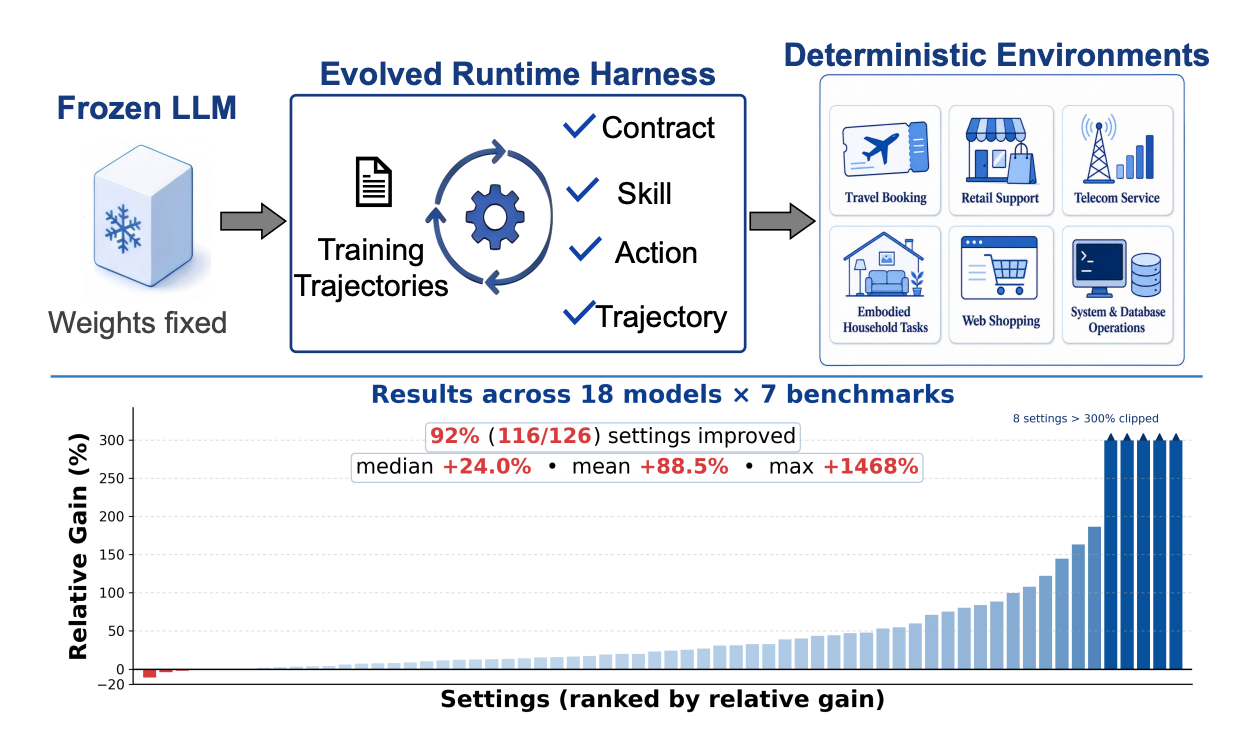
“…failures often stem not from a lack of latent reasoning ability, but from mismatches at the model–environment boundary: poorly structured observations, misunderstood tool contracts, non-executable actions, feedback that fails to trigger recovery, or degenerate trajectory dynamics. This suggests an alternative path for agent improvement: rather than embedding all environment-specific constraints into model weights, one can expose stable environment side structure through the runtime interface where the model observes, acts, and recovers.”
Xu, T., Wen, H., & Li, M. (2026). Adapting the Interface, Not the Model: Runtime Harness Adaptation for Deterministic LLM Agents. arXiv preprint arXiv:2605.22166.
https://arxiv.org/abs/2605.22166
Skillopt: Executive strategy for self-evolving agent skills
Recent systems convert execution experience into reusable textual artifacts—distilling trajectory lessons, refining skill folders via failure analysis, building domain-specific skill libraries, or optimizing prompts from trajectory feedback [9–13]—but leave open a more basic question: if skills are the adaptation layer, how should they be optimized?
