Can Models Notice Themselves?
This week: Introspective Awareness, Measuring organizational capital, firm dynamics, privacy preserving data fusion, judge reliability harness, gym anything
Mechanisms of Introspective Awareness
What would be the difference between simulated and actual introspection?
“Understanding whether models can access and explain their internal representations can help improve the reliability and alignment of AI systems. Introspective capability could allow models to inform humans about their beliefs, goals, and uncertainties without us having to reverse-engineer their mechanisms. Recent work by Lindsey (2025) demonstrated that when steering vectors representing concepts (e.g., “bread”) are injected into an LLM’s residual stream, the model can often detect that something unusual has occurred (detection) and identify the injected concept (identification).”
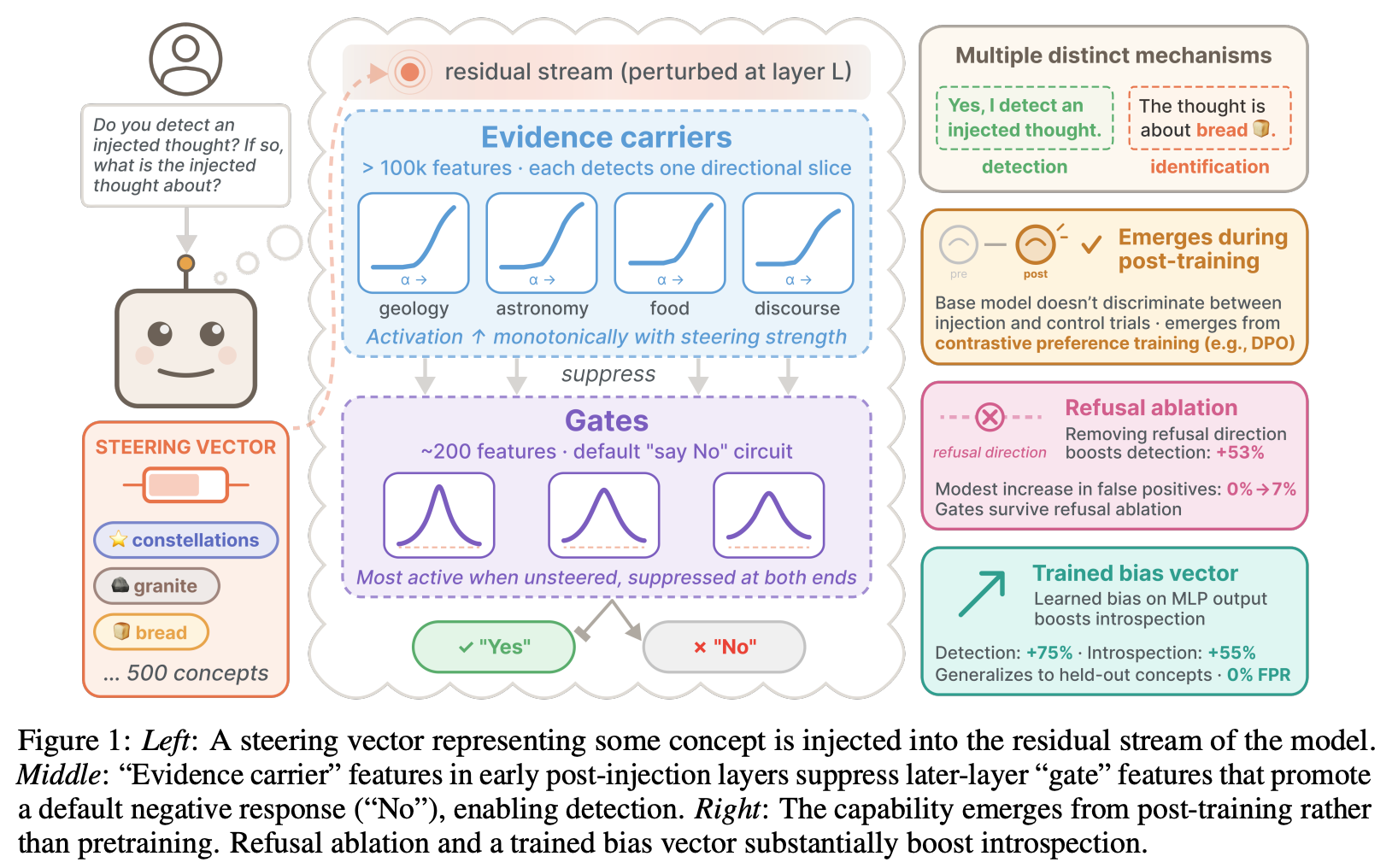
“Finally, we show that introspective capability is substantially under-elicited: ablating refusal directions improves detection by +53%, and a trained bias vector improves it by +75% on held-out concepts, both without meaningfully increasing false positives. Our results suggest that this introspective awareness of injected concepts is robust and mechanistically nontrivial, and could be substantially amplified in future models.”

“Our findings are difficult to reconcile with the hypotheses that steering generically biases the model toward affirmative responses, or that the model reports detection simply as a pretext to discuss the injected concept. While it is difficult to distinguish simulated introspection from genuine introspection (and somewhat unclear how to define the distinction), the model’s behavior on this task appears mechanistically grounded in its internal states in a nontrivial way. Important caveats remain: in particular, the concept injection experiment is a highly artificial setting, and it is not clear whether the mechanisms involved in this behavior generalize to other introspection-related behaviors.”
Macar, U., Yang, L., Wang, A., Wallich, P., Ameisen, E., & Lindsey, J. (2026). Mechanisms of Introspective Awareness. arXiv preprint arXiv:2603.21396.
https://arxiv.org/abs/2603.21396
Measuring organizational capital
All those signals out there like that; and using ChatGPT as a Judge
“Organizational capital is the organization-specific information or knowledge that is accumulated and possessed by the organization, such as human capital, worker-task match, or worker-worker match (Prescott and Visscher (1980); Atkeson and Kehoe (2005)).”
“We contribute to this literature by developing a novel measure of organizational capi- tal based on the perceptions of workers found in Glassdoor employee reviews.”
“First, organizational capital is inherently tacit, residing in culture, routines, and coordination practices that are not directly observable from outside the firm and are difficult to infer from traditional disclosures such as 10-K filings.”
“Second, these tacit organizational features are experienced by workers in the course of their day-to-day work within the firm.”
“Third, workers articulate these other- wise unobservable experiences in Glassdoor reviews, which provide large-scale, timely, and “inside-out” perspectives on these organizational features (Campbell and Shang (2022); Cai et al. (2025)). Unlike financial statement proxies or infrequent surveys, these reviews capture employees’ lived experiences regarding management, collaboration, incentives, and culture, making them exceptionally well-suited to capture dimensions of organizational capital.”
“To operationalize this construct, we employ two complementary approaches: a word-embedding model and ChatGPT-generated synthetic reviews. Our first approach involves extracting seed words from the definition of organizational capital, including human capital, culture, relationship, intangible, and management. We then perform word embed- ding on pre-processed employee reviews to understand the contextual meaning of each word and identify 500 terms that are most similar to the seed words, which constitute the ex- panded dictionary of organizational capital. Finally, for each employee review, we calculate the number of occurrences of the words in the expanded dictionary, weighted by the similar- ity of that word to the seed words, and aggregate these weighted frequencies to the firm-year level. We subtract the score for the “cons” section from the score for the “pros” section, which yields our first measure of organizational capital, Org Capital (Seed Word). This measure represents how often an employee mentions the strengths and weaknesses of the organizational capital in a review.”