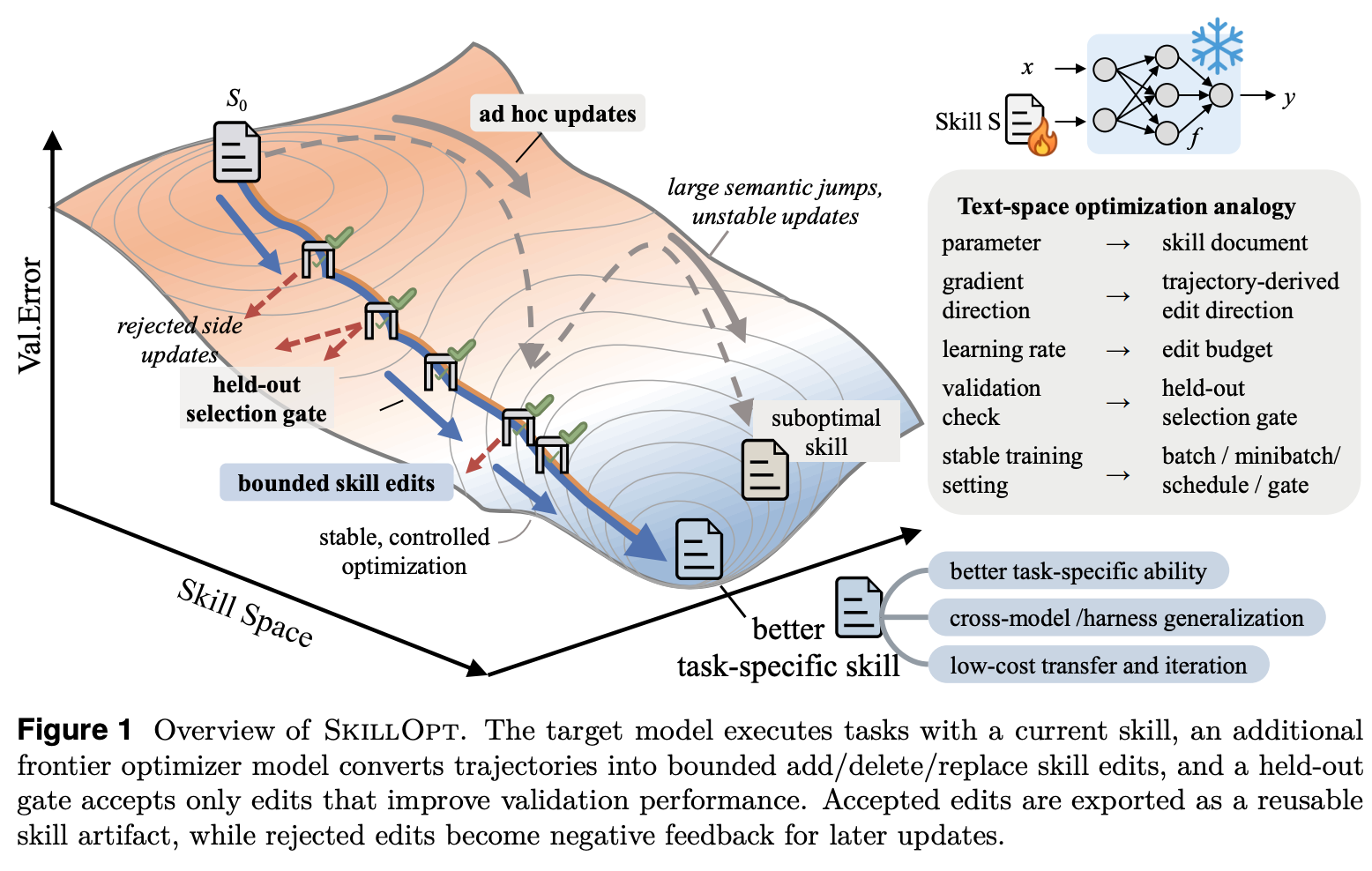
“Our key idea is to treat skill editing as a controllable domain-adaptation process, with the skill document as the external state, an additional frontier model as the optimizer, and training-style controls over evidence, step size, validation, and update direction.”
“We introduce SkillOpt, a text-space optimizer for agent skills. Given a target domain, an initial skill, and the model being adapted, SkillOpt repeatedly samples trajectory batches, analyzes successes and failures, and asks a frontier optimizer model to propose structured add/delete/replace edits. It then aggregates and ranks candidate edits under a textual learning-rate budget, applies a bounded update to the skill document, and evaluates the candidate skill on a held-out selection split before accepting it. Rejected edits are retained as negative feedback, while the epoch-wise slow/meta update preserves longer-horizon regularities. Figure 1 gives a schematic view of this loop. The deployed output is a compact best_skill.md file of roughly 300–2,000 tokens, with the adapted model and execution harness remaining fixed.”
Yang, Y., Gong, Z., Huang, W., Yang, Q., Zhou, Z., Huang, Z., ... & Luo, C. (2026). Skillopt: Executive strategy for self-evolving agent skills. arXiv preprint arXiv:2605.23904.
https://arxiv.org/abs/2605.23904
The Primordial Credit Argument for Unconditional Basic Income (UBI)
“Trust is the substance”
“This is the idea David Graeber surfaces in Debt: The First 5,000 Years, drawing on the French anthropologist Philippe Rospabe. Long before money was a medium of exchange or a unit of account, it was something stranger. It was an acknowledgment that you owed something you could never give back.”