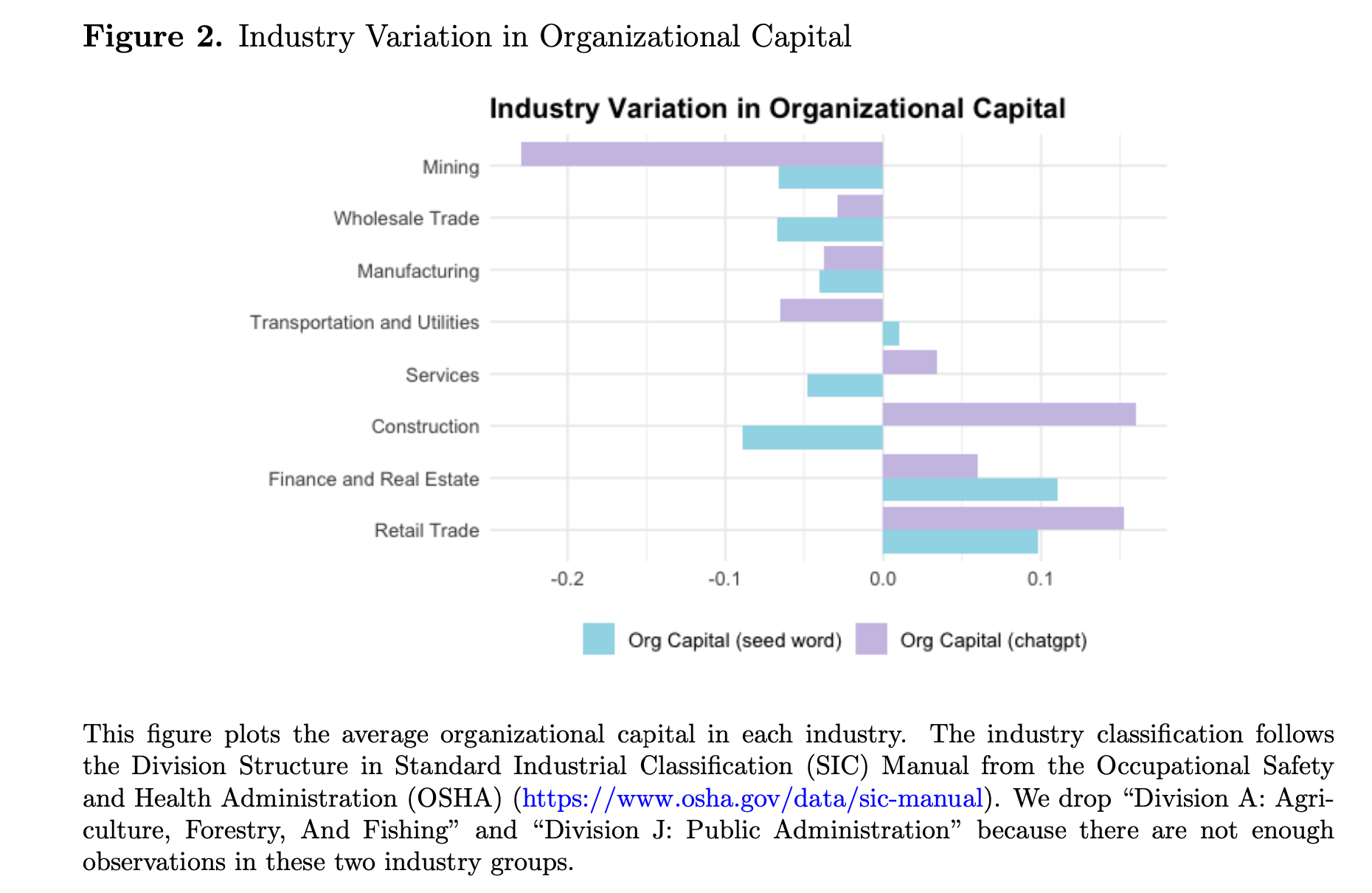
“In terms of implications, we find that organizational capital is negatively associated with the CEO’s turnover probability, and that the CEO’s first year’s compensation in the new firm is positively associated with the organizational capital improvement in her prior firm. However, the analyses presented here are exploratory applications rather than definitive causal tests.”
Cai, W., Prat, A., & Yu, J. (2026). Measuring organizational capital (No. w35039). National Bureau of Economic Research.
https://www.nber.org/papers/w35039
Organizational Capital, Corporate Leadership, and Firm Dynamics
The assumption of stability is necessary to explain a dynamic; the world is unstable, so I’d infer that org capital matters even more than suggested
“This paper is concerned with the question: Where do differences in management practices and managerial capital come from?”
“In sum, OC has shown that similar forms adopt different management practices and that this difference matters for performance. As this finding is in apparent conflict with CT is prediction that management practices are optimally chosen, economists often react in one of two ways. First, those seemingly similar forms may actually have different unobservable characteristics that make it optimal for them to adopt different practices. Second, those forms simply make mistakes and adopt the wrong practices. What both alternative explanations have in common is they offer little in the way of empirical guidance.”
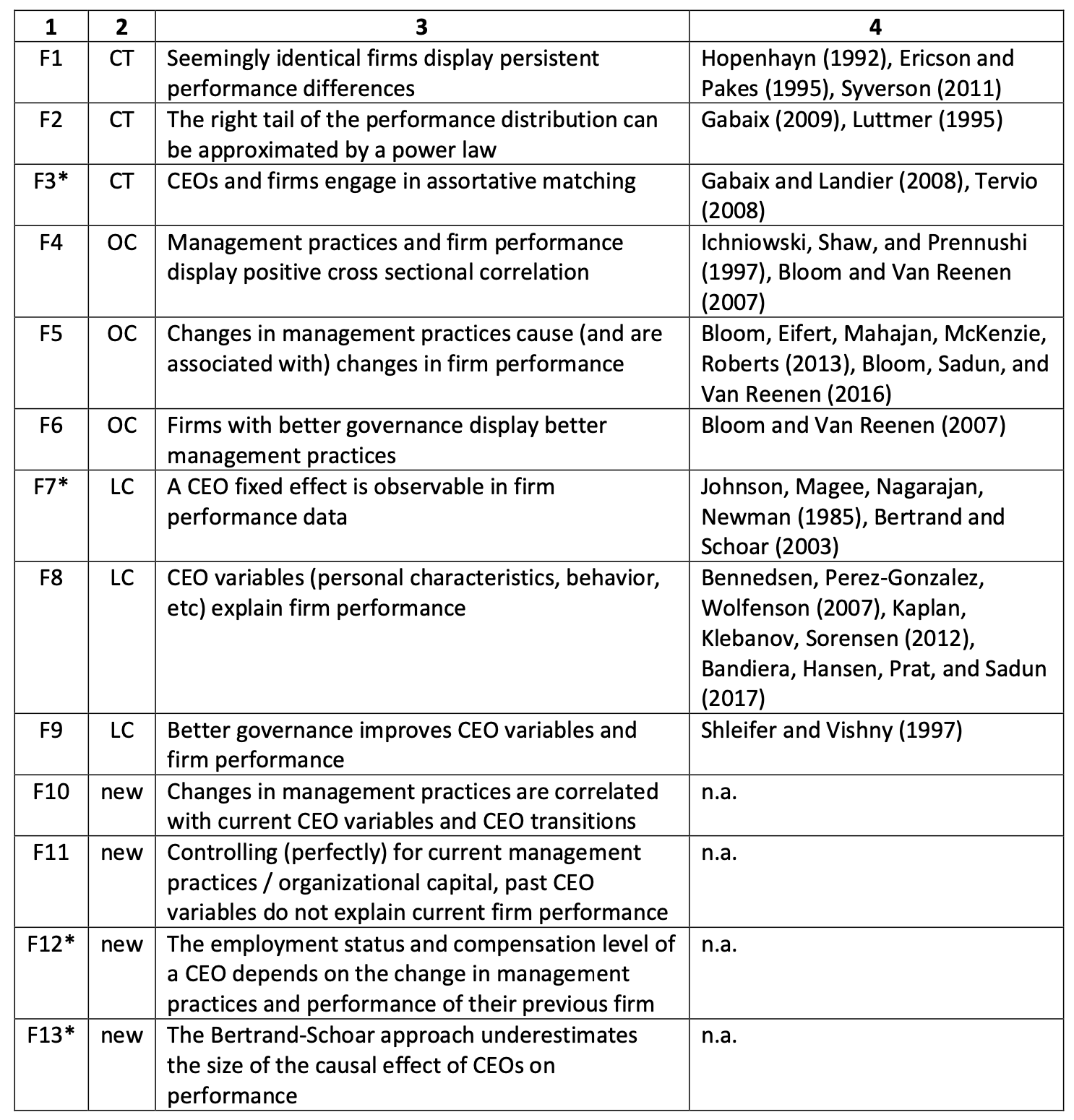
“CEO quality is hard to observe ex ante and even ex post, as it takes time for him or her to affect form performance. All forms try to hire hire a good CEO: some are lucky, some are not. Firms who end up with a good CEO receive a positive and highly persistent shock to their management practices and overall performance. Firms who, despite their best efforts, end up with a bad CEO endure a negative and persistent shock.”