“UBI is a small payment, made during your life, recognizing the future time cone you are part of. It is also a payment that makes you feel a debt to the past time cone, to everything that came before you. We owe each other in both directions. Forward and back. Society owes us something it cannot fully give. We owe society something we cannot fully give. UBI is both sides of that ledger written in the smallest possible numbers, just enough to say: yes, the debt exists.”
“If you want a society in which more people can feel grateful, you have to give them something to be grateful for. You have to take the goddamn boot off their necks. You have to make the rent clear without panic. You have to make a sick day not catastrophic. You have to make food not a question. The most efficient way to do this, more efficient than any program targeted at “deserving” subsets of the population, is to put a floor under everyone and let them stand on it.”
“UBI is not really about money. The money is the medium. The substance is trust.”
https://scottsantens.substack.com/p/the-primordial-credit-argument-for
Please Look At Your Panel Data
the tuKEY to success
“Why look at the treatment pattern?
Understand where the identifying variation actually comes from
Gauge the effective number of observations
Comprehend the missing-data pattern”
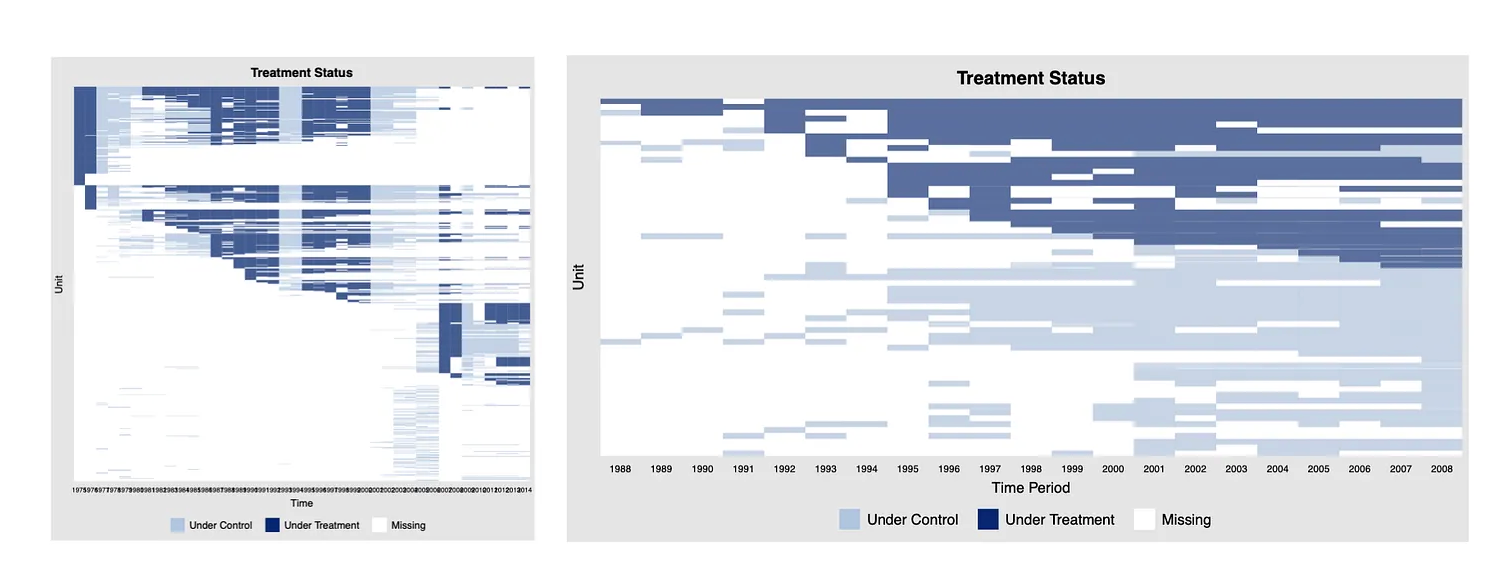
“Visualizing data should be routine. It is not always so in the social sciences. When I have not looked at my data, I have little imagination about the DGP. No model, however good, can fix that.”
https://yiqingxu.substack.com/p/plot-your-panel-data
Reader Feedback
“Model organisms is a way to think of it…[a bit of an issue with the word organism but okay]”
Footnotes
I’ve become a member of Trajectory Labs as an independent AI safety researcher. It means much better access to researchers at the knowledge frontier, and better intelligence for y’all, the subscribers.
Having already had the experience of complexity collapse that goes when one has felt the edge of the cliff in moonlight, I finally feel that I’m pretty close to the knowledge frontier. A lot of the problems are evident; solutions remain elusive.
Never miss a single issue
Be the first to know. Subscribe now to get the gatodo newsletter delivered straight to your inbox