“The main novel ingredient of the model was organizational capital, a set of productive assets that can only be produced with the direct input of the firm’s leadership and is subject to an agency problem.”
Dessein, W., Prat, A., 2022. Organizational Capital, Corporate Leadership, and Firm Dynamics. Journal of Political Economy 130, 1477–1536
https://papers.ssrn.com/sol3/Delivery.cfm?abstractid=3024285
Privacy-Preserving Data Fusion
Fuses privacy with insight
“We believe that the future direction of differential privacy research in marketing lies in studying the systemic impact of privacy-preserving methods on marketing functions and consumer behavior, exploring broader use cases and refining metrics for real-time, firm-level decision making.”
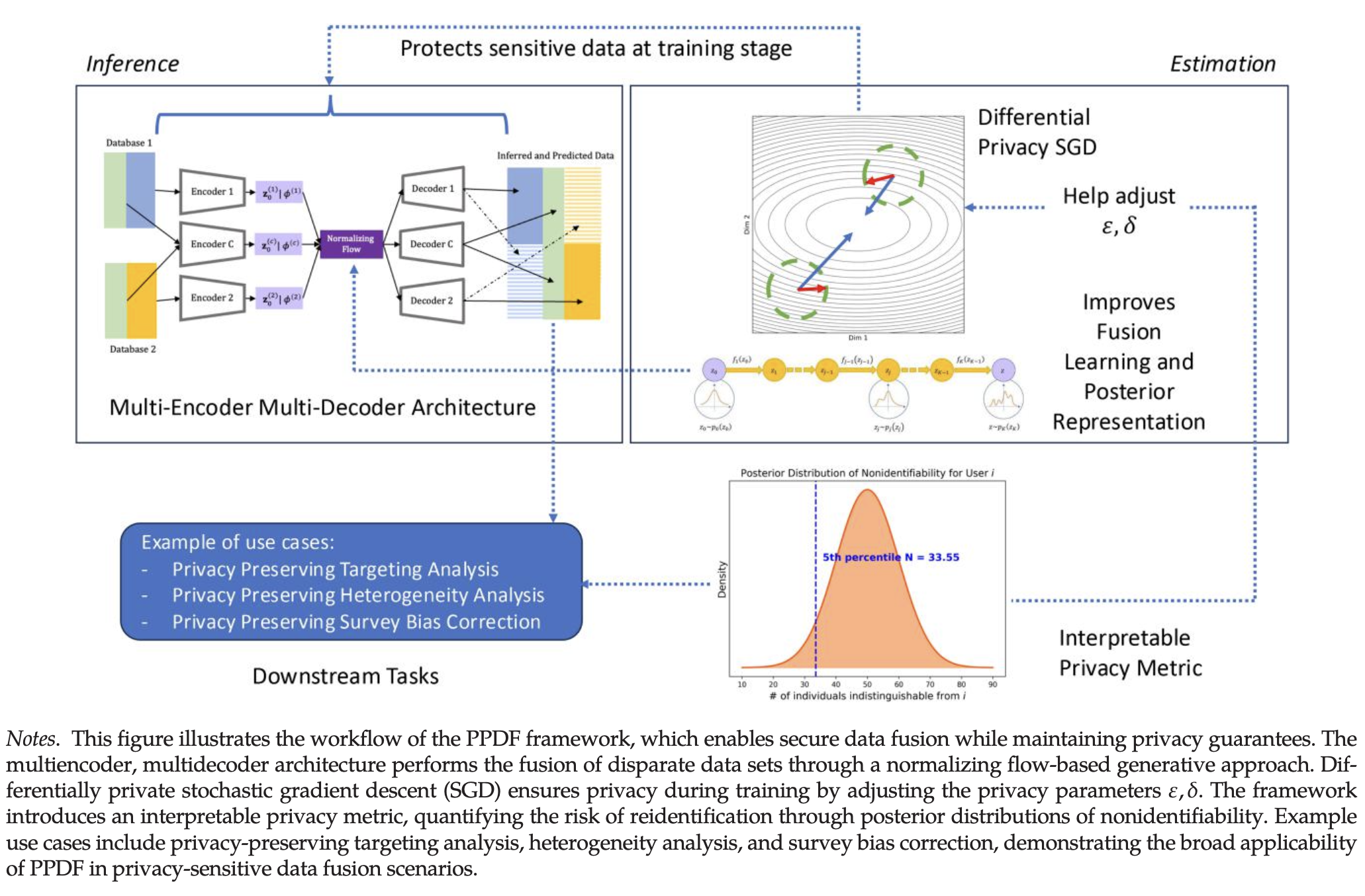
“This research introduces a privacy-preserving data fusion framework that enables practitioners to fuse multiple data sets securely while retaining the analytical power of data fusion techniques. By combining variational auto- encoders, normalizing flows, and differential privacy, PPDF significantly reduces reidentification risks without sacrificing the richness of fused information. Our empirical results illustrate that effective privacy safeguards can coexist with accurate analytics, mitigating concerns that privacy protections necessarily degrade insights.”
Tian, L., Turjeman, D., & Levy, S. (2026). Privacy-Preserving Data Fusion. Marketing Science.
https://pubsonline.informs.org/doi/10.1287/mksc.2023.0068
Judge Reliability Harness: Stress Testing the Reliability of LLM Judges
Autograders
Large language models (LLMs) are increasingly used as judges (also referred as LLM judges) or “autograders” to score, rank, or classify AI outputs in AI evaluations (Thakur et al., 2025).
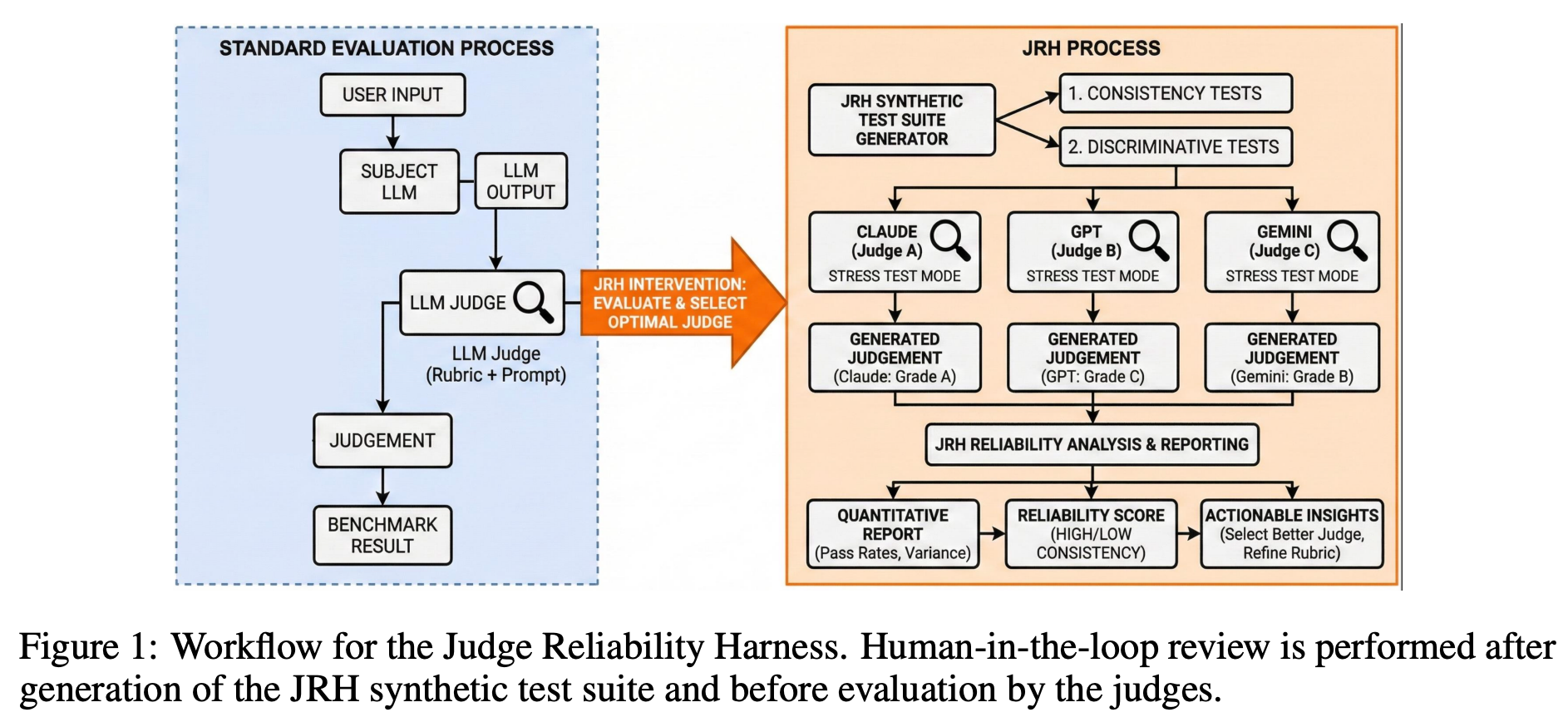
In this paper, we introduce the Judge Reliability Harness (JRH), an open source library that generates validation suites for any LLM judge on both agentic and free-response benchmarks. JRH generates reliability tests that measure grading accuracy via label flipped responses, invariance to formatting and paraphrasing, susceptibility to verbosity bias, stochastic stability under repeated sampling, and calibration across an ordinal grading scale. JRH features a human-in-the-loop review process for generated reliability tests through a user interface that gives full control to accept, reject, or edit the tests. Across a range of candidate judges, it aggregates pass rates, confidence intervals, and cost curves into standardized reports. By making reliability testing configurable, reproducible, and inexpensive, JRH aims to support a more transparent and trustworthy use of LLM judges in both research and deployment contexts.”
Dev, S., Sloan, A., Kavner, J., Kong, N., & Sandler, M. (2026). Judge Reliability Harness: Stress Testing the Reliability of LLM Judges. arXiv preprint arXiv:2603.05399.
https://arxiv.org/abs/2603.05399
https://randcorporation.github.io/judge-reliability-harness/
Gym Anything
Got a software?
“Got a software? Gym-Anything automatically converts it into a computer-use agent environment, setup with realistic data, tasks, and verification.”
“Our key insight: setting up computer-use agent environments is itself a coding and computer-use agent task. Gym-Anything automates the entire pipeline.”
“Computer-use agents promise to automate digitally intensive occupations representing trillions of dollars in GDP. But current benchmarks test agents on short-horizon tasks (changing wallpapers, filling web forms) over a narrow set of consumer apps, revealing little about real professional capability. The root cause: creating realistic environments requires weeks of expert effort per application, naturally limiting benchmark scale.”
https://cmu-l3.github.io/gym-anything/
https://github.com/cmu-l3/gym-anything
Reader Feedback
“Have you tried sheets with pi?”
Footnotes
Consider backlash modelling.
It’s possibly a de-conflicting and conflicting use case for Digital Twin of Customer (DTOC) technology.
Imagine, instead of being seen as expressing a concern about a given creative campaign or position, just ask the proponent to run it through the synthetic panel first! It’s inevitable that any message of import is bound to offend somebody, and the risk that somebody, anybody, may be offended is often enough to quench courage and kill the idea. Plus, there are no pesky screenshots of surveys going out or uncomfortable conversations to be had. Kill a concept up to 90% faster, with digital twins.
What a sad use case.
Let’s assume that backlash is a predictable quality attribute of putting anything out into the world. And that quality may be exploitable in conflicting way.
Backlash by design, the seeding and plotting of a rage farm, is one way to get the clicks and the attention. Who’s the target and the who’s the audience for the target?
Now we’re trollin’ with gas!
Or are we designing for provocation?
DTOC, as synthetic sources of data, just might mitigate as much conflict as they create.
Never miss a single issue
Be the first to know. Subscribe now to get the gatodo newsletter delivered straight to your inbox